






使用unet/DeepLabV3+对汽车道路分割检测数据集 道路分割 9000张 json coco 道路语义分割数据集 道路分割数据集 道路语义分割数据集 语义分割检测数据集 26类9000张
也可以用作目标检测 yolo算法
以下文字及代码仅供参考。学习。

目标类别:
person:行人
auto_rickshaw:三轮车
three_wheeler:三轮车
motorbike:摩托车
road:道路
road_divider:道路分隔线
pole:杆
bicycle:自行车
car:汽车
truck:卡车
bus:公交车
construction_vehicle:施工车辆
priority_vehicle:优先车辆
cart_vehicle:手推车
building:建筑物
vegetation:植被
road_sign:路标
wall:墙
sky:天空
over_bridge:高架桥
sidewalk:人行道
garbage_bin:垃圾桶
animal:动物
billboard:广告牌
traffic_light:交通信号灯
wheelchair:轮椅

针对你提供的汽车道路分割检测数据集,这是一个多类别语义分割任务,涉及26个不同的类别。为了高效地处理这种复杂的分割任务,选择一个强大的模型架构是关键。基于当前最先进的技术,我推荐使用 DeepLabV3+ 或者 U-Net++ 这样的模型,它们在语义分割任务中表现优异。此外,也可以考虑使用更高效的轻量级模型如 HRNet 或者 Fast-SCNN 如果部署环境对计算资源有限制。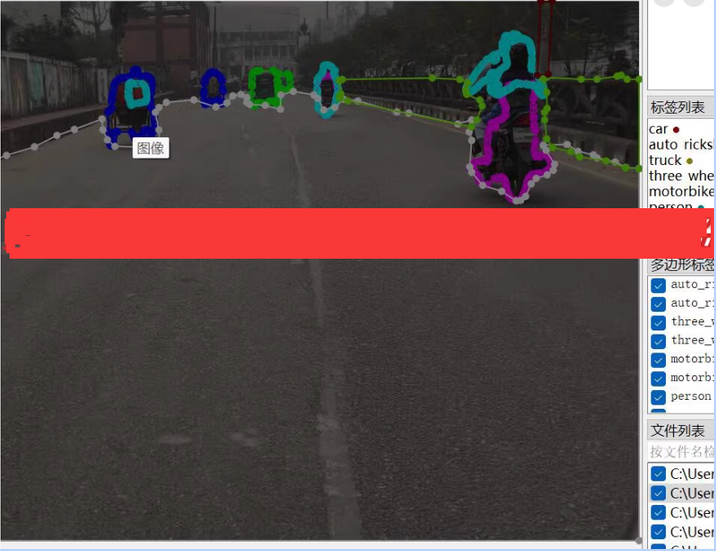
使用 Segmentation Models for PyTorch (smp) 库中的 DeepLabV3+ 模型进行训练的步骤示例:

1. 安装必要的依赖
首先确保安装了所有必要的库:
pip install torch torchvision scikit-learn segmentation-models-pytorch albumentations opencv-python

2. 数据准备与加载
数据是以 COCO 格式标注的 JSON 文件形式存在,需要将这些标注转换为适合模型输入的形式(比如像素级别的标签图像)。使用 pycocotools 来解析 COCO 标注文件,并将其转换成分割模型所需的格式。

作为参考的
例子来展示如何使用 pycocotools 和 albumentations 加载和增强数据:
import os
from torch.utils.data import Dataset, DataLoader
import cv2
import numpy as np
from pycocotools.coco import COCO
from albumentations import Compose, Normalize, ToTensorV2
class RoadSegmentationDataset(Dataset):
def __init__(self, image_dir, annotation_file, transform=None):
self.image_dir = image_dir
self.coco = COCO(annotation_file)
self.ids = list(sorted(self.coco.imgs.keys()))
self.transform = transform
def __getitem__(self, index):
coco = self.coco
img_id = self.ids[index]
ann_ids = coco.getAnnIds(imgIds=img_id)
anns = coco.loadAnns(ann_ids)
path = coco.loadImgs(img_id)[0]['file_name']
img = cv2.imread(os.path.join(self.image_dir, path), cv2.IMREAD_COLOR)
mask = np.zeros((img.shape[0], img.shape[1]))
for ann in anns:
mask[coco.annToMask(ann) == 1] = ann['category_id']
if self.transform is not None:
augmented = self.transform(image=img, mask=mask)
img = augmented['image']
mask = augmented['mask']
return img, mask.long()
def __len__(self):
return len(self.ids)
transform = Compose([
Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2(),
])
dataset = RoadSegmentationDataset(image_dir='path/to/images', annotation_file='path/to/annotations.json', transform=transform)
dataloader = DataLoader(dataset, batch_size=8, shuffle=True)
3. 模型定义
接下来定义并初始化模型:
import segmentation_models_pytorch as smp
ENCODER = 'resnet50'
ENCODER_WEIGHTS = 'imagenet'
CLASSES = ['person', 'auto_rickshaw', ... , 'wheelchair'] # 列出所有类别
ACTIVATION = 'softmax2d' # could be None for logits or 'softmax2d' for multiclass segmentation
# 创建模型
model = smp.DeepLabV3Plus(
encoder_name=ENCODER,
encoder_weights=ENCODER_WEIGHTS,
classes=len(CLASSES),
activation=ACTIVATION,
)
# 使用GPU加速
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(DEVICE)
4. 训练模型
定义损失函数、优化器等,并开始训练:
loss = smp.losses.DiceLoss(mode='multiclass')
optimizer = torch.optim.Adam([
dict(params=model.parameters(), lr=0.0001),
])
# 假设已有dataloaders变量包含train_loader和val_loader
for epoch in range(epochs):
model.train()
for images, masks in train_loader:
images, masks = images.to(DEVICE), masks.to(DEVICE)
optimizer.zero_grad()
outputs = model(images)
loss_value = loss(outputs, masks)
loss_value.backward()
optimizer.step()
# 在验证集上评估性能...
以上文字及代码仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









