






<span style="color:#98c379">'password'</span>: <span style="color:#98c379">'QQ邮箱授权码'</span>,
<span style="color:#98c379">'smtp_host'</span>: <span style="color:#98c379">'smtp.qq.com'</span>,
<span style="color:#98c379">'smtp_port'</span>: <span style="color:#d19a66">465</span>
}
<span style="color:#5c6370"><em># 收件人</em></span>
ADDRESSEE = [
<span style="color:#98c379">'1084502012@qq.com'</span>,
]
@property
def log_file(self):
“”“日志目录”“”
log_dir = os.path.join(self.BASE_DIR, ‘logs’)
if not os.path.exists(log_dir):
os.makedirs(log_dir)
return os.path.join(log_dir, ‘{}.log’.format(dt_strftime()))
@property
def ini_file(self):
“”“配置文件”“”
ini_file = os.path.join(self.BASE_DIR, ‘config’, ‘config.ini’)
if not os.path.exists(ini_file):
raise FileNotFoundError(“配置文件%s不存在!” % ini_file)
return ini_file
cm = ConfigManager()
if name == ‘main’:
print(cm.BASE_DIR)
>
> 注意:QQ邮箱授权码:[点击查看生成教程]( )
>
>
>
>
> 这个conf文件我模仿了Django的settings.py文件的设置风格,但是又有些许差异。
>
>
>
在这个文件中我们可以设置自己的各个目录,也可以查看自己当前的目录。
遵循了约定:不变的常量名全部大写,函数名小写。看起来整体美观。
#### **config.ini**
在项目`config`目录新建一个`config.ini`文件,里面暂时先放入我们的需要测试的URL
[HOST]
HOST = https://www.baidu.com
#### **读取配置文件**
配置文件创建好了,接下来我们需要读取这个配置文件以使用里面的信息。
我们在`common`目录中新建一个`readconfig.py`文件
#!/usr/bin/env python3
# -- coding:utf-8 --
import configparser
from config.conf import cm
HOST = ‘HOST’
class ReadConfig(object):
“”“配置文件”“”
<span style="color:#7171bf">def</span> <span style="color:#61aeee">__init__</span>(self):
self.config = configparser.RawConfigParser() <span style="color:#5c6370"><em># 当有%的符号时请使用Raw读取</em></span>
self.config.read(cm.ini_file, encoding=<span style="color:#98c379">'utf-8'</span>)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">_get</span>(self, section, option):
<span style="color:#98c379">"""获取"""</span>
<span style="color:#7171bf">return</span> self.config.get(section, option)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">_set</span>(self, section, option, value):
<span style="color:#98c379">"""更新"""</span>
self.config.<span style="color:#7171bf">set</span>(section, option, value)
<span style="color:#7171bf">with</span> <span style="color:#7171bf">open</span>(cm.ini_file, <span style="color:#98c379">'w'</span>) <span style="color:#7171bf">as</span> f:
self.config.write(f)
@property
def url(self):
return self._get(HOST, HOST)
ini = ReadConfig()
if name == ‘main’:
print(ini.url)
可以看到我们用python内置的configparser模块对`config.ini`文件进行了读取。
对于url值的提取,我使用了高阶语法`@property`属性值,写法更简单。
---
### **四、记录操作日志**
日志,大家应该都很熟悉这个名词,就是记录代码中的动作。
在`utils`目录中新建`logger.py`文件。
这个文件就是我们用来在自动化测试过程中记录一些操作步骤的。
#!/usr/bin/env python3
# -- coding:utf-8 --
import logging
from config.conf import cm
class Log:
def init(self):
self.logger = logging.getLogger()
if not self.logger.handlers:
self.logger.setLevel(logging.DEBUG)
<span style="color:#5c6370"><em># 创建一个handle写入文件</em></span>
fh = logging.FileHandler(cm.log_file, encoding=<span style="color:#98c379">'utf-8'</span>)
fh.setLevel(logging.INFO)
<span style="color:#5c6370"><em># 创建一个handle输出到控制台</em></span>
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
<span style="color:#5c6370"><em># 定义输出的格式</em></span>
formatter = logging.Formatter(self.fmt)
fh.setFormatter(formatter)
ch.setFormatter(formatter)
<span style="color:#5c6370"><em># 添加到handle</em></span>
self.logger.addHandler(fh)
self.logger.addHandler(ch)
@property
def fmt(self):
return ‘%(levelname)s\t%(asctime)s\t[%(filename)s:%(lineno)d]\t%(message)s’
log = Log().logger
if name == ‘main’:
log.info(‘hello world’)
在终端中运行该文件,就看到命令行打印出了:
INFO 2020-12-01 16:00:05,467 [logger.py:38] hello world
然后在项目logs目录下生成了当月的日志文件。
---
### **五、简单理解POM模型**
>
> 由于下面要讲元素相关的,所以首先理解一下POM模型
>
>
>
**Page Object模式具有以下几个优点。**
>
> 该观点来自 《Selenium自动化测试——基于Python语言》
>
>
>
* 抽象出对象可以最大程度地降低开发人员修改页面代码对测试的影响, 所以, 你仅需要对页
面对象进行调整, 而对测试没有影响;
* 可以在多个测试用例中复用一部分测试代码;
* 测试代码变得更易读、 灵活、 可维护
**Page Object模式图**
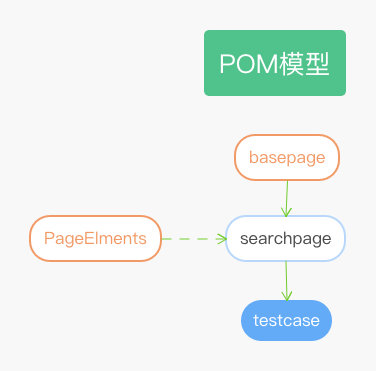
* basepage ——selenium的基类,对selenium的方法进行封装
* pageelements——页面元素,把页面元素单独提取出来,放入一个文件中
* searchpage ——页面对象类,把selenium方法和页面元素进行整合
* testcase ——使用pytest对整合的searchpage进行测试用例编写
通过上图我们可以看出,通过POM模型思想,我们把:
* selenium方法
* 页面元素
* 页面对象
* 测试用例
以上四种代码主体进行了拆分,虽然在用例很少的情况下做会增加代码,但是当用例多的时候意义很大,代码量会在用例增加的时候显著减少。我们维护代码变得更加直观明显,代码可读性也变得比工厂模式强很多,代码复用率也极大的得到了提高。
---
### **六、简单学习元素定位**
在日常的工作中,我见过很多在浏览器中直接在浏览器中右键`Copy Xpath`复制元素的同学。这样获得的元素表达式放在 webdriver 中去运行往往是不够稳定的,像前端的一些微小改动,都会引起元素无法定位的`NoSuchElementException`报错。
所以在实际工作和学习中我们应该加强自己的元素定位能力,尽可能的采用`xpath`和`CSS selector` 这种相对稳定的定位语法。由于`CSS selector`的语法生硬难懂,对新手很不友好,而且相比`xpath`缺少一些定位语法。所以我们选择`xpath`进行我们的元素定位语法。
**xpath[#]( )**
**语法规则**
>
> [菜鸟教程]( )中对于 xpath 的介绍是一门在 XML 文档中查找信息的语言。
>
>
>
| 表达式 | 介绍 | 备注 |
| --- | --- | --- |
| / | 根节点 | 绝对路径 |
| // | 当前节点的所有子节点 | 相对路径 |
| \* | 所有节点元素的 | |
| @ | 属性名的前缀 | @class @id |
| \*[1] | [] 下标运算符 | |
| [] | [ ]谓词表达式 | //input[@id='kw'] |
| Following-sibling | 当前节点之后的同级 | |
| preceding-sibling | 当前节点之前的同级 | |
| parent | 当前节点的父级节点 | |
**定位工具**
* chropath
+ 优点:这是一个Chrome浏览器的测试定位插件,类似于firepath,本人试用了一下整体感觉非常好。对小白的友好度很好。
+ 缺点:安装这个插件需要FQ。
* Katalon录制工具
+ 录制出来的脚本里面也会有定位元素的信息
* 自己写——本人推荐这种
+ 优点:本人推荐的方式,因为当熟练到一定程度的时候,写出来的会更直观简洁,并且在运行自动化测试中出现问题时,能快速定位。
+ 缺点:需要一定`xpath`和`CSS selector`语法积累,不太容易上手。
---
### **七、管理页面元素**
>
> 本教程选择的测试地址是百度首页,所以对应的元素也是百度首页的。
>
>
>
项目框架设计中有一个目录`page_element`就是专门来存放定位元素的文件的。
通过对各种配置文件的对比,我在这里选择的是YAML文件格式。其易读,交互性好。
我们在`page_element`中新建一个`search.yaml`文件。
搜索框: “idkw"
候选: "css.bdsug-overflow”
搜索候选: “css==#form div li”
搜索按钮: “id==su”
元素定位文件创建好了,下来我们需要读取这个文件。
在`common`目录中创建`readelement.py`文件。
#!/usr/bin/env python3
# -- coding:utf-8 --
import os
import yaml
from config.conf import cm
class Element(object):
“”“获取元素”“”
<span style="color:#7171bf">def</span> <span style="color:#61aeee">__init__</span>(self, name):
self.file_name = <span style="color:#98c379">'%s.yaml'</span> % name
self.element_path = os.path.join(cm.ELEMENT_PATH, self.file_name)
<span style="color:#7171bf">if</span> <span style="color:#7171bf">not</span> os.path.exists(self.element_path):
<span style="color:#7171bf">raise</span> FileNotFoundError(<span style="color:#98c379">"%s 文件不存在!"</span> % self.element_path)
<span style="color:#7171bf">with</span> <span style="color:#7171bf">open</span>(self.element_path, encoding=<span style="color:#98c379">'utf-8'</span>) <span style="color:#7171bf">as</span> f:
self.data = yaml.safe_load(f)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">__getitem__</span>(self, item):
<span style="color:#98c379">"""获取属性"""</span>
data = self.data.get(item)
<span style="color:#7171bf">if</span> data:
name, value = data.split(<span style="color:#98c379">'=='</span>)
<span style="color:#7171bf">return</span> name, value
<span style="color:#7171bf">raise</span> ArithmeticError(<span style="color:#98c379">"{}中不存在关键字:{}"</span>.<span style="color:#7171bf">format</span>(self.file_name, item))
if name == ‘main’:
search = Element(‘search’)
print(search[‘搜索框’])
通过特殊方法`__getitem__`实现调用任意属性,读取yaml中的值。
这样我们就实现了定位元素的存储和调用。
但是还有一个问题,我们怎么样才能确保我们写的每一项元素不出错,人为的错误是不可避免的,但是我们可以通过代码来运行对文件的审查。当前也不能所有问题都能发现。
所以我们编写一个文件,在`script`脚本文件目录中创建`inspect.py`文件,对所有的元素yaml文件进行审查。
#!/usr/bin/env python3
# -- coding:utf-8 --
import os
import yaml
from config.conf import cm
from utils.times import running_time
@running_time
def inspect_element():
“”“检查所有的元素是否正确
只能做一个简单的检查
“””
for files in os.listdir(cm.ELEMENT_PATH):
_path = os.path.join(cm.ELEMENT_PATH, files)
with open(_path, encoding=‘utf-8’) as f:
data = yaml.safe_load(f)
for k in data.values():
try:
pattern, value = k.split(‘==’)
except ValueError:
raise Exception(“元素表达式中没有==”)
if pattern not in cm.LOCATE_MODE:
raise Exception(‘%s中元素【%s】没有指定类型’ % (_path, k))
elif pattern == ‘xpath’:
assert ‘//’ in value,
‘%s中元素【%s】xpath类型与值不配’ % (_path, k)
elif pattern == ‘css’:
assert ‘//’ not in value,
‘%s中元素【%s]css类型与值不配’ % (_path, k)
else:
assert value, ‘%s中元素【%s】类型与值不匹配’ % (_path, k)
if name == ‘main’:
inspect_element()
执行该文件:
校验元素done!用时0.002秒!
可以看到,很短的时间内,我们就对所填写的YAML文件进行了审查。
现在我们基本所需要的组件已经大致完成了。
接下来我们将进行最重要的一环,封装selenium。
---
### **八、封装Selenium基类**
在工厂模式种我们是这样写的:
#!/usr/bin/env python3
# -- coding:utf-8 --
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(‘https://www.baidu.com’)
driver.find_element_by_xpath(“//input[@id=‘kw’]”).send_keys(‘selenium’)
driver.find_element_by_xpath(“//input[@id=‘su’]”).click()
time.sleep(5)
driver.quit()
很直白,简单,又明了。
**创建driver对象,打开百度网页,搜索selenium,点击搜索,然后停留5秒,查看结果,最后关闭浏览器。**
那我们为什么要封装selenium的方法呢。首先我们上述这种较为原始的方法,基本不适用于平时做UI自动化测试的,因为在UI界面实际运行情况远远比较复杂,可能因为网络原因,或者控件原因,我们元素还没有显示出来,就进行点击或者输入。所以我们需要封装selenium方法,通过内置的显式等待或一定的条件语句,才能构建一个稳定的方法。而且把selenium方法封装起来,有利于平时的代码维护。
我们在`page`目录创建`webpage.py`文件。
#!/usr/bin/env python3
# -- coding:utf-8 --
“”"
selenium基类
本文件存放了selenium基类的封装方法
“”"
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from config.conf import cm
from utils.times import sleep
from utils.logger import log
class WebPage(object):
“”“selenium基类”“”
<span style="color:#7171bf">def</span> <span style="color:#61aeee">__init__</span>(self, driver):
<span style="color:#5c6370"><em># self.driver = webdriver.Chrome()</em></span>
self.driver = driver
self.timeout = <span style="color:#d19a66">20</span>
self.wait = WebDriverWait(self.driver, self.timeout)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">get_url</span>(self, url):
<span style="color:#98c379">"""打开网址并验证"""</span>
self.driver.maximize_window()
self.driver.set_page_load_timeout(<span style="color:#d19a66">60</span>)
<span style="color:#7171bf">try</span>:
self.driver.get(url)
self.driver.implicitly_wait(<span style="color:#d19a66">10</span>)
log.info(<span style="color:#98c379">"打开网页:%s"</span> % url)
<span style="color:#7171bf">except</span> TimeoutException:
<span style="color:#7171bf">raise</span> TimeoutException(<span style="color:#98c379">"打开%s超时请检查网络或网址服务器"</span> % url)
@staticmethod
def element_locator(func, locator):
“”“元素定位器”“”
name, value = locator
return func(cm.LOCATE_MODE[name], value)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">find_element</span>(self, locator):
<span style="color:#98c379">"""寻找单个元素"""</span>
<span style="color:#7171bf">return</span> WebPage.element_locator(<span style="color:#7171bf">lambda</span> *args: self.wait.until(
EC.presence_of_element_located(args)), locator)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">find_elements</span>(self, locator):
<span style="color:#98c379">"""查找多个相同的元素"""</span>
<span style="color:#7171bf">return</span> WebPage.element_locator(<span style="color:#7171bf">lambda</span> *args: self.wait.until(
EC.presence_of_all_elements_located(args)), locator)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">elements_num</span>(self, locator):
<span style="color:#98c379">"""获取相同元素的个数"""</span>
number = <span style="color:#7171bf">len</span>(self.find_elements(locator))
log.info(<span style="color:#98c379">"相同元素:{}"</span>.<span style="color:#7171bf">format</span>((locator, number)))
<span style="color:#7171bf">return</span> number
<span style="color:#7171bf">def</span> <span style="color:#61aeee">input_text</span>(self, locator, txt):
<span style="color:#98c379">"""输入(输入前先清空)"""</span>
sleep(<span style="color:#d19a66">0.5</span>)
ele = self.find_element(locator)
ele.clear()
ele.send_keys(txt)
log.info(<span style="color:#98c379">"输入文本:{}"</span>.<span style="color:#7171bf">format</span>(txt))
<span style="color:#7171bf">def</span> <span style="color:#61aeee">is_click</span>(self, locator):
<span style="color:#98c379">"""点击"""</span>
self.find_element(locator).click()
sleep()
log.info(<span style="color:#98c379">"点击元素:{}"</span>.<span style="color:#7171bf">format</span>(locator))
<span style="color:#7171bf">def</span> <span style="color:#61aeee">element_text</span>(self, locator):
<span style="color:#98c379">"""获取当前的text"""</span>
_text = self.find_element(locator).text
log.info(<span style="color:#98c379">"获取文本:{}"</span>.<span style="color:#7171bf">format</span>(_text))
<span style="color:#7171bf">return</span> _text
@property
def get_source(self):
“”“获取页面源代码”“”
return self.driver.page_source
<span style="color:#7171bf">def</span> <span style="color:#61aeee">refresh</span>(self):
<span style="color:#98c379">"""刷新页面F5"""</span>
self.driver.refresh()
self.driver.implicitly_wait(<span style="color:#d19a66">30</span>)
在文件中我们对主要用了**`显式等待`**对selenium的click,send\_keys等方法,做了二次封装。提高了运行的成功率。
好了我们完成了POM模型的一半左右的内容。接下来我们们进入页面对象。
---
### **九、创建页面对象**
在`page_object`目录下创建一个`searchpage.py`文件。
#!/usr/bin/env python3
# -- coding:utf-8 --
from page.webpage import WebPage, sleep
from common.readelement import Element
search = Element(‘search’)
class SearchPage(WebPage):
“”“搜索类”“”
<span style="color:#7171bf">def</span> <span style="color:#61aeee">input_search</span>(self, content):
<span style="color:#98c379">"""输入搜索"""</span>
self.input_text(search[<span style="color:#98c379">'搜索框'</span>], txt=content)
sleep()
@property
def imagine(self):
“”“搜索联想”“”
return [x.text for x in self.find_elements(search[‘候选’])]
<span style="color:#7171bf">def</span> <span style="color:#61aeee">click_search</span>(self):
<span style="color:#98c379">"""点击搜索"""</span>
self.is_click(search[<span style="color:#98c379">'搜索按钮'</span>])
在该文件中我们对,输入搜索关键词,点击搜索,搜索联想,进行了封装。
并配置了注释。
>
> 在平时中我们应该养成写注释的习惯,因为过一段时间后,没有注释,代码读起来很费劲。
>
>
>
好了我们的页面对象此时业已完成了。下面我们开始编写测试用例。在开始测试用了之前我们先熟悉一下pytest测试框架。
---
### **十、简单了解Pytes**
打开pytest框架的官网。[http://www.pytest.org/en/latest/]( )
# content of test_sample.py
def inc(x):
return x + 1
def test_answer():
assert inc(3) == 5
官方教程我认为写的并不适合入门阅读,而且没有汉化版。
#### **pytest.ini**
pytest项目中的配置文件,可以对pytest执行过程中操作做全局控制。
在项目根目录新建`pytest.ini`文件。
[pytest]
addopts = --html=report.html --self-contained-html
* addopts 指定执行时的其他参数说明:
+ `--html=report/report.html --self-contained-html` 生成pytest-html带样式的报告
+ `-s` 输出我们用例中的调式信息
+ `-q` 安静的进行测试
+ `-v` 可以输出用例更加详细的执行信息,比如用例所在的文件及用例名称等
---
### **十一、编写测试用例**
我们将使用pytest编写测试用例。
在`TestCase`目录中创建`test_search.py`文件。
#!/usr/bin/env python3
# -- coding:utf-8 --
import re
import pytest
from utils.logger import log
from common.readconfig import ini
from page_object.searchpage import SearchPage
class TestSearch:
@pytest.fixture(scope=‘function’, autouse=True)
def open_baidu(self, drivers):
“”“打开百度”“”
search = SearchPage(drivers)
search.get_url(ini.url)
<span style="color:#7171bf">def</span> <span style="color:#61aeee">test_001</span>(self, drivers):
<span style="color:#98c379">"""搜索"""</span>
search = SearchPage(drivers)
search.input_search(<span style="color:#98c379">"selenium"</span>)
search.click_search()
result = re.search(<span style="color:#98c379">r'selenium'</span>, search.get_source)
log.info(result)
<span style="color:#7171bf">assert</span> result
<span style="color:#7171bf">def</span> <span style="color:#61aeee">test_002</span>(self, drivers):
<span style="color:#98c379">"""测试搜索候选"""</span>
search = SearchPage(drivers)
search.input_search(<span style="color:#98c379">"selenium"</span>)
log.info(<span style="color:#7171bf">list</span>(search.imagine))
<span style="color:#7171bf">assert</span> <span style="color:#7171bf">all</span>([<span style="color:#98c379">"selenium"</span> <span style="color:#7171bf">in</span> i <span style="color:#7171bf">for</span> i <span style="color:#7171bf">in</span> search.imagine])
if name == ‘main’:
pytest.main([‘TestCase/test_search.py’])
我们测试用了就编写好了。
* pytest.fixture 这个实现了和unittest的setup,teardown一样的前置启动,后置清理的装饰器。
* 第一个测试用例:
+ 我们实现了在百度selenium关键字,并点击搜索按钮,并在搜索结果中,用正则查找结果页源代码,返回数量大于10我们就认为通过。
* 第二个测试用例:
+ 我们实现了,搜索selenium,然后断言搜索候选中的所有结果有没有selenium关键字。
最后我们的在下面写一个执行启动的语句。
这时候我们应该进入执行了,但是还有一个问题,我们还没有把driver传递。
### **conftest.py**
我们在项目根目录下新建一个`conftest.py`文件。
#!/usr/bin/env python3
# -- coding:utf-8 --
import pytest
from py.xml import html
from selenium import webdriver
driver = None
@pytest.fixture(scope=‘session’, autouse=True)
def drivers(request):
global driver
if driver is None:
driver = webdriver.Chrome()
driver.maximize_window()
<span style="color:#7171bf">def</span> <span style="color:#61aeee">fn</span>():
driver.quit()
request.addfinalizer(fn)
<span style="color:#7171bf">return</span> driver
@pytest.hookimpl(hookwrapper=True)
def pytest_runtest_makereport(item):
“”"
当测试失败的时候,自动截图,展示到html报告中
:param item:
“”"
pytest_html = item.config.pluginmanager.getplugin(‘html’)
outcome = yield
report = outcome.get_result()
report.description = str(item.function.doc)
extra = getattr(report, ‘extra’, [])
<span style="color:#7171bf">if</span> report.when == <span style="color:#98c379">'call'</span> <span style="color:#7171bf">or</span> report.when == <span style="color:#98c379">"setup"</span>:
xfail = <span style="color:#7171bf">hasattr</span>(report, <span style="color:#98c379">'wasxfail'</span>)
<span style="color:#7171bf">if</span> (report.skipped <span style="color:#7171bf">and</span> xfail) <span style="color:#7171bf">or</span> (report.failed <span style="color:#7171bf">and</span> <span style="color:#7171bf">not</span> xfail):
file_name = report.nodeid.replace(<span style="color:#98c379">"::"</span>, <span style="color:#98c379">"_"</span>) + <span style="color:#98c379">".png"</span>
screen_img = _capture_screenshot()
<span style="color:#7171bf">if</span> file_name:
html = <span style="color:#98c379">'<div><img src="data:image/png;base64,%s" alt="screenshot" style="width:1024px;height:768px;" '</span> \
<span style="color:#98c379">'onclick="window.open(this.src)" align="right"/></div>'</span> % screen_img
extra.append(pytest_html.extras.html(html))
report.extra = extra
def pytest_html_results_table_header(cells):
cells.insert(1, html.th(‘用例名称’))
cells.insert(2, html.th(‘Test_nodeid’))
cells.pop(2)
def pytest_html_results_table_row(report, cells):
cells.insert(1, html.td(report.description))
cells.insert(2, html.td(report.nodeid))
cells.pop(2)
def pytest_html_results_table_html(report, data):
if report.passed:
del data[:]
data.append(html.div(‘通过的用例未捕获日志输出.’, class_=‘empty log’))
def _capture_screenshot():
‘’’
截图保存为base64
:return:
‘’'
return driver.get_screenshot_as_base64()
conftest.py测试框架pytest的胶水文件,里面用到了fixture的方法,封装并传递出了driver。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









