






+ - [拉链法](#_165)
- [开放寻址法(Open Addressing)](#Open_Addressing_176)
+ [读取](#_182)
+ [重建原理](#_198)
+ [删除原理](#_214)
21 切片和哈希表
切片
下面的代码中,foo 与 bar 最后的值是什么?
foo := []int{0,0,0,42,100}
bar := foo[1:4]
bar[1] = 99
fmt.Println("foo:", foo)
fmt.Println("bar:", bar)
// foo: [0 0 99 42 100]
// bar: [0 99 42]
下面程序输出什么?
x := []int{1, 2, 3, 4}
y := x[:2]
fmt.Println(cap(x), cap(y))
y = append(y, 30)
fmt.Println("x:", x)
fmt.Println("y:", y)
// Output
// 4, 4
// 1,2,30,4
// 1,2,30
底层结构
和 C 语言中的数组是一个指针不同,Go 中的切片是一个复合结构。一个切片在运行时由指针(data)、长度(len)和容量(cap)三部分构成。
type SliceHeader struct {
Data uintptr // 指向切片元素对应的底层数组元素的地址。
Len int // 对应切片中元素的数目,总长度不能超过容量。
Cap int // 提供了额外的元素空间,可以在之后更快地添加元素。容量的大小一般指的是从切片的开始位置到底层数据的结尾位置的长度。
}
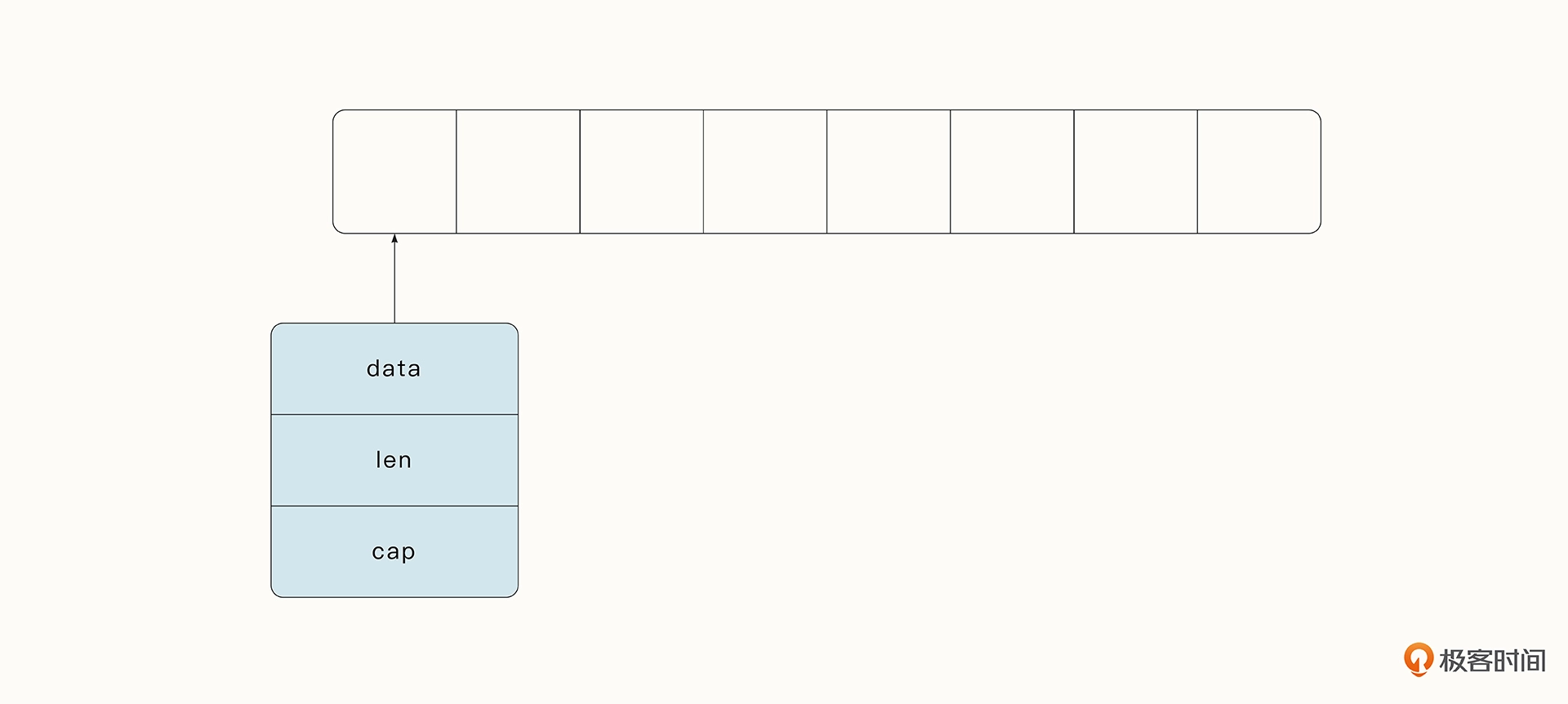
截取
切片在被截取时的一个特点是,截取后的切片长度和容量可能会发生变化。
和数组一样,切片中的数据仍然是内存中一片连续的区域。要获取切片某一区域的连续数据,可以通过下标的方式对切片进行截断。被截取后的切片,它的长度和容量都发生了变化。就像下面这个例子,numbers 切片的长度为 8。number1 截取了 numbers 切片中的第 2、3 号元素。number1 切片的长度变为了 2,容量变为了 6(即从第 2 号元素开始到元素数组的末尾)。
numbers:= []int{1,2,3,4,5,6,7,8}
// 从下标2 一直到下标4,但是不包括下标4
numbers1 :=numbers[2:4]
// 从下标0 一直到下标3,但是不包括下标3
numbers2 :=numbers[:3]
// 从下标3 一直到结尾
numbers3 :=numbers[3:]
切片在被截取时的另一个特点是,被截取后的数组仍然指向原始切片的底层数据。
例如之前提到的案例,bar 截取了 foo 切片中间的元素,并修改了 bar 中的第 2 号元素。
foo := []int{0,0,0,42,100}
bar := foo[1:4]
bar[1] = 99
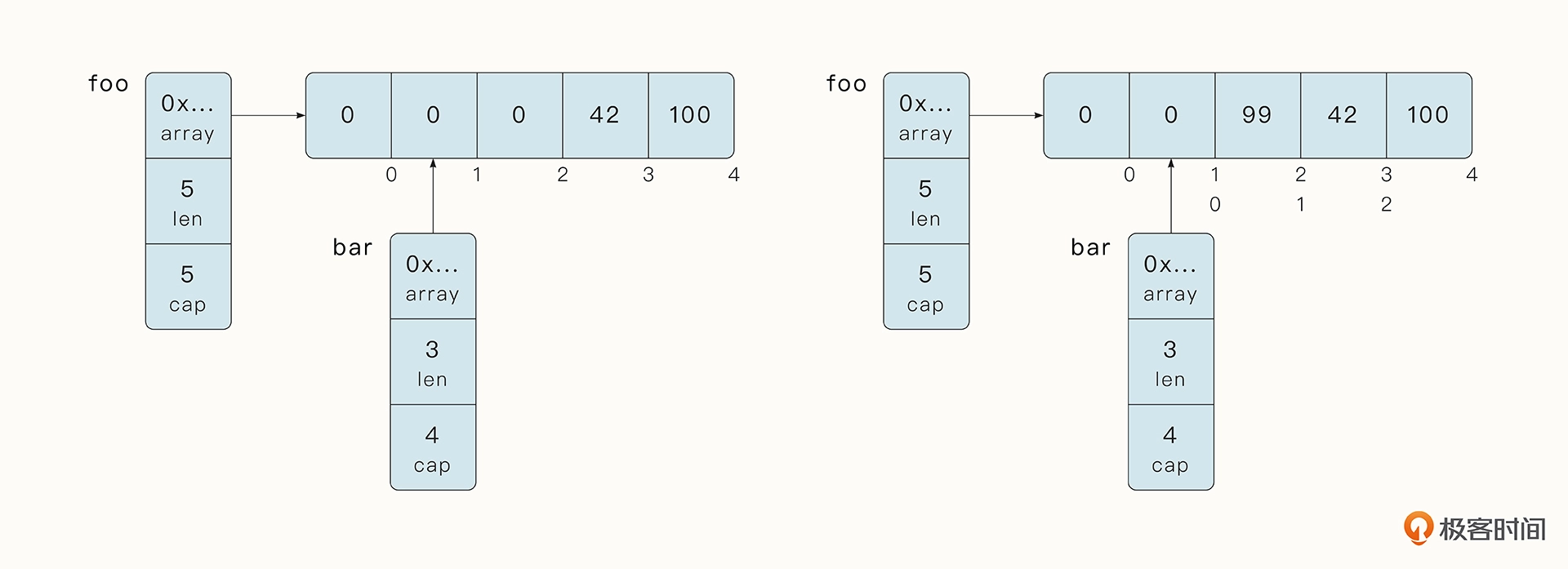
这时,bar 的 cap 容量会到原始切片的末尾,所以当前 bar 的 cap 长度为 4。
这意味着什么呢?我们看下面的例子,bar 执行了 append 函数之后,最终也修改了 foo 的最后一个元素,这是一个在实践中非常常见的陷阱。
foo := []int{0, 0, 0, 42, 100}
bar := foo[1:4]
bar = append(bar, 99)
fmt.Println("foo:", foo) // foo: [0 0 0 42 99]
fmt.Println("bar:", bar) // bar: [0 0 42 99]
//解决
foo := []int{0,0,0,42,100}
bar := foo[1:4:4] // 在截取时指定容量:
bar = append(bar, 99)
fmt.Println("foo:", foo) // foo: [0 0 0 42 100]
fmt.Println("bar:", bar) // bar: [0 0 42 99]
foo[1:4:4] 这种方式可能很多人没有见到过。这里,第三个参数 4 代表 cap 的位置一直到下标 4,但是不包括下标 4。 所以当前 bar 的 Cap 变为了 3,和它的长度相同。当 bar 进行 append 操作时,将发生扩容,它会指向与 foo 不同的底层数据空间。
扩容
Go 语言内置的 append 函数可以把新的元素添加到切片的末尾,它可以接受可变长度的元素,并且可以自动扩容。如果原有数组的长度和容量已经相同,那么在扩容后,长度和容量都会相 应增加。
不过,Go 语言并不会每增加一个元素就扩容一次,这是因为扩容常会涉及到内存的分配,频繁扩容会减慢 append 的速度。append 函数在运行时调用了 runtime/slice.go 文件下的 growslice 函数:
func growslice(et \*_type, old slice, cap int) slice {
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
...
}
- 如果新申请容量(cap)大于旧容量(old.cap)的两倍,则最终容量(newcap)是新申请的容量(cap);
- 如果旧切片的长度小于 1024,则最终容量是旧容量的 2 倍,即“newcap=doublecap”;
- 如果旧切片的长度大于或等于 1024,则最终容量从旧容量开始循环增加原来的 1/4,直到最终容量大于或等于新申请的容量为止;
- 如果最终容量计算值溢出,即超过了 int 的最大范围,则最终容量就是新申请容量。
切片动态扩容的机制启发我们,在一开始就要分配好切片的容量。否则频繁地扩容会影响程序的性能。所以我们可以将爬虫项目的容量扩展到 1000,注意长度需要为 0。
var seeds = make([]\*collect.Request, 0, 1000)
哈希表
实践中,我们通常将哈希表看作 o(1) 时间复杂度的操作,可以通过一个键快速寻找其唯一对应的值(Value)。
在很多情况下,哈希表的查找速度明显快于一些搜索树形式的数据结构,因此它被广泛用于关联数组、缓存、数据库缓存等场景。
原理
哈希表的原理是将多个键 / 值对(Key/Value)分散存储在 Buckets(桶)中。给定一个键(Key),哈希(Hash)算法会计算出键值对存储的桶的位置。找到存储桶的位置通常包括两步,伪代码如下:
hash = hashfunc(key)
index = hash % array_size
哈希碰撞
哈希函数在实际运用中最常见的问题是哈希碰撞(Hash Collision),即不同的键使用哈希算法可能产生相同的哈希值。如果将 2450 个键随机分配到一百万个桶中,根据概率计算,至少有两个键被分配到同一个桶中的可能性超过 95%。哈希碰撞导致同一个桶中可能存在多个元素,会减慢数据查找的速度。
避免哈希碰撞:
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
加入社区》https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0
[外链图片转存中…(img-RJeLLWxf-1725681631356)]
[外链图片转存中…(img-KjqQbEWa-1725681631357)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
加入社区》https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









