






自动驾驶像NLP的对话一样,是个很复杂的任务,它的解决方案也经历了几代变化:
- Standalone Models(图a):传统的做法是把最终目标拆解成一个个简单的单一模块,再分别去优化。但模块多了会造成误差传导,同时也可能丢失传递的信息。
- Multi-task(图b):有工作用多任务学习去训一个统一的模型,同时输出各个模块的预测结果。这样虽然某些任务会相互增强,但也有任务会相互削弱。而且每次更新都需要从新训练(避免遗忘之前的任务),会给系统带来很多变数,不确定性较高。
- Vanilla End2End(图c.1):能不能直接端到端呢?也有相关尝试,但对于安全要求极高的自动驾驶系统来说,纯端到端的可解释性和安全保障太弱了,想加一些强规则根本加不进去,比如识别到行人在前方就立刻刹车。
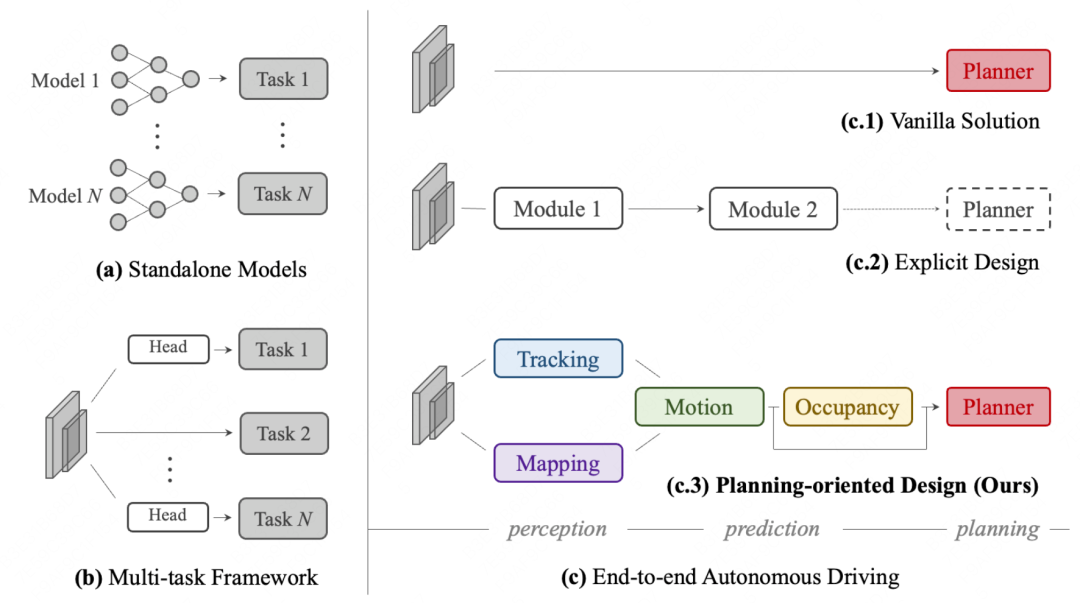
考虑到以上方案的优缺点之后,一个更好的方案就呼之欲出了:结合Pipeline系统的可控性+端到端for目标优化的效果保证,进行端到端Pipeline的联合优化(图c.3)。
虽然之前的工作也有类似的思想(图c.2),但都缺少一些任务(下表):
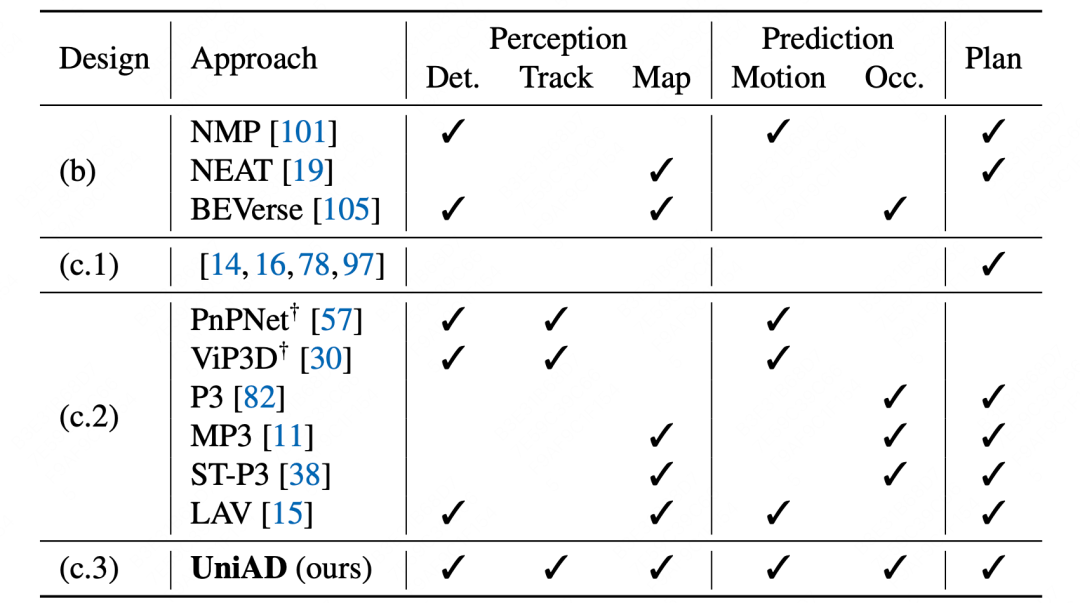
所以作者(上海人工智能实验室, 武汉大学,商汤)整理了自动驾驶中的感知、预测、规划三大步骤后,提出了UniAD (Unified Autonomous Driving)。
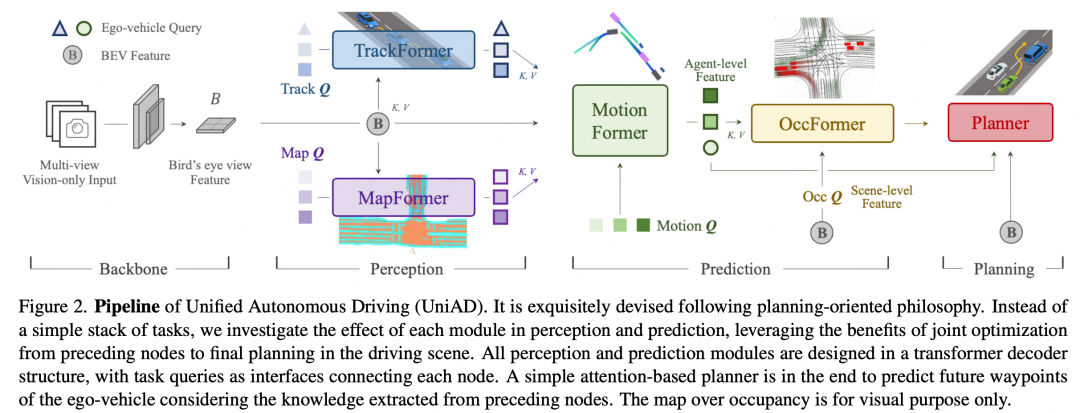
该网络由几个子模块组成,每个模块都是一个transformer decoder,不同模块之间通过向量进行交互,从而达到共同优化最终的目标。
这篇工作主要统一了自动驾驶系统中各模块的优化目标,联合优化后,在不同的子任务上都取得了较大的提升。
CV任务的统一
《Visual Programming: Compositional visual reasoning without training 》
另一篇今年的最佳论文是Visual Programming,出自AllenAI,简单地说就是利用GPT3/4强大的In-Context Learning能力,用伪代码的形式,把复杂的图像理解、编辑任务拆解成几个简单的CV子任务,再直接调用接口解决,如下图。

现在这个时间节点,大家可能已经对这个思路见怪不怪了,不过CVPR23的投稿时间其实是在ChatGPT发布之前,回到那个时间还是比较novel的。(如果关注Embodied AI的话,会发现去年这种LM去做子任务拆解的思路谷歌4月份发布的SayCan[4]就提了,anyway各个方向本身就是相互促进的,估计CVer之前看NLP一堆对比学习的文章也是见怪不怪)。
这种思路虽然很优雅地统一了CV任务的输入输出,但也存在两个让落地变难的点:
- 从实验结果看各种任务的准确率只有60%-80%(zero-shot),无法比上专门优化的模型。
- 作者在论文的实验中只定义了20个API,但如果真要覆盖所有CV任务,这个API定义是很大的工程量,而且随着候选API数量提升效果也会下降。
Large Vision Model的范式
《Towards AGI in Computer Vision: Lessons Learned from GPT and Large Language Models》
这篇文章出自华为,作者首先明确了他们眼中AGI的定义,即:
maximizing reward in an environment
要做一个序列决策模型,单纯的图片是不够的,必需有连续的图像信号。因此作者参考参考LLM的训练思路,定义了CV大模型的几个训练步骤:
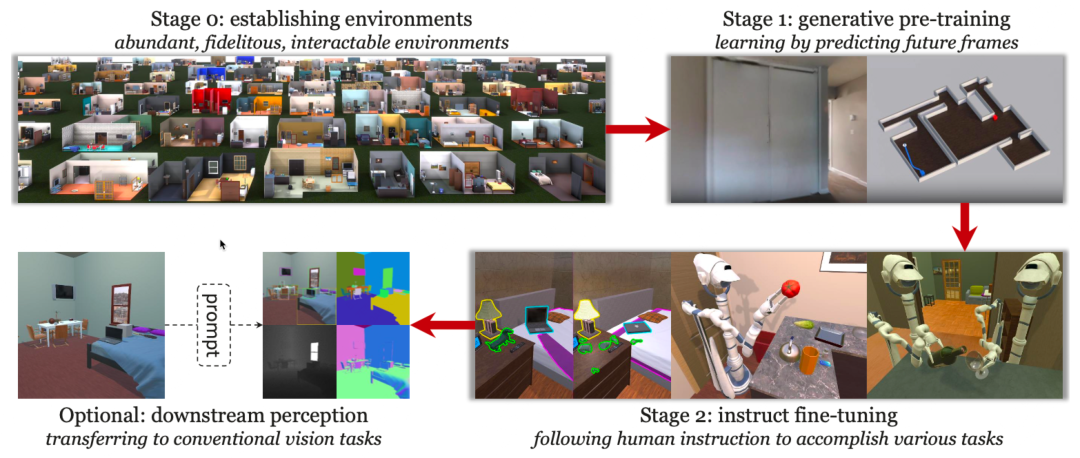
- 环境构建:首先需要有一个高质量、贴近现实、能实现各种交互的环境供模型学习(下文我们会讨论为什么要创建一个环境而不直接用现有数据)。
- 生成式预训练:仿照LM,训练模型预测下一帧。目前CV模型的预训练主要是Contrastive learning(判别式)和Masked image modeling(生成式),但MIM还不是序列层面的。
- 指令精调:训练模型遵循指令,与环境交互完成各种任务。
- 感知下游任务:通过前两步的训练之后,作者期望模型可以具备一定的zeroshot能力,通过prompt完成各种子任务。
这篇工作虽然给出了CV大模型的优化范式,但对于细节讨论较少,实操起来还是会有很多挑战,比如第一步环境建立就是一个超大的工程(狗头。
CV统一模型是否可行
让我们再回看开头说的NLP三个统一层级,对于CV是否可行呢?
对于任务形式(输入输出),个人认为不必追求单个模态,两者结合才是最优的。CV和NLP有个很大的差别是图像的信息密度较低。视觉能表达的东西有限,所以衍生出了抽象的语言,对知识、智能建模,作为人之间交流的工具。正因如此,单纯的图像也不适合作为人和机器之间交流的工具。但硬上其实也可以,毕竟我们读书看电脑也都是视觉转语言,中间加一层OCR就可以了。说不定等比transformer更好的编码器出来后真能这么搞。
对于网络结构,近年来有不少工作在尝试了。不过个人认为CV可能还是需要backbone的创新,因为CNN不适合处理长序列,而transformer目前需要把图像压缩成离散的patch,会造成信息损失,在某些落地场景不可用[5]。
像NLP一样以预训练为基座的优化范式的统一则是最难的。回到图像信息密度低的问题,这会导致CV大模型需要比NLP更多的数据进行训练,而数据的获取上就有诸多难点:
- 互联网上的图片、视频没有文字多。
- 大部分文字都是通顺的,而视频是跳跃的[6]。用现实世界训练效率又很低,所以第三篇工作才倡导构建一个虚拟环境。
所以个人还是觉得多模态更加靠谱,加一个模态来补充信息。但多模态预训练需要的高质量视频数据也不多,所以我目前觉得可行的是以NLP为基座,再融入CV模态进行生成式的多模态预训练。
最后,补充一个看论文看到的冷知识:我们学到的知识85%来自视觉信号。

















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









