







策略采取一个LTSM编码-译码器的形式(也就是,PRL(pi+1|pi,qi))并通过其参数定义。注意到策略是一个随机表示的(在动作给定状态上的概率分布),一个确定性的策略将导致不连续目标,且该目标难于使用基于梯度算法进行优化。
3.4 奖励
r表示每一个行动获得的奖励。
简化回答:由机器生成的行为应该很容易回应,这部份与其前向函数有关。提出的方法使用负对数似然表示对应的迟钝反应的对话来简化回答。手动构造一个迟钝反应的列表S,比如“我不知道你在干什么”,“我没有主意”等等。这在SEQ2SEQ对话模型中可以经常被发现,奖励函数可以用下式表达:
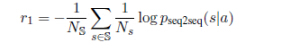

pseq2seq表示似然输出,另外注意到pseq2seq与随机策略函数PRL(pi+1|pi,qi)不同,前者的学习是基于SEQ2SEQ模型的MLE目标,而后者是对在RL集中的长期未来奖励的策略优化。r1是进一步扩大为目标长度S。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









