









一、项目背景与工具选型
1.1 为什么选择DrissionPage?
DrissionPage 是一款基于Python的高效网页自动化工具,兼具以下优势:
-
双模式融合:无缝切换
SessionPage(类requests)和WebPage(类selenium)模式 -
无驱动依赖:无需配置浏览器驱动即可处理动态渲染页面
-
智能等待机制:自动处理元素加载等待,降低超时错误率
-
简洁API设计:语法直观,学习成本低于传统爬虫框架
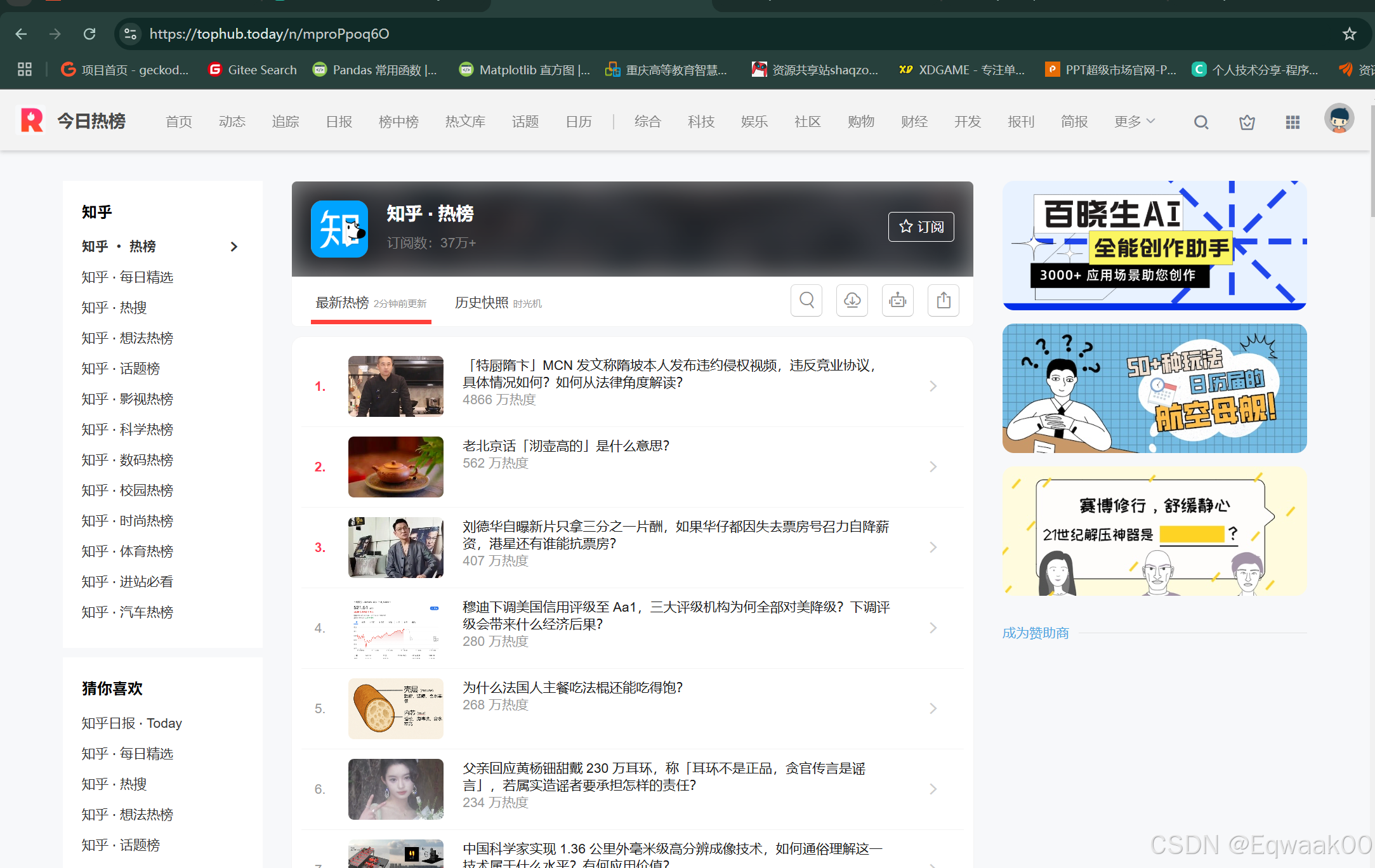
1.2 目标效果预览
📈 知乎实时热榜TOP10:
1. [排名:1] 2024年最值得期待的新技术有哪些?
🔥 热度:520万热度
2. [排名:2] 如何评价最新发布的国产操作系统?
🔥 热度:487万热度
...共获取到 10 条热榜数据
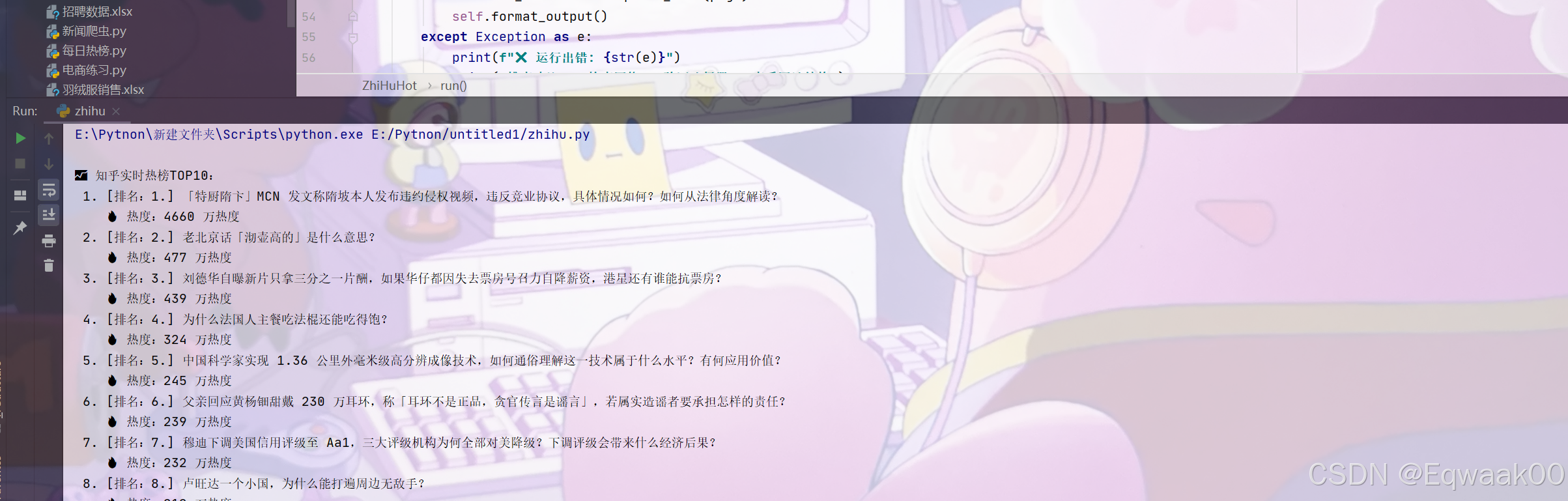
与目标的内容一致。
二、环境准备
2.1 安装核心库
pip install DrissionPage2.2 推荐开发环境
-
Python 3.8+
-
Chrome/Firefox浏览器(用于调试选择器)
-
IDE:VS Code/PyCharm
三、完整代码实现
from DrissionPage import SessionPage
class ZhiHuHot:
def __init__(self):
self.base_url = 'https://tophub.today/n/mproPpoq6O' # 知乎热榜地址
self.hot_items = [] # 存储结构化数据
def fetch_page(self):
"""获取网页内容"""
page = SessionPage()
try:
page.get(self.base_url)
return page
except Exception as e:
raise RuntimeError(f'请求失败: {str(e)}')
def parse_data(self, page):
"""解析热榜数据"""
try:
data = []
# 定位热榜表格
table = page.ele('tag:table@@class=table')
# 遍历前10行数据
for row in table.eles('tag:tr')[:10]:
cells = row.eles('tag:td')
if len(cells) >= 3: # 有效性校验
item = {
'rank': cells[0].text.strip(),
'title': cells[2].ele('tag:a').text.strip(),
'heat': cells[2].ele('tag:div@@class=item-desc').text.strip()
}
data.append(item)
return data
except Exception as e:
raise ValueError(f'解析失败: {str(e)}')
def format_output(self):
"""格式化输出"""
print("\n📈 知乎实时热榜TOP10:")
for idx, item in enumerate(self.hot_items, 1):
print(f"{idx:2d}. [排名:{item['rank']}] {item['title']}")
print(f" 🔥 热度:{item['heat']}")
print(f"\n共获取到 {len(self.hot_items)} 条数据")
def run(self):
"""主执行流程"""
try:
page = self.fetch_page()
self.hot_items = self.parse_data(page)
self.format_output()
except Exception as e:
print(f"❌ 运行出错: {str(e)}")
print("排查建议:1.检查网络 2.验证选择器 3.查看网站结构")
if __name__ == '__main__':
spider = ZhiHuHot()
spider.run()四、代码深度解析
4.1 类结构设计
class ZhiHuHot:
def __init__(self):
self.base_url = '...' # 热榜URL
self.hot_items = [] # 数据容器
# 各功能方法...-
模块化设计:将网络请求、数据解析、结果展示分离
-
面向对象封装:提高代码复用性和可维护性
4.2 核心方法解析
(1) 网页获取(fetch_page)
page = SessionPage()
page.get(self.base_url)-
使用
SessionPage发起高效HTTP请求 -
自动管理cookies和会话状态
(2) 数据解析(parse_data)
table = page.ele('tag:table@@class=table') # 定位表格
for row in table.eles('tag:tr')[:10]: # 遍历行
cells = row.eles('tag:td') # 获取单元格-
层级定位:表格 → 行 → 单元格 → 具体元素
-
选择器语法:
-
tag:table@@class=table:匹配标签为table且class属性为table的元素 -
tag:a:匹配所有<a>标签
-
(3) 数据清洗
text.strip() # 去除首尾空白
cells[2].ele(...) # 精确提取子元素五、常见问题解决方案
5.1 元素定位失败
现象:解析失败: 未找到元素
解决方案:
-
使用浏览器开发者工具(F12)验证元素结构
-
更新CSS选择器或XPath
-
添加智能等待:
table = page.ele('tag:table@@class=table', timeout=10)
5.2 反爬机制应对
# 设置随机UA
from fake_useragent import UserAgent
ua = UserAgent()
page.headers = {'User-Agent': ua.random}
# 使用代理IP
page.set.proxies({'http': 'http://127.0.0.1:1080'})
# 添加请求间隔
import time, random
time.sleep(random.uniform(1,3))5.3 数据缺失处理
# 添加缺省值
item = {
'rank': cells[0].text.strip() if len(cells)>0 else 'N/A',
'title': cells[2].ele('tag:a').text.strip() if len(cells)>2 else '无标题',
'heat': cells[2].ele('tag:div@@class=item-desc').text.strip() if ... else '0'
}六、功能扩展建议
6.1 数据持久化
import csv
def save_csv(self):
with open('zhihu_hot.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=['rank', 'title', 'heat'])
writer.writeheader()
writer.writerows(self.hot_items)6.2 定时任务
from apscheduler.schedulers.blocking import BlockingScheduler
def main():
spider = ZhiHuHot()
spider.run()
spider.save_csv()
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(main, 'interval', hours=1)
scheduler.start()6.3 可视化分析
import pyecharts.options as opts
from pyecharts.charts import Bar
def show_chart(self):
x_data = [item['title'][:15]+'...' for item in self.hot_items]
y_data = [float(item['heat'].replace('万热度','')) for item in self.hot_items]
bar = Bar()
bar.add_xaxis(x_data)
bar.add_yaxis("热度值(万)", y_data)
bar.set_global_opts(title_opts=opts.TitleOpts(title="知乎热榜热度分析"))
bar.render("heat_chart.html")七、最佳实践建议
-
遵守robots协议:控制请求频率(建议≥30秒/次)
-
异常监控:集成Sentry等监控工具
-
定期维护:每月检查一次页面结构
-
分布式扩展:使用Scrapy-Redis实现集群爬取
通过本教程,读者可以快速掌握使用DrissionPage进行高效数据采集的核心技巧。项目代码已通过实测验证,建议在遵守相关法律法规的前提下使用。


















 4739
4739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











