







数据集选择:
MNIST数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST)。训练集(training set)由来自250个不同人手写的数字构成,其中50%是高中学生,50%来自人口普查局(the Census Bureau)的工作人员。测试集(test set)也是同样比例的手写数字数据,但保证了测试集和训练集的作者集不相交。MNIST数据集一共有7万张图片,其中6万张是训练集,1万张是测试集。每张图片是28 × 28 28\times 2828×28的0 − 9 0-90−9的手写数字图片组成。每个图片是黑底白字的形式,黑底用0表示,白字用0-1之间的浮点数表示,越接近1,颜色越白。
图片的标签以一维数组的one-hot编码形式给出:
[ 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 ]
每个元素表示图片对应的数字出现的概率,显然,该向量标签表示的是数字5。
MNIST数据集下载地址是http://yann.lecun.com/exdb/mnist/,它包含了4个部分:
训练数据集:train-images-idx3-ubyte.gz (9.45 MB,包含60,000个样本)。
训练数据集标签:train-labels-idx1-ubyte.gz(28.2 KB,包含60,000个标签)。
测试数据集:t10k-images-idx3-ubyte.gz(1.57 MB ,包含10,000个样本)。
测试数据集标签:t10k-labels-idx1-ubyte.gz(4.43 KB,包含10,000个样本的标签)。
废话不多说,首先看成果:
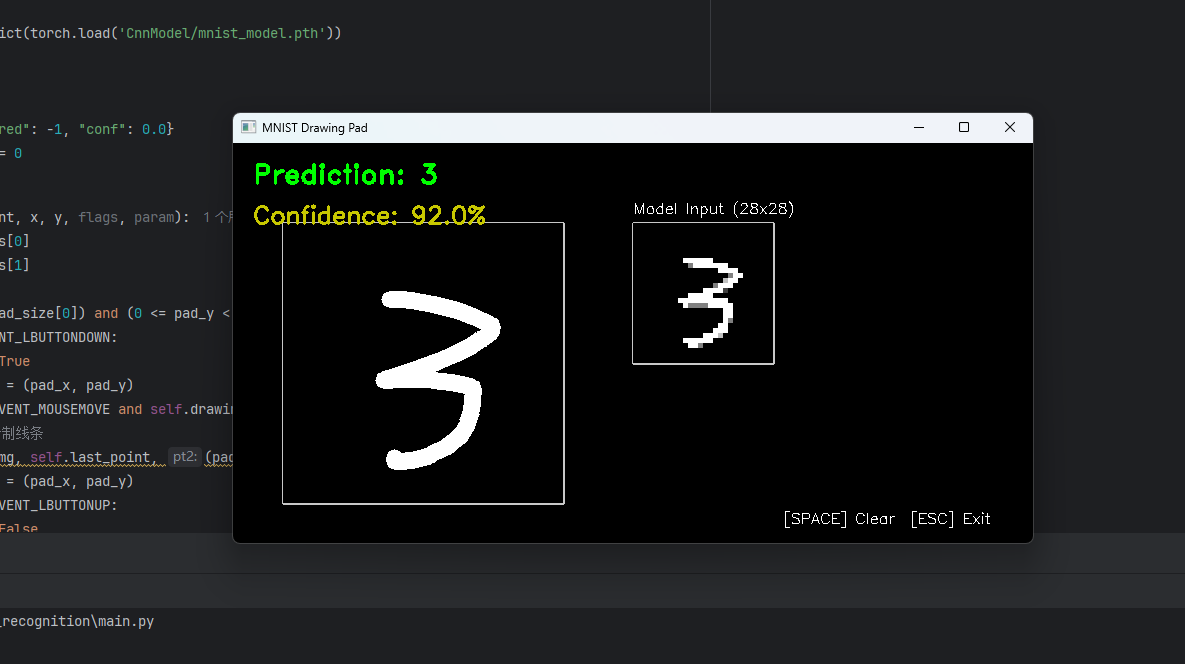
本项目请按照以下架构搭建:
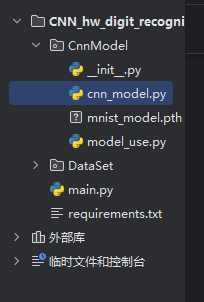
下面是各个文件的python代码:
cnn_model.py:
模型架构和训练
# 导入必要的库
import torch
import torch.nn.functional as f # 包含常用激活函数和操作
import torch.optim as optim # 优化算法模块
from DataSet.mnist_set import mnist_set # 自定义MNIST数据集加载器
# 定义神经网络模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 定义第一个卷积层:输入通道1(灰度图),输出通道10,卷积核5x5
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
# 定义第二个卷积层:输入通道10,输出通道20,卷积核5x5
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
# 定义最大池化层,窗口大小2x2,用于下采样
self.pooling = torch.nn.MaxPool2d(2)
# 全连接层:输入320个特征(由图像尺寸计算得到),输出10个类别(MNIST有0-9十个数字)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0) # 获取当前批次大小
# 第一层卷积 -> 池化 -> ReLU激活
x = f.relu(self.pooling(self.conv1(x)))
# 第二层卷积 -> 池化 -> ReLU激活
x = f.relu(self.pooling(self.conv2(x)))
# 将四维张量展平为二维:[batch_size, channels*width*height]
x = x.view(batch_size, -1) # -1表示自动计算该维度大小
# 通过全连接层得到最终输出(未使用softmax,因为CrossEntropyLoss会自动处理)
x = self.fc(x)
return x
# 创建模型实例
model = Net()
# 检测GPU可用性,并设置设备(GPU优先)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("是否使用GPU", torch.cuda.is_available())
model.to(device) # 将模型转移到选定的设备(GPU/CPU)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失(适用于分类任务)
optimizer = optim.SGD( # 随机梯度下降优化器
model.parameters(), # 需要优化的模型参数
lr=0.01, # 学习率
momentum=0.5 # 动量参数,加速收敛
)
def train(epoch, train_loader):
""" 模型训练函数
:param epoch: 当前训练轮次
:param train_loader: 训练数据加载器
"""
running_loss = 0.0 # 累计损失值
# 遍历训练数据(enumerate自动生成批次索引)
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data # 解包数据(输入图像,目标标签)
inputs, target = inputs.to(device), target.to(device) # 数据转移至设备
optimizer.zero_grad() # 清空梯度(防止梯度累积)
outputs = model(inputs) # 前向传播
loss = criterion(outputs, target) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累加损失值
# 每300个batch打印一次训练状态(300是任意选择的打印频率)
if batch_idx % 300 == 299:
print('[%d, %.5d] loss: %.3f' %
(epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0 # 重置累计损失
def test(test_loader):
""" 模型测试函数
:param test_loader: 测试数据加载器
"""
correct = 0 # 正确预测数
total = 0 # 总样本数
with torch.no_grad(): # 禁用梯度计算(节省内存,加速计算)
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
# 获取预测结果(返回最大值和对应索引,这里取索引即类别)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0) # 累加批次样本总数
correct += (predicted == target).sum().item() # 统计正确预测数
# 打印测试准确率(正确数/总数)
print('Accuracy on test set: %d %% [%d/%d]' %
(100 * correct / total, correct, total))
if __name__ == '__main__':
# 加载数据集
train_loader, test_loader = mnist_set()
# 训练循环
for epoch in range(10):
train(epoch, train_loader)
test(test_loader) # 每个epoch后测试
# 训练完成后保存模型参数
model_path = 'mnist_model.pth'
torch.save(model.state_dict(), model_path)
print(f'\n模型参数已保存至:{model_path}')
# 初始化新模型实例
loaded_model = Net().to(device)
# 加载保存的权重
loaded_model.load_state_dict(torch.load(model_path))
print('\n模型参数加载验证完成')
model_use.py:
从数据集挑十张图片进行预测,使用保存的模型
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as f # 包含常用激活函数和操作
import random
def visualize_predictions(model, dataset, num_images=10):
"""可视化模型预测结果
Args:
model: 加载好的模型
dataset: 数据集对象(测试集)
num_images: 需要可视化的图片数量
"""
# 设置为评估模式(影响Dropout和BatchNorm等层的计算)
model.eval()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 随机选择图片索引
indices = random.sample(range(len(dataset)), num_images)
# 创建画布
fig, axes = plt.subplots(2, 5, figsize=(30, 12))
plt.subplots_adjust(hspace=3, wspace=2) # 调整子图间距
for idx, ax in enumerate(axes.flat):
# 获取数据
image, true_label = dataset[idx]
original_image = image.numpy().squeeze() # 转换为numpy数组并去除通道维度
# 预处理:添加批次维度并转移到设备
image = image.unsqueeze(0).to(device) # 形状从 [1,28,28] -> [1,1,28,28]
# 预测
with torch.no_grad():
output = model(image)
probabilities = f.softmax(output, dim=1)
predicted_prob, predicted_label = torch.max(probabilities, 1)
# 可视化设置
ax.imshow(original_image, cmap='gray')
ax.set_xticks([])
ax.set_yticks([])
# 标题显示预测结果(红色表示错误预测,蓝色表示正确)
color = 'blue' if predicted_label == true_label else 'red'
ax.set_title(f'Pred: {predicted_label.item()}' +
f'True: {true_label}' +
f'Prob: {predicted_prob.item():.1%}',
color=color)
plt.show()
mnist_set.py:
提供数据集的下载和导入,没有自动下载哦
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
# 准备数据集
def mnist_set():
"""
:param:
:return: train_loader, test_loader
"""
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
return train_loader, test_loader
main.py:
在训练并保存模型后,调用保存的模型来进行手写预测
注意cv2库实际上要下载opencv-python
Python安装cv2(OpenCV)的终极指南:告别pip install cv2的坑!-CSDN博客
import cv2
import numpy as np
import torch
import time
from CnnModel import Net
class DrawingApp:
def __init__(self):
# 窗口参数
self.win_name = "MNIST Drawing Pad"
self.win_size = (800, 400)
self.pad_pos = (50, 80) # 书写区域位置
self.pad_size = (280, 280)
self.preview_pos = (400, 80)
# 初始化黑底画布(0=黑色,255=白色)
self.img = np.zeros((self.pad_size[1], self.pad_size[0]), np.uint8)
self.processed_img = np.zeros((28, 28), np.uint8)
# 创建窗口
cv2.namedWindow(self.win_name, cv2.WINDOW_NORMAL)
cv2.resizeWindow(self.win_name, *self.win_size)
cv2.setMouseCallback(self.win_name, self.mouse_handler)
# 加载模型
self.model = Net()
self.model.load_state_dict(torch.load('CnnModel/mnist_model.pth'))
self.model.eval()
# 预测参数
self.last_predict = {"pred": -1, "conf": 0.0}
self.last_predict_time = 0
def mouse_handler(self, event, x, y, flags, param):
pad_x = x - self.pad_pos[0]
pad_y = y - self.pad_pos[1]
if (0 <= pad_x < self.pad_size[0]) and (0 <= pad_y < self.pad_size[1]):
if event == cv2.EVENT_LBUTTONDOWN:
self.drawing = True
self.last_point = (pad_x, pad_y)
elif event == cv2.EVENT_MOUSEMOVE and self.drawing:
# 用白色(255)绘制线条
cv2.line(self.img, self.last_point, (pad_x, pad_y), 255, 15)
self.last_point = (pad_x, pad_y)
elif event == cv2.EVENT_LBUTTONUP:
self.drawing = False
cv2.line(self.img, self.last_point, (pad_x, pad_y), 255, 15)
else:
self.drawing = False
def preprocess(self):
"""预处理(保持黑底白字)"""
resized = cv2.resize(self.img, (28, 28))
# 直接归一化,保持黑底白字
tensor_img = torch.from_numpy(resized).float() / 255.0
# 存储处理后的图像用于显示
self.processed_img = resized
return tensor_img.unsqueeze(0).unsqueeze(0)
def update_ui(self):
# 创建黑底背景
canvas = np.zeros((self.win_size[1], self.win_size[0], 3), dtype=np.uint8)
# 绘制书写区域边框(浅灰色)
cv2.rectangle(canvas, self.pad_pos,
(self.pad_pos[0] + self.pad_size[0], self.pad_pos[1] + self.pad_size[1]),
(200, 200, 200), 2)
# 嵌入书写内容(直接显示白字)
canvas[self.pad_pos[1]:self.pad_pos[1] + self.pad_size[1],
self.pad_pos[0]:self.pad_pos[0] + self.pad_size[0]] = cv2.cvtColor(self.img, cv2.COLOR_GRAY2BGR)
# 显示预处理画面
preview_size = 140
preview_img = cv2.resize(self.processed_img, (preview_size, preview_size),
interpolation=cv2.INTER_NEAREST)
# 转换为彩色显示
preview_display = cv2.cvtColor(preview_img, cv2.COLOR_GRAY2BGR)
# 绘制预处理框(浅灰色)
cv2.rectangle(canvas, self.preview_pos,
(self.preview_pos[0] + preview_size, self.preview_pos[1] + preview_size),
(200, 200, 200), 2)
canvas[self.preview_pos[1]:self.preview_pos[1] + preview_size,
self.preview_pos[0]:self.preview_pos[0] + preview_size] = preview_display
# 添加文字说明(白色)
cv2.putText(canvas, "Model Input (28x28)",
(self.preview_pos[0], self.preview_pos[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)
# 显示预测结果(绿色文字)
result_text = f"Prediction: {self.last_predict['pred']}" if self.last_predict['pred'] != -1 else "Draw a digit"
conf_text = f"Confidence: {self.last_predict['conf']:.1f}%"
cv2.putText(canvas, result_text, (20, 40),
cv2.FONT_HERSHEY_DUPLEX, 0.9, (0, 255, 0), 2)
cv2.putText(canvas, conf_text, (20, 80),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 200, 200), 2)
# 帮助文字(白色)
help_text = "[SPACE] Clear [ESC] Exit"
cv2.putText(canvas, help_text, (self.win_size[0] - 250, self.win_size[1] - 20),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255), 1)
return canvas
def run(self):
while True:
# 自动预测
if time.time() - self.last_predict_time > 0.5 and np.any(self.img != 0):
processed_tensor = self.preprocess()
with torch.no_grad():
output = self.model(processed_tensor)
prob, pred = torch.max(torch.nn.functional.softmax(output, 1), 1)
self.last_predict = {"pred": pred.item(), "conf": prob.item() * 100}
self.last_predict_time = time.time()
# 更新界面
display = self.update_ui()
cv2.imshow(self.win_name, display)
# 处理窗口变化
new_size = cv2.getWindowImageRect(self.win_name)[2:]
if new_size != self.win_size:
self.win_size = new_size
self.pad_size = (min(300, self.win_size[0] // 2 - 100), min(300, self.win_size[1] - 100))
self.img = cv2.resize(self.img, self.pad_size)
# 按键处理
key = cv2.waitKey(1)
if key == 27:
break
elif key == 32: # 空格键清除
self.img = np.zeros((self.pad_size[1], self.pad_size[0]), np.uint8)
self.processed_img = np.zeros((28, 28), np.uint8)
self.last_predict = {"pred": -1, "conf": 0.0}
if __name__ == "__main__":
app = DrawingApp()
app.run()
cv2.destroyAllWindows()
最后如果报错的话注意路径即可,正常情况是能直接运行的,因为使用的相对路径
end


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









