







目录
1.Linux下一切皆文件
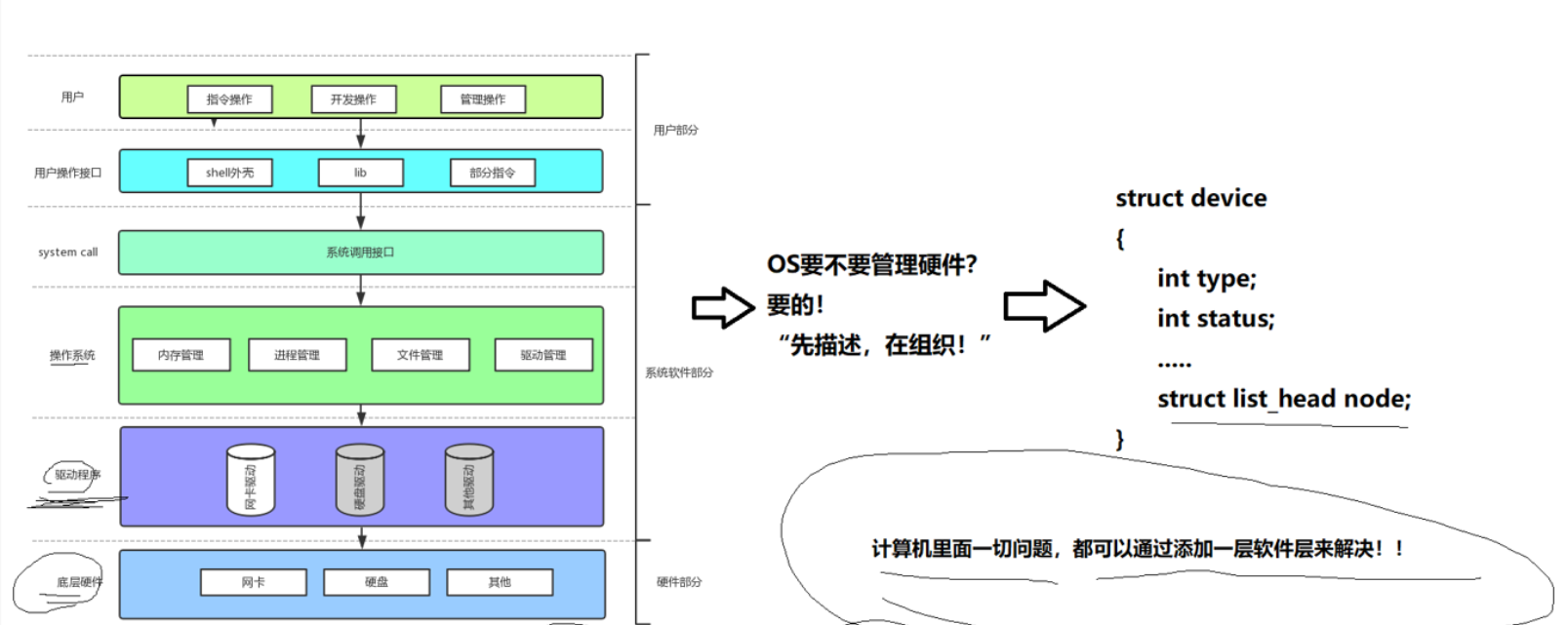
在前面我们反复说过,我们Linux下一切皆文件的设计哲学,我们之前,说Linux一切皆文件就是键盘,CPU,内存等硬件也都是文件,我们现在对这个概念再进行理解之前,我们先理解一下我们的电脑是怎么来运作的
我们知道我们的计算机是层状的,操作系统是帮助管理软件和硬件的软件,操作系统要管理硬件,作为大管家,它肯定要管理,怎么管理,先描述,再组织,既然每个设备都是文件,那么我对磁盘描述,对键盘描述,对鼠标描述,然后用把他们组织起来就可以实现对硬件的管理了,我们把硬件这种东西抽象成文件的好处是,将来我们可以用访问文件的形式来访问硬件!
这样我们开发者仅仅使用一套命令就可以完成对大部分硬件和文件的操作,简化了我们的操作,提高了我们的开发效率!我们几乎可以用read读到所有的资源,用write可以往所有的设备里进行写入!!!
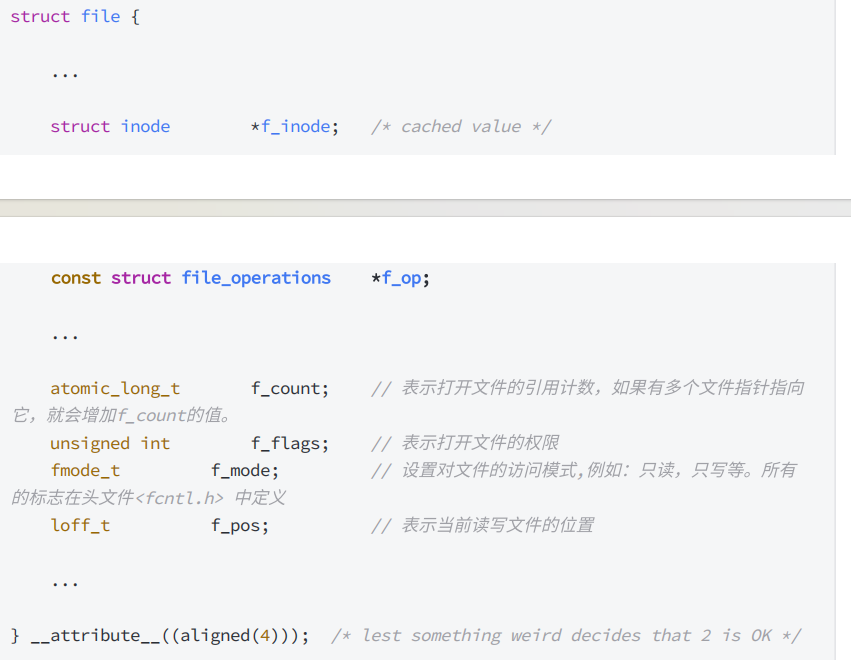
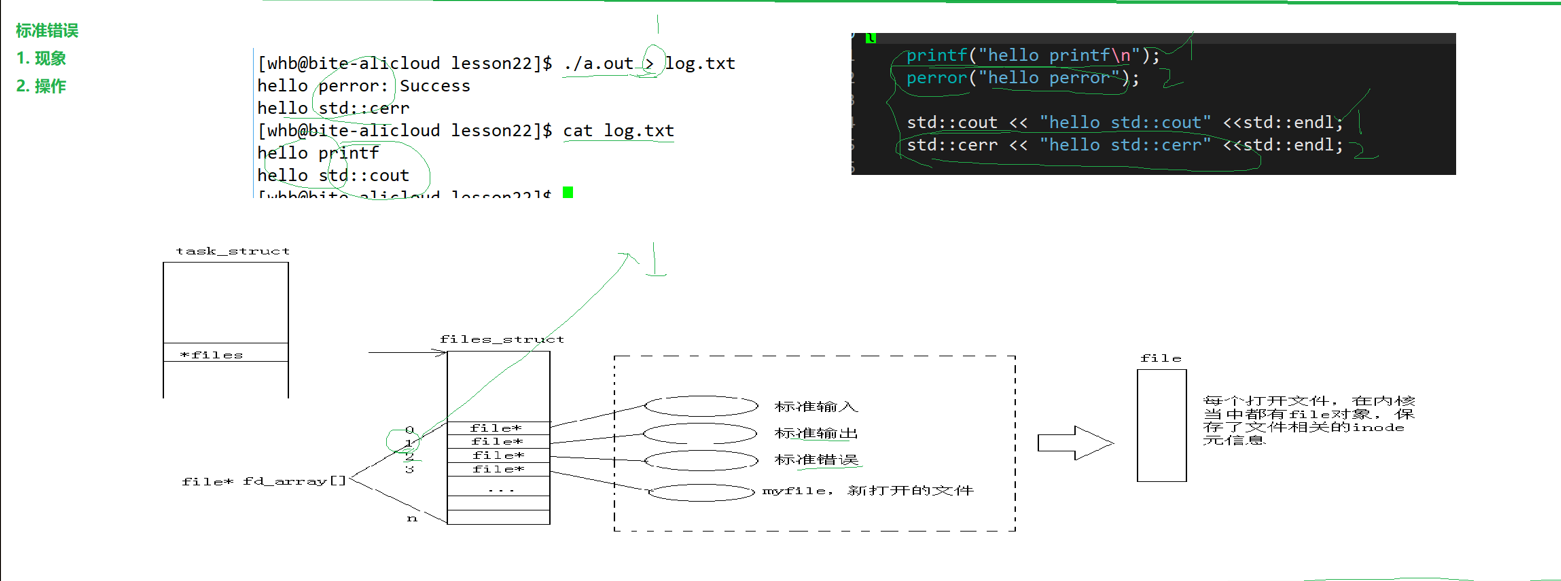
打开我们的file结构体,我们可以发现里面有一个*f_op,这个指针指向一个结构体,结构体里有许多函数指针,我们很多系统调用都来自于这里的函数指针
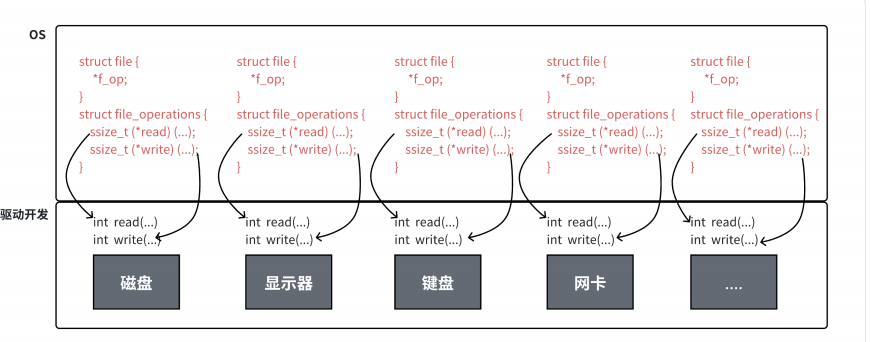
这里我们每个硬件肯定有不同的read和不同的write的实现方法,但是我们给它们函数起的名字都一样,这样我们可以通过函数调用的方法实现对他们用同一个函数进行调用,这样我们就实现了Linux下一切皆文件的设计哲学!!!
我们理解Linux下一切皆文件,是站在进程的角度下看file结构体,知道他们的调用模式我们才能更好的理解什么是Linux下一切皆文件!!!
知道了file里面有一个结构体指针指向一个结构体,结构体里面有许多函数调用的接口,我们每一个接口指向一个硬件的函数实现,我们通过统一的函数名实现了不同的函数实现,至此,我们实现了Linux下一切皆文件的设计哲学!!!
我们知道我们的命令例如ls等这些命令本质是我们的bash进程创建了一个子进程去执行的,我们可以说我们访问设备,其实是通过进程去访问的,不同的设备访问方式不同,但是通过这种函数回调的形式我们实现了用read读取所有设备的资源!!!
先描述,再组织,每个PCB里面有一个file,file有一个f_op的结构体指针指向一个函数实现的机结构体,这个结构体里面有许多函数指针,每一个指针都指向不同的设备,我们就实现了每一个进程访问不同的设备用同一个系统调用来实现,非常精妙的设计啊!!!!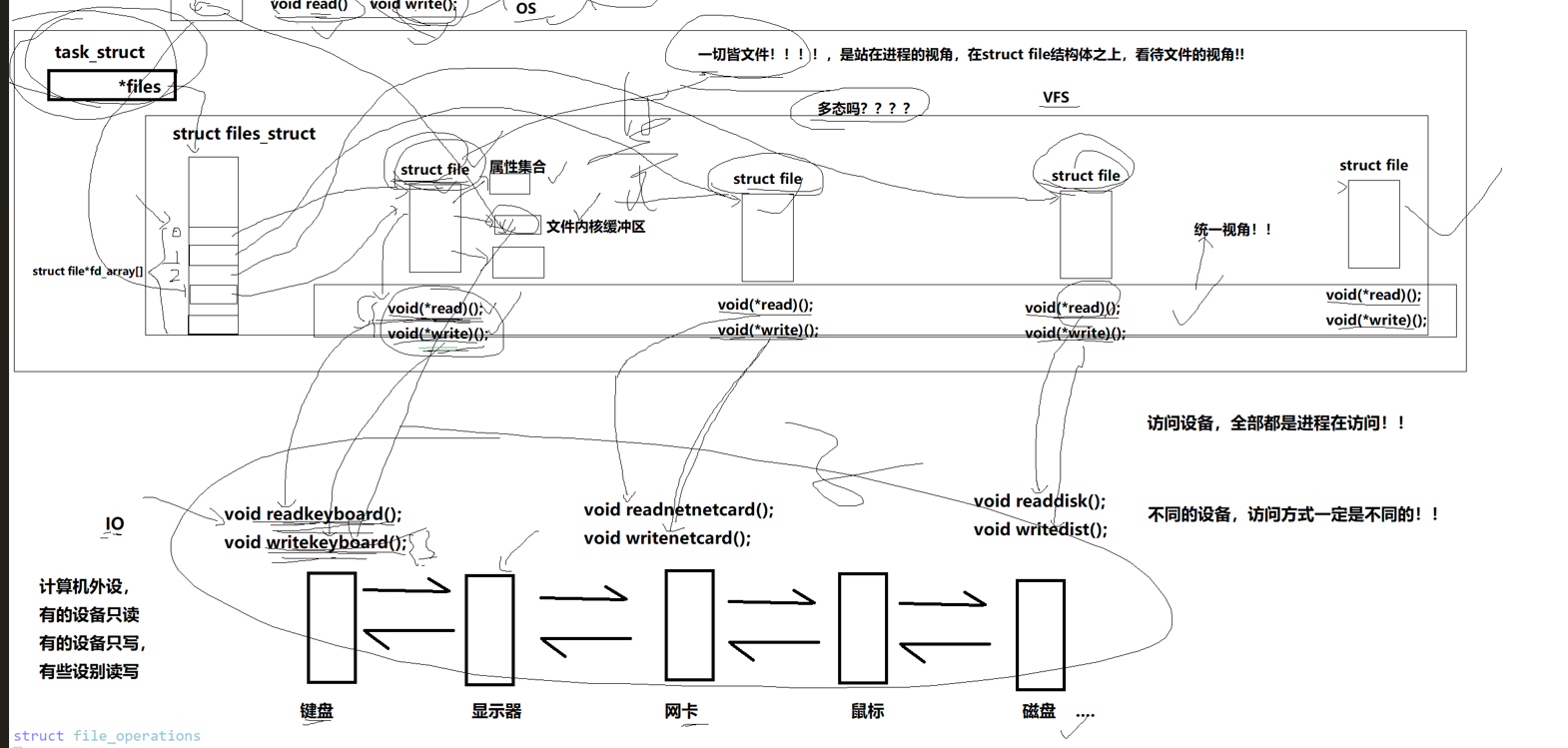
2,缓冲区

我们的示意图大致如下:我们的PCB里面有file的数组,数组下标代表不同的文件,也就是文件描述符系统,每一个file都有对应的属性,操作方法,文件缓冲区!!!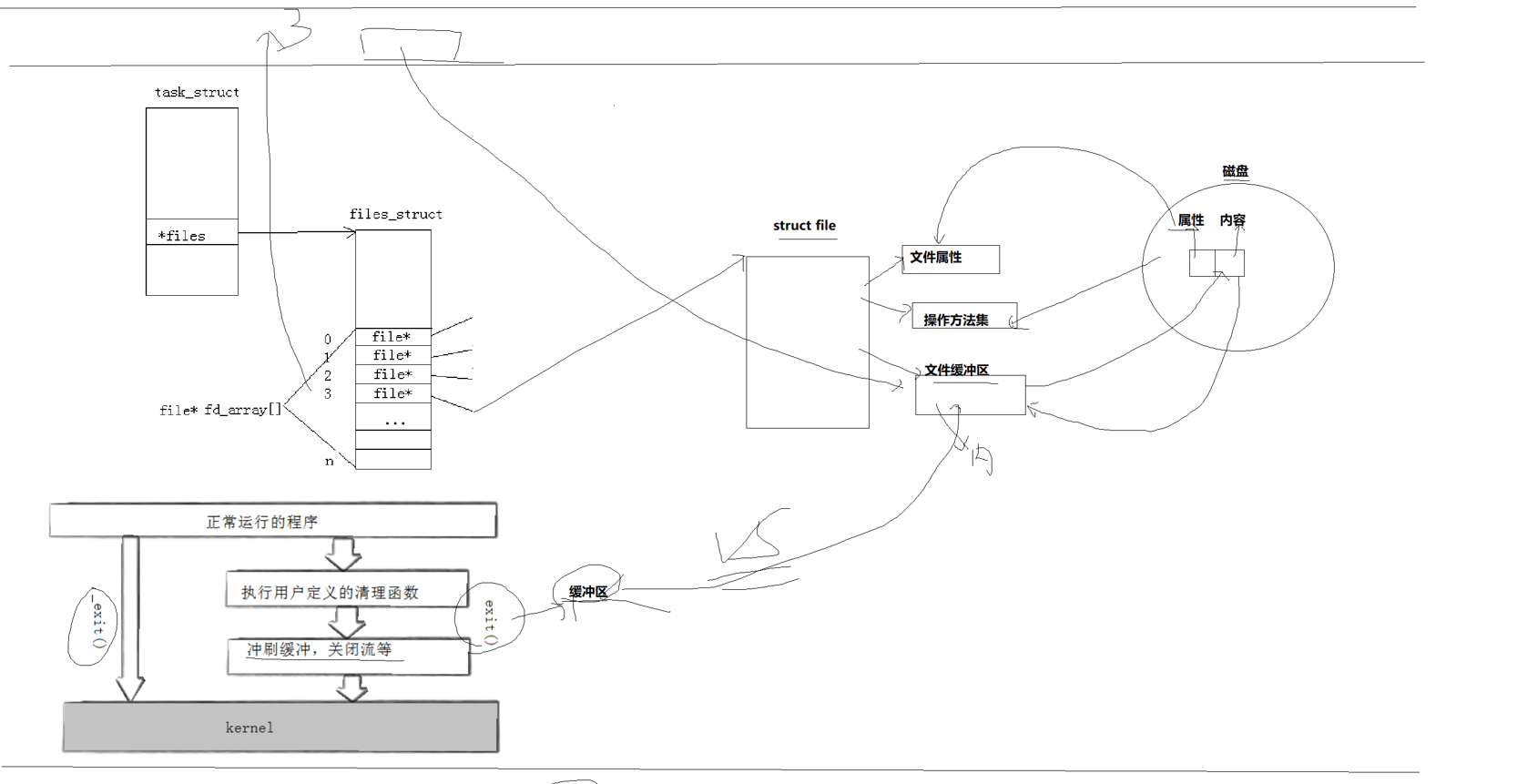
缓冲区的本质是一段内存空间,我们每一次write之后,系统必须要立即往磁盘里刷新吗?不一定吧,我们write一下写一次需要与磁盘进行IO,我们知道CPU只和内存打交道,我们磁盘属于是外设,它的效率对于CPU来说实在是太慢了,但是它的容量大,便宜!
我们的缓冲区设计出来最主要最根本的目的就是提升效率,减少IO次数,我们通过把数据缓存在内存里,减少IO的次数来提高我们的操作系统的效率!
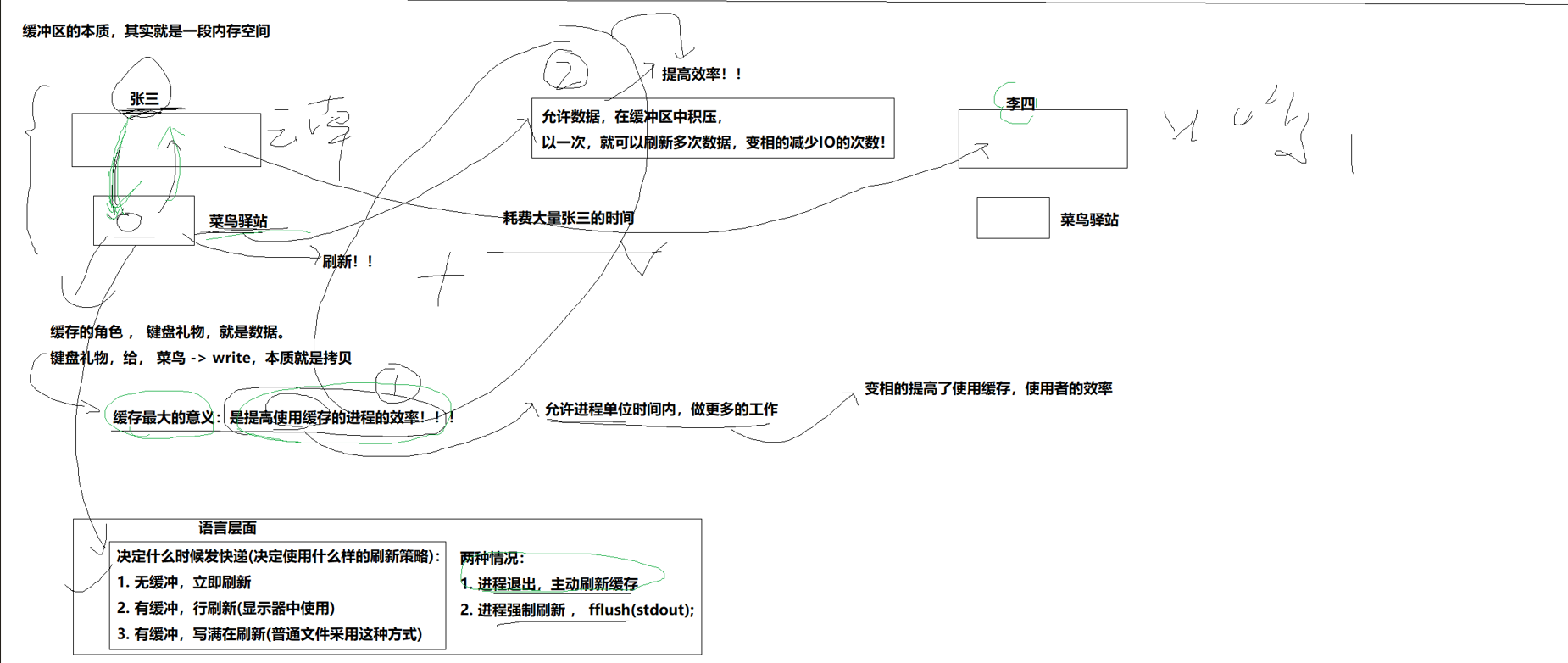
我们的缓冲有3种方式:
这里我们的缓冲方式都是语言级别的,而非内核级别的
全缓冲区,顾名思义就是把缓冲区填满就往磁盘写入
行缓存,遇到换行符进行IO一次
‘无缓冲区’,不缓存,直接IO加快信息的读取

系统退出的时候,我们会自动把缓存的内容写入磁盘,还有用fflush进行强制缓存!
实践是检验真理的唯一标准,我们通过一段代码来说明一下问题,我们这个主要是关闭输出流,然后我们完成输入重定向,我们打印的内容输入到我们的文件里去,但是我们检查的时候发现我们的文件里没内容,这是因为我们的stdout是行缓存,换行就会输出,但是我们切换为普通文件后,变为全缓冲,我们得把缓冲区填满才写入,有的同学就要问了,不是说好的进程结束我们的缓冲区强制刷新吗?这里为什么不刷新?问题是我们在它缓冲之前就先把文件关掉了,文件关闭了,还写入个毛,自然没有写入成功!!!
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
close(1);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
printf("hello world: %d\n", fd);
close(fd);
return 0;
}这段代码为啥log里没内容,不是说进程结束缓冲区强制刷新吗,#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
close(2);
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (fd < 0) {
perror("open");
return 0;
}
perror("hello world");
close(fd);
return 0;
}上面这段代码我们就会刷新到磁盘里去,因为我们重定向到了stderr文件,stderr没有缓冲区,会直接刷新到磁盘上面去
有的同学要问,我stdout重定向是从行缓冲编程了全缓冲,我stderr重定向还是无缓存,你扯不扯,没办法我们的设计就是这么设计的!!!


3.FILE
当我们把缓冲区从语言缓冲区交给内核缓冲区,我们的内容就已经完成,剩下的事情是操作系统该操作的事情,不是我们要做的!!!所以作为用户的我们,当我们把我们的数据交给内核我们的任务就已经完成了!!!
我们的FILE是C语言帮助我们实现的FILE,它也有缓冲区,但是不是我们的内核缓冲区,而是自己实现的缓冲区,我们可以推断它的底层必定封装了我们的系统调用,因为谁对操作系统进行操作都需要通过系统调用进行,语言的编写者也不例外,本质上来说是操作系统不信任人类,FILE的内部为我们维护语言级别的缓冲区
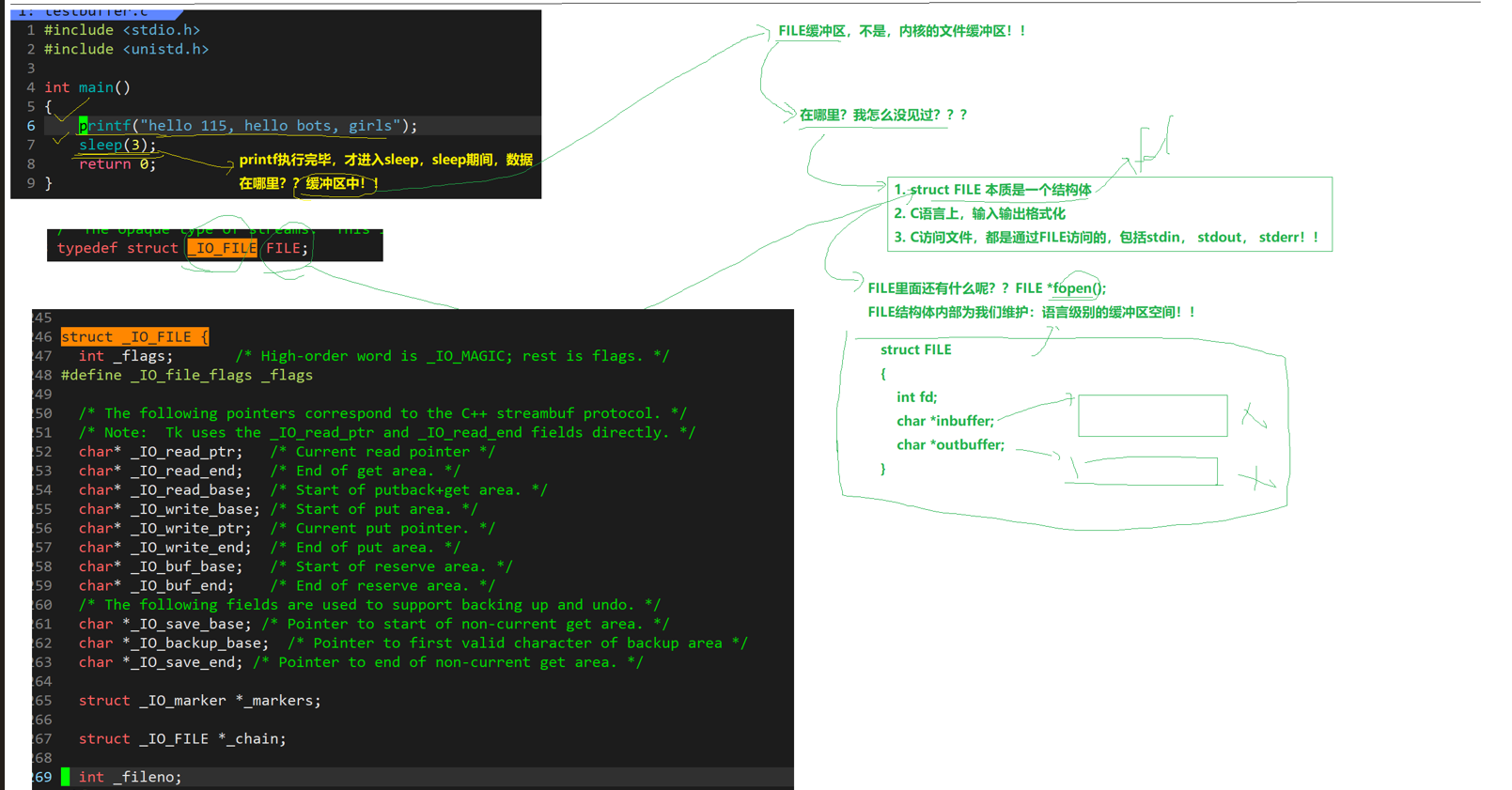
我们这个FILE这个缓冲区它是语言级别的,和内核缓冲区没半毛钱关系,这个缓冲区在FILE内部实现的,那么我们闲的蛋疼吗?操作系统帮助我们实现了内核缓冲区,为啥我们自己还要来实现一个语言级别的缓冲区呢?费劲,当然是因为减少的IO次数,我们的系统调用是有成本的,为了减少系统调用的次数,我们设计了这个缓冲区,FILE加速函数的IO效率,提高了C接口下的IO效率,那么我们的单位时间内执行C语言代码的行数是不是变多了?效率是不是变高了?
下来我们重新理解一下我们以前说的格式化函数,格式化到哪里去了?printf是我们C语言提供的,肯定先格式化到语言级别的缓冲区,检测是否需要刷新到内核的缓冲区,需要的话我们再进行write进行写入。
我们内核对于文件缓冲区的刷新方式是普通文件全缓冲,显示器文件行缓存
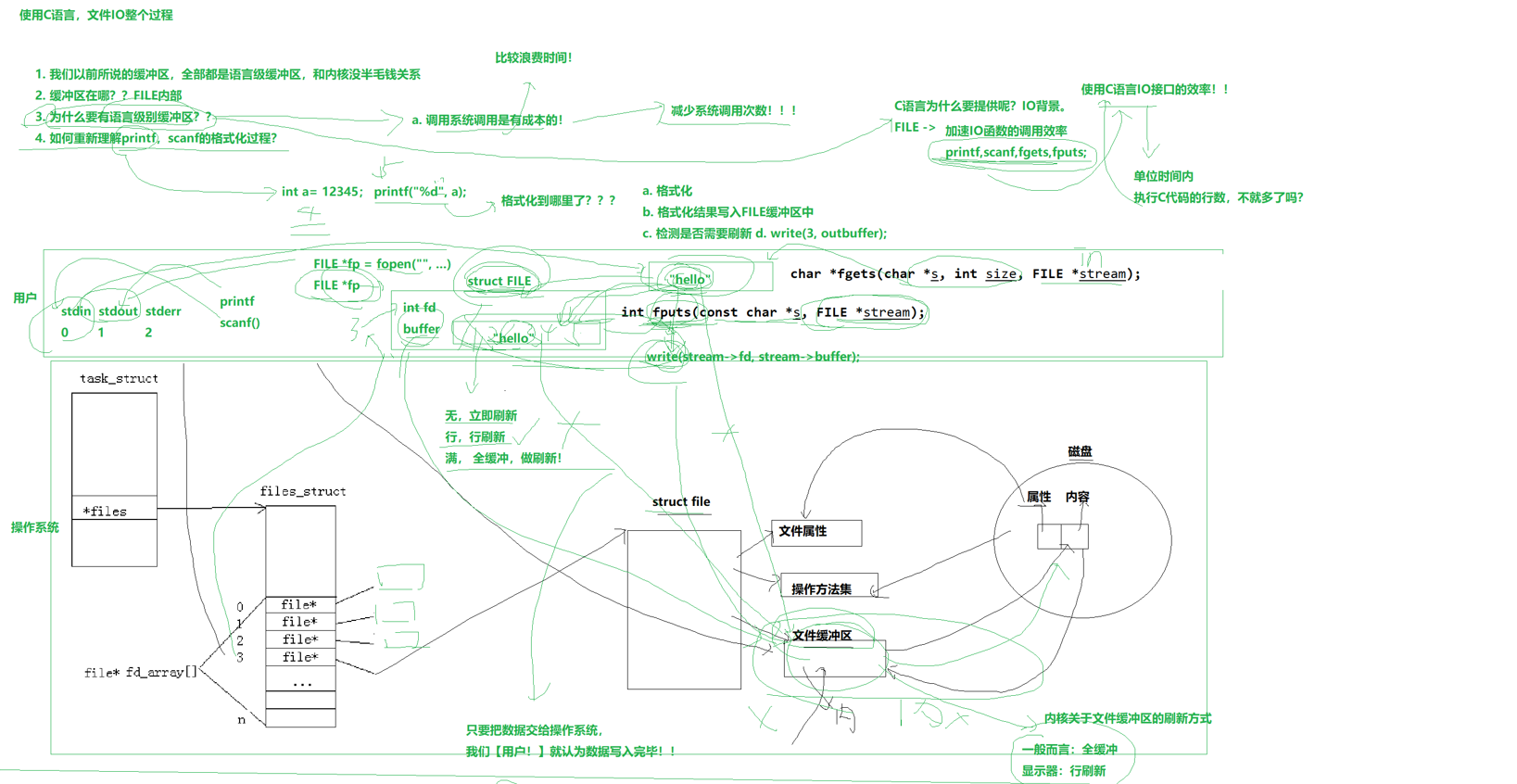
int main()
{
const char *msg0="hello printf\n";
const char *msg1="hello fwrite\n";
const char *msg2="hello write\n";
printf("%s", msg0);
fwrite(msg1, strlen(msg0), 1, stdout);
write(1, msg2, strlen(msg2));
fork();
return 0;
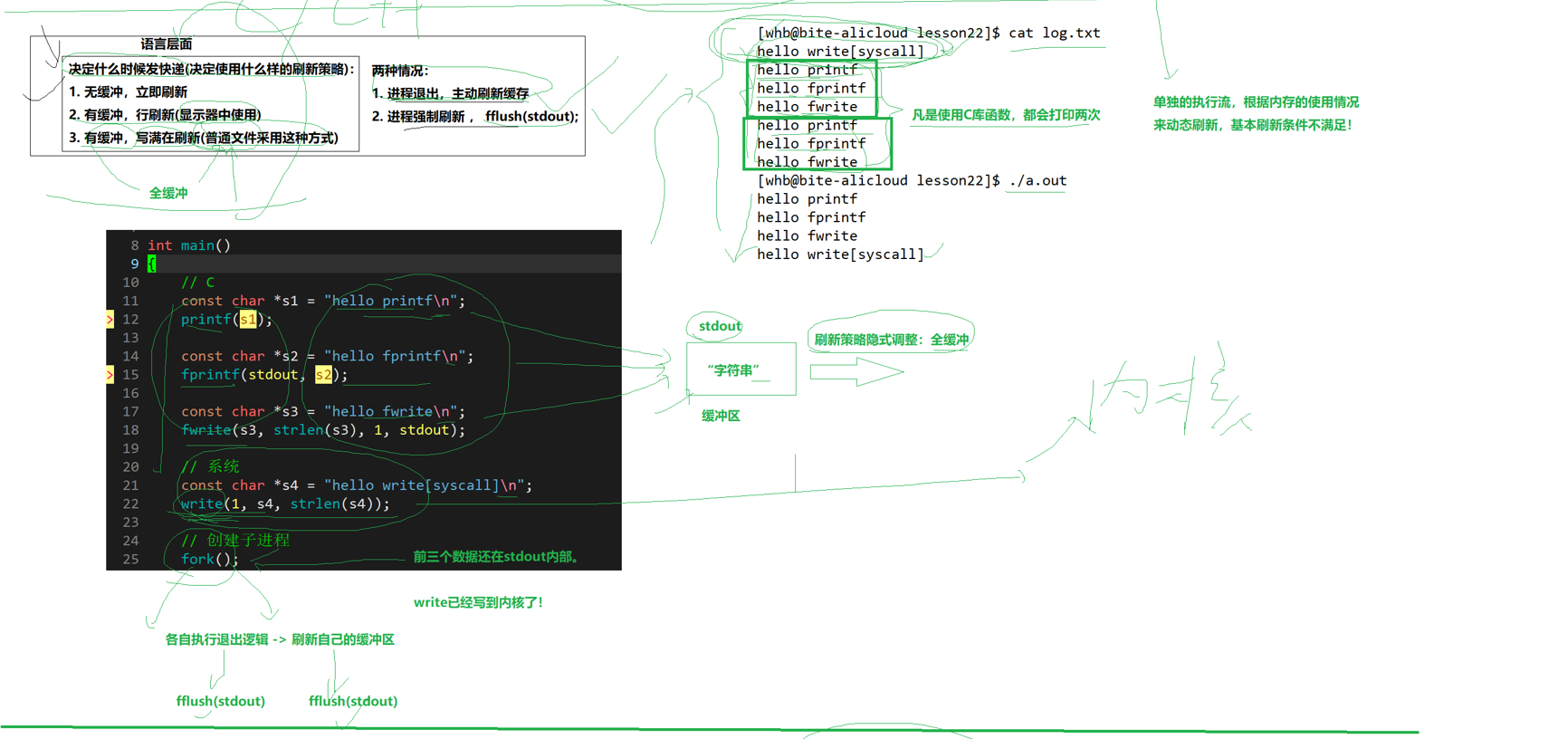
}我们来看上面这段代码,我们假如是运行这个进程就是依次打印,但是如果我们进行文件的重定向就会发生别的事情。我们来分析一下,我们原来是往屏幕进行写入,我们的刷新策略是行刷新,那我进行重定向的时候就是全缓存了。
printf和fwrite是我们的C语言提供的函数,所以它有语言级别的缓冲区,我们使用这个函数会先往语言缓冲区里去写,但是我们的write是往内核里写,它不会在我们的语言缓冲区里停留,但是我们的printf和fwrite可是会在C的库里面停留的,当我们创建子进程之后,我们的子进程语言缓冲区里也有一份相同的数据,当它进程结束,然后我们的父子进程各有一份内容,造成重复刷新!!!至此我们明白了一个问题就是当我们stdout进行重定向的时候,当它输出到屏幕,它的刷新策略是行,当定向到普通文件时,它的刷新策略就是全缓冲刷新,这里的缓冲都是我们的语言级别用户层面,如果我们直接write可以认为是直接写到内核里了,并且不会被子进程继承,我们可以认为当我们的数据交给内核时,就不需要关心了,子进程也不会去继承文件的内核缓冲区!!!但子进程会继承我们FILE语言级别缓冲区里面的数据,fflush是强制刷新,出现数据重复!!!
关键在于,我们的内核缓冲区是全局的,而语言级别缓冲区是会被子进程继承完全相同的一份的!!!然后我们重定向会改变我们的刷新策略,至此我们明白了同一份代码输入到屏幕上和输入到文件里为什么不一样了!!!
充分理解这个案例可以帮助我们很好的掌握刷新策略和父子进程的进一步认识,对与缓冲区有进一步的认识!!!


我们还有一个命令是fsync,这个玩意一看长的就像系统调用啊!用了fd这个文件描述符,它和我们的fflush的区别是,fflush是直接把数据刷到文件缓冲区的内核里去,但是我们的fsync是直接把我文件缓冲区内核的数据刷到外设里!!!头文件上unistd.h

我们日常进行重定向是这么写/a.out >log.txt,这个作用是我们//a.out执行的程序打印到屏幕上的内容搞到屏幕上,实际上我们这里省略了一个1,应该是这么的./a.out 1 >log.txt,如果未来我们想要把我们的错误搞到文件里把1变成2,就会把看到我们的所有错误信息!!!
至此我们应该彻底搞明白了操作系统下我们的文件重定向到底是怎么完成的?它的缓存工作是如何做的!这对我们理解操作系统有莫大的帮助!
我们到目前为止讲述的都是打开的文件怎么怎么的,那我们磁盘里还有大量未打开的文件,我们还没有认识,下面我们就需要对未打开的文件进行认识,认识磁盘对文件的管理方式哦!!!

















 2412
2412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









