






scrapeghost入门学习资料 - 基于GPT的实验性网页抓取库
scrapeghost是一个实验性的Python库,旨在利用OpenAI的GPT API来进行网页抓取。它提供了一种无需编写页面特定代码就能从HTML中提取结构化数据的方法。如果你对使用AI进行网页抓取感兴趣,scrapeghost是一个值得关注的项目。本文汇总了scrapeghost的主要学习资源,帮助你快速入门并深入了解这个有趣的工具。
🌟 项目概览
- GitHub仓库: GitHub - jamesturk/scrapeghost: 👻 Experimental library for scraping websites using OpenAI's GPT API.
- 文档: scrapeghost
- PyPI: scrapeghost · PyPI

📚 核心功能
-
基于Python的schema定义 - 可以使用任意Python对象定义要提取的数据结构。
-
预处理
- HTML清理 - 移除不必要的HTML标签和属性,减少API请求的大小和成本。
- CSS和XPath选择器 - 通过单个CSS或XPath选择器预过滤HTML。
- 自动分割 - 可选择将HTML分割成多个调用,允许抓取更大的页面。
-
后处理
- JSON验证 - 确保响应是有效的JSON。
- Schema验证 - 使用
pydantic模型验证响应。 - 幻觉检查 - 验证响应中的数据是否真实存在于页面中。
-
成本控制
- 跟踪已发送和接收的token数量,以便追踪成本。
- 支持自动回退(例如默认使用成本较低的GPT-3.5-Turbo,需要时回退到GPT-4)。
- 允许设置预算,并在超出预算时停止抓取。
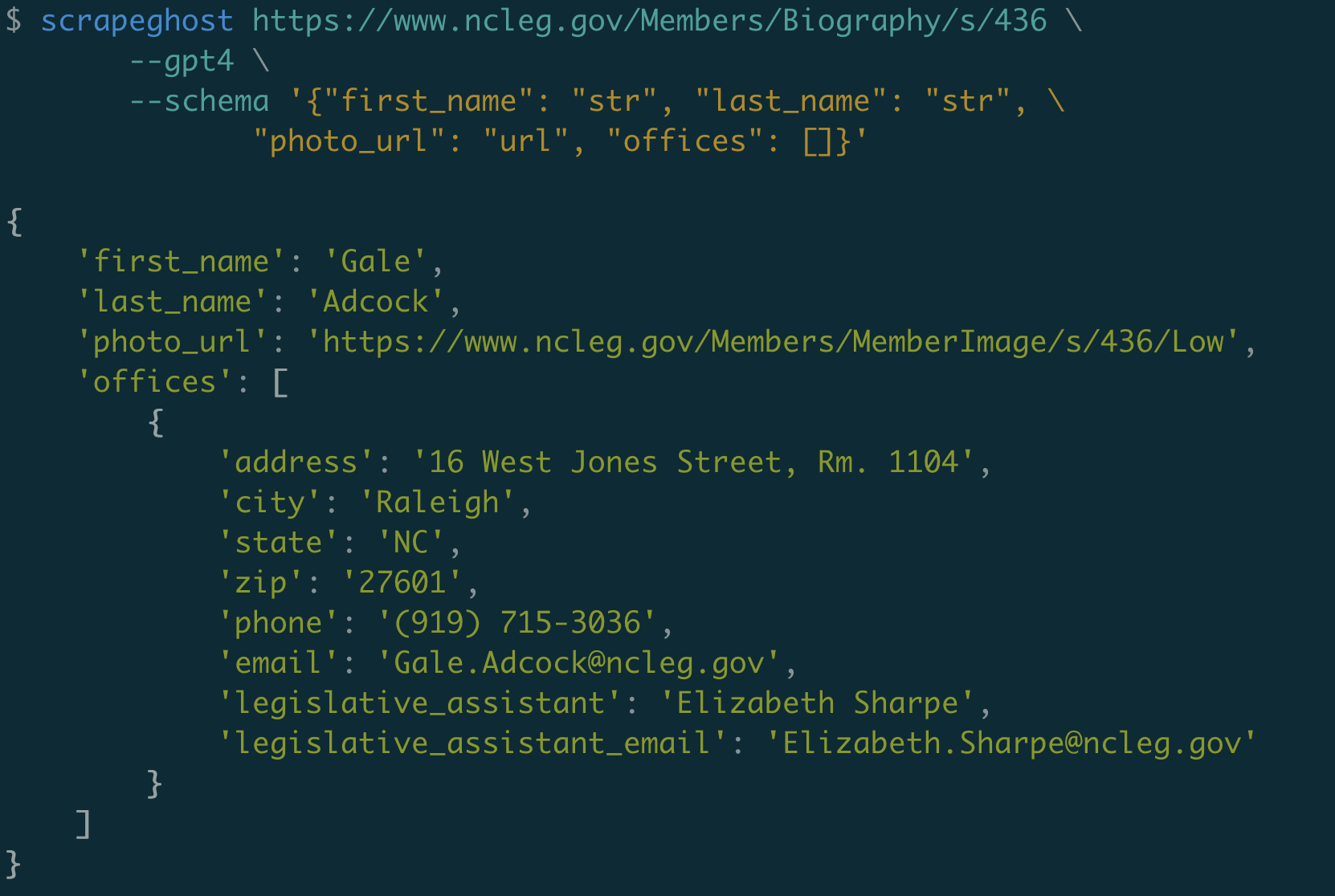
🚀 快速开始
- 安装scrapeghost:
pip install scrapeghost
- 设置OpenAI API密钥:
export OPENAI_API_KEY=sk-...
- 创建一个简单的抓取器:
from scrapeghost import SchemaScraper
scrape_legislators = SchemaScraper(
schema={
"name": "string",
"url": "url",
"district": "string",
"party": "string",
"photo_url": "url",
"offices": [{"name": "string", "address": "string", "phone": "string"}],
}
)
result = scrape_legislators("https://www.ilga.gov/house/rep.asp?MemberID=3071")
print(result.data)
📖 深入学习
- 教程 - 逐步指导构建一个抓取器
- 使用指南 - 详细介绍scrapeghost的各项功能和用法
- API参考 - 完整的API文档
- 命令行界面 - 了解如何使用scrapeghost的CLI工具
- 常见问题 - 解答使用过程中的常见疑问
⚠️ 使用注意
scrapeghost是一个实验性项目,在使用时请注意以下几点:
- API的稳定性和结果的准确性不做保证。
- 依赖OpenAI API,速度较慢且可能较贵(一个中等大小页面的GPT-4调用约$0.36)。
- 目前采用Hippocratic License 3.0许可证。
🤝 参与贡献
如果你对scrapeghost感兴趣并希望做出贡献,可以通过以下方式参与:
- 在GitHub上提交问题或pull requests
- 加入项目讨论
- 关注项目的更新日志
scrapeghost为探索基于GPT的网页抓取提供了一个有趣的平台。无论你是想尝试新技术,还是寻找更智能的网页数据提取方法,scrapeghost都值得一试。希望这篇资源汇总能帮助你更好地了解和使用这个项目。祝你使用愉快!
文章链接:www.dongaigc.com/a/scrapeghost-introduction-gpt
https://www.dongaigc.com/a/scrapeghost-introduction-gpt















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









