






DiffSinger:开创歌声合成新纪元
近年来,人工智能技术在语音合成领域取得了长足的进步。作为语音合成的一个重要分支,歌声合成一直是研究人员关注的热点。最近,来自浙江大学的研究团队提出了一种名为DiffSinger的新型歌声合成模型,通过创新性地引入浅层扩散机制,在合成音质和表现力方面都取得了显著的提升。本文将详细介绍DiffSinger的核心原理、主要特点以及应用前景。
DiffSinger的核心原理
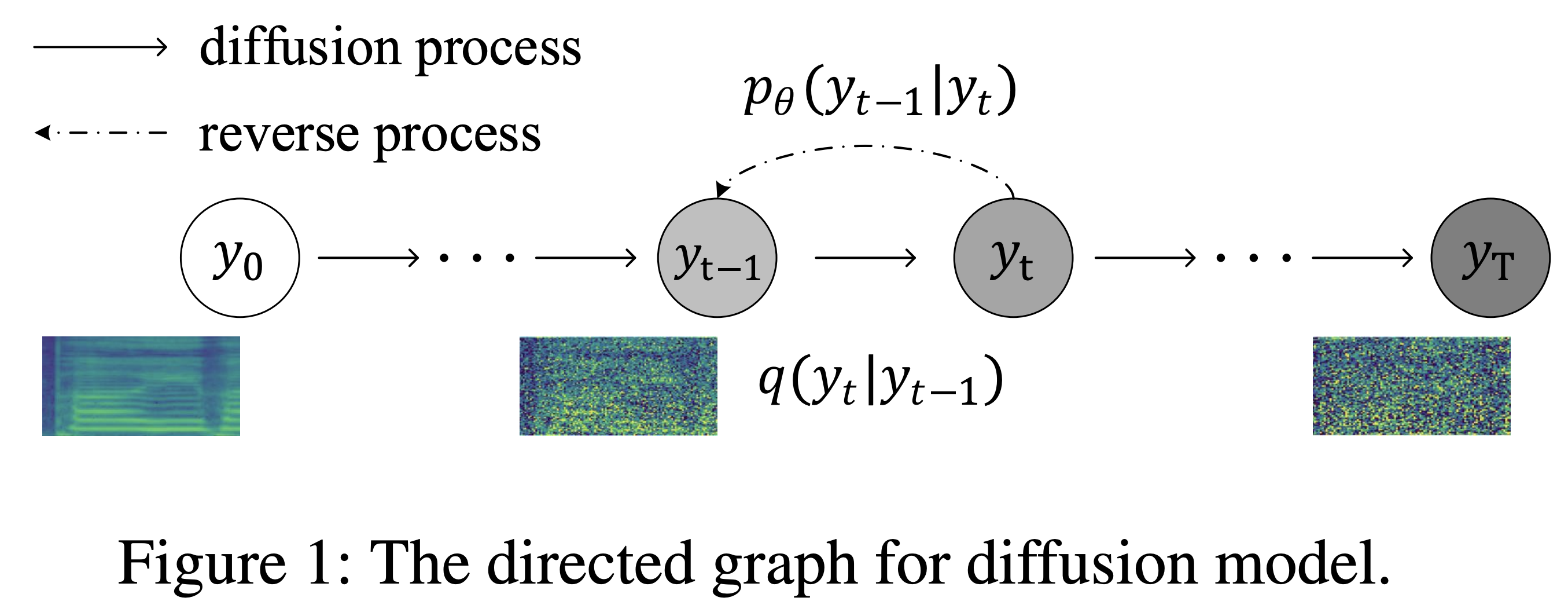
DiffSinger的核心思想是将扩散概率模型应用于歌声合成任务。具体来说,DiffSinger是一个参数化的马尔可夫链,可以在给定音乐谱的条件下,将噪声逐步转化为梅尔频谱图。这一过程可以分为以下几个关键步骤:
-
首先,模型会根据输入的音乐谱生成一个初始的噪声信号。
-
然后,通过多次迭代,模型逐步将噪声信号转化为目标梅尔频谱图。每一步迭代都会利用前一步的结果,并结合音乐谱的信息进行优化。
-
最后,通过声码器将生成的梅尔频谱图转换为波形,得到最终的合成音频。
这种基于扩散的方法相比传统的生成对抗网络(GAN)或自回归模型,具有更好的稳定性和生成质量。
DiffSinger的主要特点
DiffSinger具有以下几个突出的特点:
-
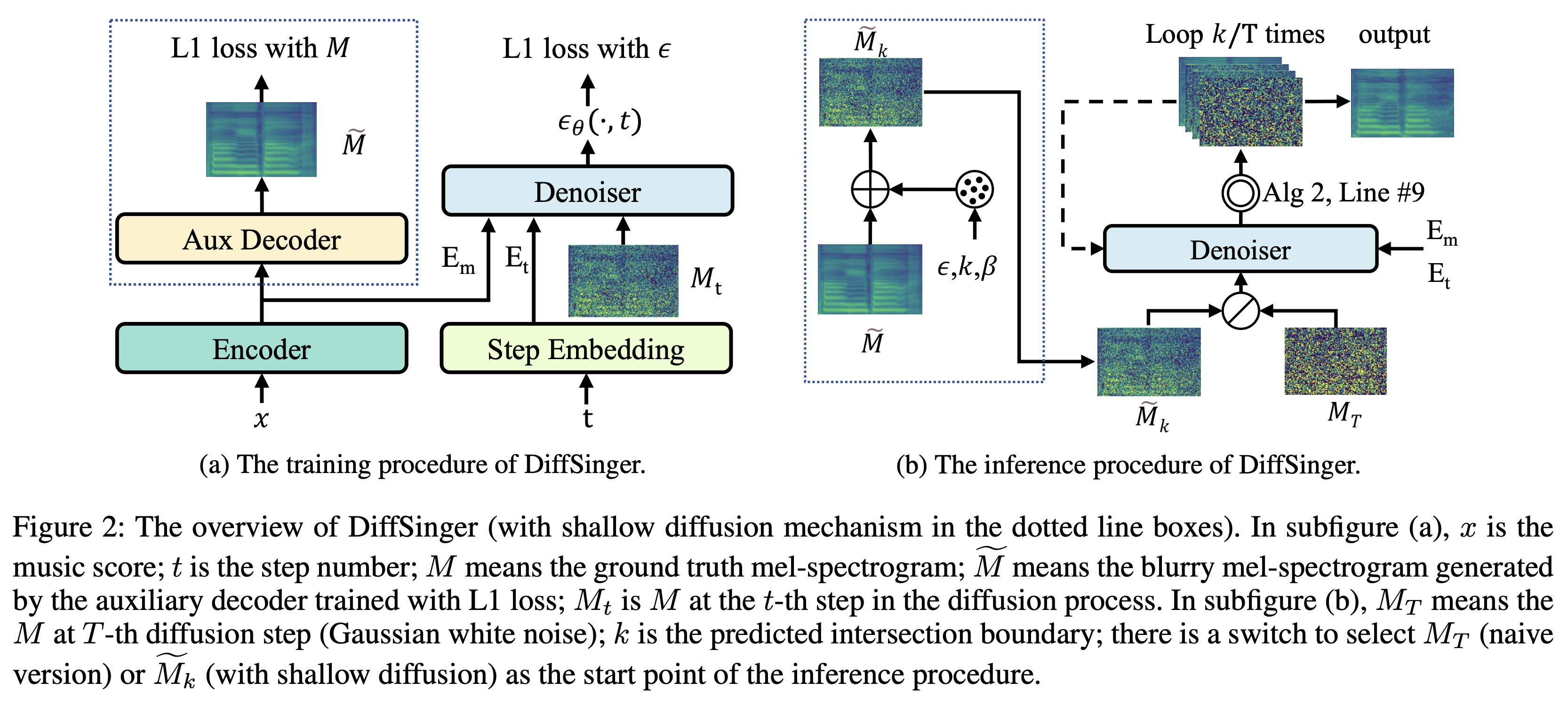
浅层扩散机制: DiffSinger引入了一种创新的浅层扩散机制,可以更好地利用简单损失函数学到的先验知识。这种机制从一个浅层步骤开始生成,而不是从完全的噪声开始,从而提高了生成效率和质量。
-
边界预测: DiffSinger提出了边界预测方法,可以自适应地确定浅层扩散的起始步骤。这种方法能够在保证生成质量的同时,显著提高推理速度。
-
多功能性: 虽然DiffSinger最初是为歌声合成设计的,但它也可以应用于普通的文本到语音(TTS)任务。这种灵活性使得DiffSinger在语音合成领域具有广泛的应用潜力。
-
高质量输出: 通过隐式优化变分界,DiffSinger能够稳定地训练并生成逼真的输出。实验结果表明,DiffSinger在合成音质和表现力方面都优于现有的最先进方法。
DiffSinger的应用与前景
DiffSinger的出现为歌声合成和语音合成领域带来了新的可能性。以下是一些潜在的应用场景:
-
虚拟歌手: DiffSinger可以用于创建高质量的虚拟歌手,为音乐创作者提供更多的创作素材和可能性。
-
个性化语音助手: 通过DiffSinger,可以为语音助手赋予更自然、更富表现力的声音,提升用户体验。
-
配音和dubbing: 在影视制作和游戏开发中,DiffSinger可以用于生成高质量的配音和dubbing,降低制作成本。
-
语音修复: DiffSinger的技术也可以应用于修复和增强低质量的语音录音。
-
语音转换: 通过适当的训练,DiffSinger有潜力实现高质量的语音转换,如说话人转换或情感风格转换。
结语
DiffSinger的出现标志着歌声合成和语音合成技术的一个重要里程碑。通过创新的浅层扩散机制,DiffSinger不仅提高了合成音质,还为语音合成领域带来了新的研究方向。随着技术的不断发展和完善,我们可以期待在不久的将来,DiffSinger及其衍生技术将在更广泛的领域发挥重要作用,为人工智能语音交互带来革命性的变革。
作为一个开源项目,DiffSinger也为研究人员和开发者提供了宝贵的学习和实验平台。相信在社区的共同努力下,DiffSinger将继续evolve,为语音合成技术的进步做出更大的贡献。
文章链接:www.dongaigc.com/a/diffsinger-shallow-diffusion-voice-synthesis
https://www.dongaigc.com/a/diffsinger-shallow-diffusion-voice-synthesis


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









