







Solo Performance Prompting: 释放大型语言模型的认知协同效应
在人工智能和自然语言处理领域,大型语言模型(Large Language Models, LLMs)的出现彻底改变了我们与机器交互的方式。这些模型展现出惊人的语言理解和生成能力,但在处理复杂任务时仍然面临挑战。为了进一步提升LLMs的能力,研究人员一直在探索新的方法。最近,一种名为Solo Performance Prompting (SPP)的创新方法引起了广泛关注。
SPP的核心理念
Solo Performance Prompting的核心理念是通过让单个大型语言模型扮演多个不同角色,进行自我协作来解决复杂任务。这种方法借鉴了人类在面对困难问题时常用的思考方式 - 从不同角度和专业领域来分析问题。SPP将这种多角度思考的能力赋予了AI模型,使其能够更全面、更深入地处理复杂任务。
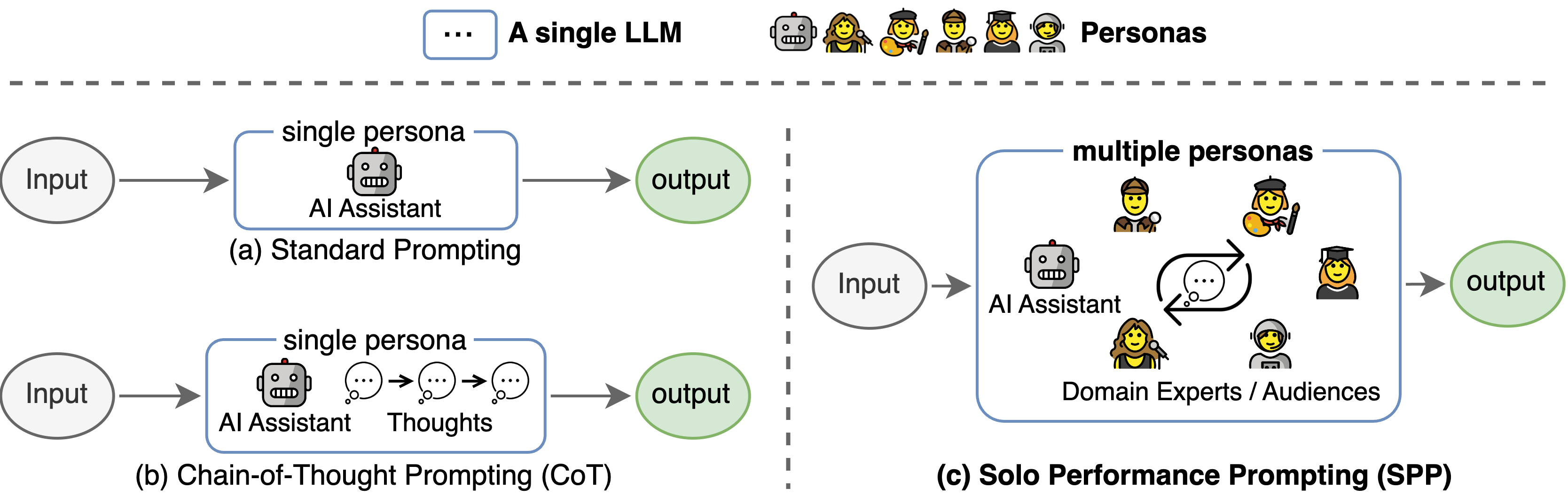
SPP的工作原理
-
角色定义: 根据任务需求,为语言模型定义多个不同的角色或"personas"。每个角色都有特定的专业背景和思考方式。
-
多轮对话: 模型依次扮演这些角色,进行多轮对话。每个角色都会根据自己的"专业"对问题提供独特的见解。
-
信息整合: 通过多轮对话,模型能够从不同角度收集信息和想法,形成更全面的理解。
-
最终决策:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









