







相关知识点:webpack
博客配套代码发布于github:得物案例
相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例
这个案例主要展示如何对得物网站的 API 请求签名进行逆向分析,并使用 Python 和 JavaScript扣去相应js代码来生成签名,从而成功抓取数据。
一、初始爬取工作准备
1.确定爬取数据位置
访问网址得物 可以看到该页面的商品数据展示,按F12打开开发者工具,在network中选择Fetch/XHR,并刷新页面,得到如下信息:
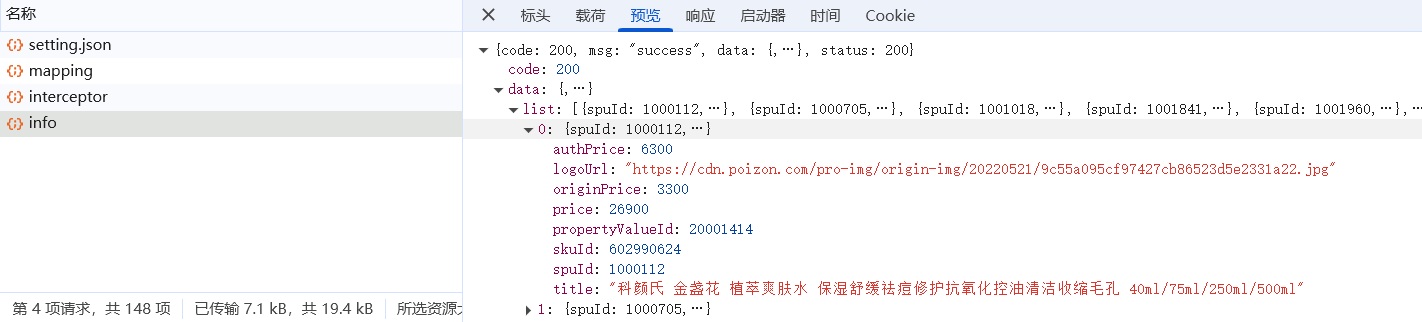
粗略观察后确定info为目标请求url,涵盖我们所需的商品数据
2.确定爬虫的初始参数
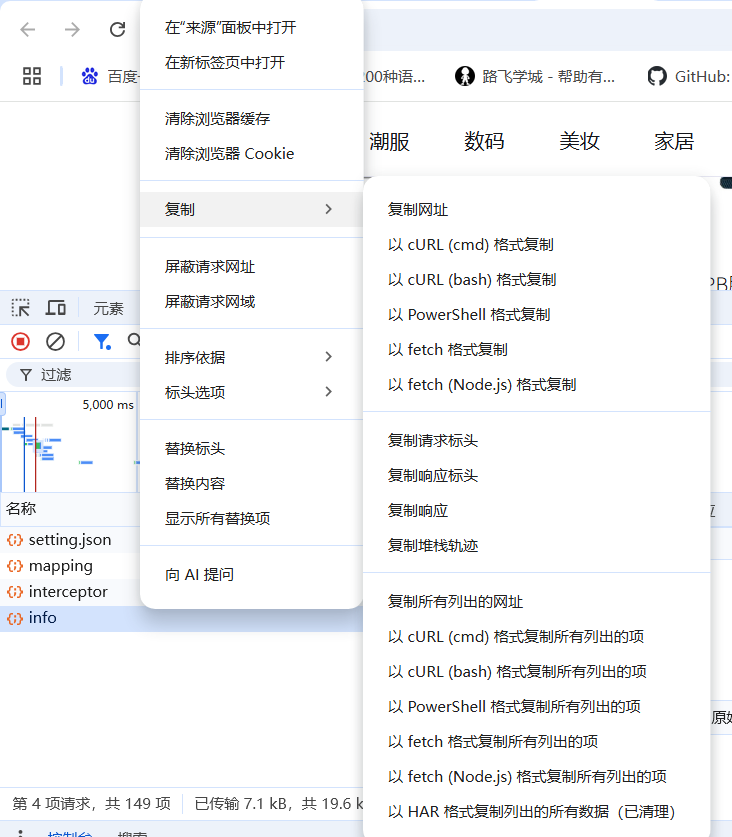
对该info选中复制,并以curl(bash)格式复制,粘贴到Convert curl commands to Python,可得详细所需的爬虫参数:

直接将其copy到pycharm中,并在末尾加个print(response.text)查看输出结果
![]()
确认请求没问题,开始分析请求参数。
二、逆向难点思路分析

很明显,其中的sign大概率就是那个我们所要破解的加密参数,而pycharm中对sign注释也会提示无法正确请求。这时我们选中sign其中的值,发现是32个字符且是(0-9)与(a-f)组成,基本可以推断出是md5算法,由此我们便可以进行之后对sign值的逆向。
三、破解逆向
1.找到sign值入口
在开发者工具中输入sign:,并找到其中的声明式相关↓
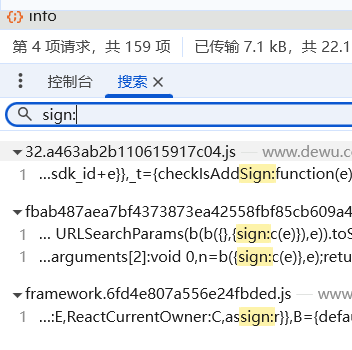 ,明显是中间两项相关,进去并为两者打上断点进行下步调试:
,明显是中间两项相关,进去并为两者打上断点进行下步调试:
刷新页面,卡在第二个断点处,但并不能确定此处就是我们所要的请求位置,![]() 这里发现t不是info,就再次顺到下个断点
这里发现t不是info,就再次顺到下个断点![]() ,这里是Info,确认请求位置没问题。
,这里是Info,确认请求位置没问题。
2. 分析sign的具体逻辑
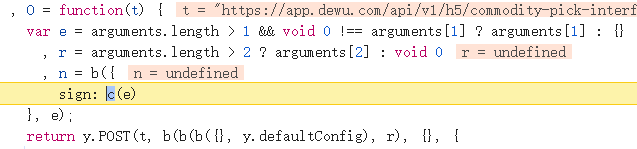
这里生成sign得知道c()与e,在控制台打印下e:
确定其为相关传入参数,没有问题。
接着看c(),选中被断点的c并看上层栈:

这里c(t)就是对应位置,所以直接将其整个copy到我们的pycharm中的新文件dewu.js,再进行下步操作
3.扣代码并还原相关算法
我们把代码扣过来后,再写个data=刚才的e,为其试用data(e)发现![]() ,接着找u在哪
,接着找u在哪

如图,看到r("xxxx")基本确定是webpack相关,r为加载器,r("xxxx")为加载器调用。
a:断点a=(x,y,z)并跳到r加载器的上层:乍一看这里代码很乱,但不要急,直接跳到最上层并缩进代码,便能发现这是个单文件的自执行函数。这里就涉及到webpack非常重要的语法与爬虫中所处理的步骤,推荐在这里了解相关,此处不再赘述原因。

把上面整段扣过来再放进新js文件loader,并在最上方添加一个window=global,目的是让代码在不同环境中都能访问到全局变量

如图:这里再在之前加载器上层跳过来的位置处加入log,打印r观察缺什么,并为window.loader赋值上面函数的那个a--加载器函数,结束这里的导入逻辑。
在得物.js输入require('./loader')
接着输入console.log(window.loader)测试,没有报错
接着把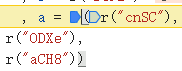 拷过来并改写成
拷过来并改写成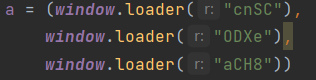 的格式,发现报错:无cnsc
的格式,发现报错:无cnsc
于是接着搜索cnsc:找到 再观察这个文件的格式
再观察这个文件的格式![]() 还是webpack,这就不客气了,直接输入全部复制粘贴到新js文件,并再度require过来。
还是webpack,这就不客气了,直接输入全部复制粘贴到新js文件,并再度require过来。
同理,第二个ODXe报错也是用上述方式解决。
最终dewu.js中没有报错,运行成功
4.生成最终sign
把当前代码中的json_data作为参数传入给dewu.js,并将生成的最终sign值返回↓
![]()
 如图,请求成功,逆向完成。
如图,请求成功,逆向完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









