







相关实战案例:爬虫实战之具体爬取流程--text 爬虫实战之具体爬取流程--json型
相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例
一、数据解析是什么
将爬取到的数据中指定的数据进行单独提取,即我们常讲的数据清洗。因为正常我们所获取到的数据大多混乱无序,需要我们对其进行系统解析,将其转化成有价值的数据。
二、数据解析的通用流程
在开发者工具中的数据包里确认关键响应参数:Content-type:
![]()
![]()
它代表了该数据包是以何种方式传递,前者代表数据类型,后者则代表编码格式,这里我们主要看前者:
通常而言,想爬取的格式会分为以上两大类text/json,其他格式爬取难度与数量相对少很多,不做过多涉及。而对于数据解析而言,这是非常重要的判断工具:
据此,我们就能确定我们接下来需要用何种方式来处理。
三、处理常见的数据类型(按content-type区分text与json)
1.文本型(text/html)
此种类型一般是返回整个html界面,开发者工具中的预览与一般见到的是整个页面,保存并打印获取到的数据也能看到是个完整的html格式文件:
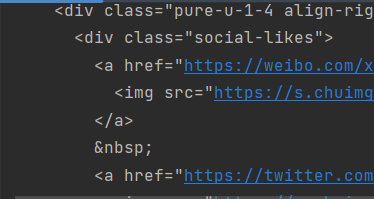
这种文本数据就要求我们必须学会一些数据解析工具,这里主要介绍xpath。正则的上手门槛较高,而beautifulSoup 更适合小型、静态、结构规整的页面,使用场景少。故这两者不做过多涉及。
xpath如何使用:
编码流程:1. 创建一个etree类型的对象并把被解析到的数据加载到该对象中
2. 调用etree对象中的xpath函数,结合不同的xpath表达式进行数据提取
代码流程:
from lxml import etree
with open('xx.html','r',encoding='utf8') as f:
x = f.read() # 获取HTML文档对象
# 这里的xx.html文件是通过常规请求获取的,
# 所以你也可以在下面的('x')里将其替换成response的值
tree = etree.HTML('x') # 解析字符串格式的HTML文档对象
rets = tree.xpath('zz/text()') # xpath内为的zz为属性选择器,/text()则是选取这个标签对应的值
print(rets)而xpath语法最主要学习点的就是上图中zz的部分,懂得这个地方的属性选择器的写法,并记住上面的流程就学会了xpath。
我们现在通过一个豆瓣案例来实际理解下:
import requests
from lxml import etree
url = 'https://movie.douban.com/top250'
header = {'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36'}
response = requests.get(url,headers=header).text
tree = etree.HTML(response)
title = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]/text()')[0]
print('第一部电影:',title)如上,这里tree.xpath()就选择了页面中"肖申克"这个元素来进行选中,并最终打印
xpath语法
路径表达式 | 描述 | 实例 | 解析 |
| :----- | :------------------------------------------------------- | -------------- | ----------------------------------- |
| / | 从根节点选取 | `/body/div[1]` | 选取根结点下的body下的第一个div标签 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 | `//a` | 选取文档中所有的a标签 |
| ./ | 当前节点再次进行xpath | `./a` | 选取当前节点下的所有a标签 |
| @ | 选取属性 | `//@class` | 选取所有的class属性
.// 当前节点下,子孙的标签.
谓语
| /ul/li[1] | 选取属于 ul子元素的第一个 li元素。 |
| /ul/li[last()] | 选取属于 ul子元素的最后一个 li元素。 |
| /ul/li[last()-1] | 选取属于 ul子元素的倒数第二个 li元素。 |
| //ul/li[position()<3] | 选取最前面的两个属于 ul元素的子元素的 li元素。 |
| //a[@title] | 选取所有拥有名为 title的属性的 a元素。 |
| //a[@title='xx'] | 选取所有 a元素,且这些元素拥有值为 xx的 title属性。 |
| //a[@title>10] `> < >= <= !=` | 选取a元素的所有title元素,且其中的 title元素的值须大于10。 |
| /body/div[@price>35.00] | 选取body下price元素值大于35的div节点 |
//*[@id="content"]/div/div[1]/div/div/table[1]/tbody/tr/td[2]/div/a (复制xpath)
/html/body/div[3]/div[1]/div/div[1]/div/div/table[1]/tbody/tr/td[2]/div/a(复制完整的xpath)除了使用上述语法,自己写对应xpath以外,开发者工具还提供给我们更加简便的做法:

选择左边这个蓝色箭头,再点击我们想要的元素(肖申克的救赎),就会自动跳转到对应html元素位置。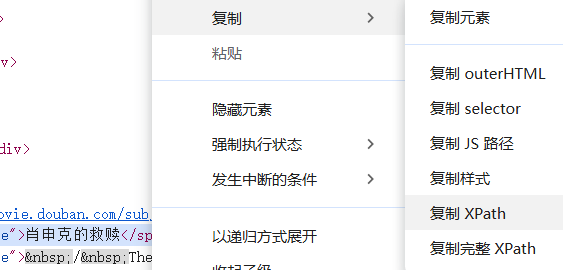
这里直接复制xpath,再放到tree.xpath()内即可
处理文本型(text)实战案例:爬虫实战之具体爬取流程--text
2.json型(application/json)
json数据包常见于数据动态加载,渲染到页面上的场景。相应的,json数据在排版上通常会更友好,其格式类似py里的字典,方便我们直接对数据进行整理,无需xpath等工具做初步筛选。
如右图所示,仅需简单的py处理即可得到对应数据。
处理json型(json)实战案例:爬虫实战之具体爬取流程--json型
四、小结
做数据分析,首先分析网站的Content-type,再根据text/json选择相应的处理方式。
对于text类的静态网站一般爬取难度较小,而json类的动态网站通常访问量会更大,也会涉及更高级别的反爬,需要我们具体网站具体分析。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









