







在全球化浪潮的推动下,不同国家、民族之间的交流日益频繁,语言障碍成为信息流通和文化传播的一大阻碍。机器翻译作为跨越语言鸿沟的重要工具,经历了从基于规则的传统方法到统计机器翻译,再到如今深度学习驱动的重大变革。深度学习技术凭借强大的表征学习能力,彻底改变了机器翻译的面貌,使翻译质量得到显著提升。本文将深入探讨机器翻译领域中深度学习技术的发展历程、最新进展,详细解析主流翻译模型架构及其训练方法,并分享在处理不同语言对、专业领域翻译时的优化策略与实践经验,揭示 AI 如何打破语言障碍,重塑全球语言交流格局。
一、机器翻译中深度学习技术的发展历程
(一)传统机器翻译方法的局限
早期的机器翻译主要依赖基于规则的方法,语言学家通过人工编写大量的语法规则和词汇对照表,试图将源语言按照既定规则转换为目标语言。然而,这种方法存在诸多弊端。自然语言的复杂性极高,语言规则千变万化,难以用有限的规则完全覆盖所有语言现象。同时,不同语言之间的语法结构、词汇语义差异巨大,人工编写规则的成本极高且效率低下,面对新的语言表达或领域专业术语时,基于规则的机器翻译系统往往束手无策。
随后出现的统计机器翻译方法,利用大规模的双语平行语料库,通过统计分析计算源语言和目标语言之间的对应概率,从而生成翻译结果。虽然相比基于规则的方法,统计机器翻译在一定程度上提高了翻译的准确性和泛化能力,但它仍然存在缺陷。统计机器翻译将语言看作一个个孤立的单词或短语,忽略了句子的整体语义和上下文信息,导致翻译结果在语法和语义上常常不够连贯和准确。
(二)深度学习在机器翻译中的崛起
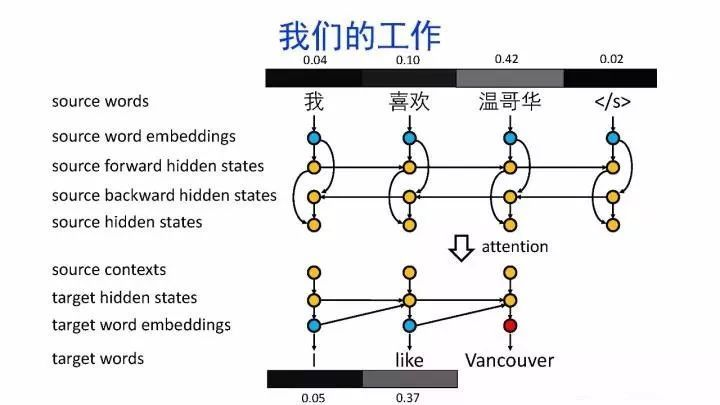
2013 年,深度学习开始逐渐应用于机器翻译领域,以循环神经网络(RNN)及其变体长短期记忆网络(LSTM)和门控循环单元(GRU)为代表的神经网络模型,为机器翻译带来了新的突破。RNN 能够处理序列数据,通过隐状态传递上下文信息,使得机器翻译模型能够更好地捕捉句子的语义结构。LSTM 和 GRU 则通过引入门控机制,解决了 RNN 在处理长序列时的梯度消失和梯度爆炸问题,进一步提升了模型对长句和复杂句子的处理能力。
基于 RNN 的编码器 - 解码器(Encoder - Decoder)架构成为当时机器翻译的主流模型。编码器将源语言句子编码为一个固定长度的向量表示,解码器再从这个向量中解码出目标语言句子。这种架构使得机器翻译能够利用神经网络的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









