







https://github.com/cxcscmu/InContextDataAttribution 源码
目录
这段代码主要用于分析两种分数:ICP分数(上下文预测分数)和影响分数(影响力分数),并提供一些功能,如分数可视化、Spearman相关性分析、按排名分类分数、以及ICP和影响分数在不同分数区间内的重叠分析。
1. 主要功能
绘制icp 或 influence score 分数分布
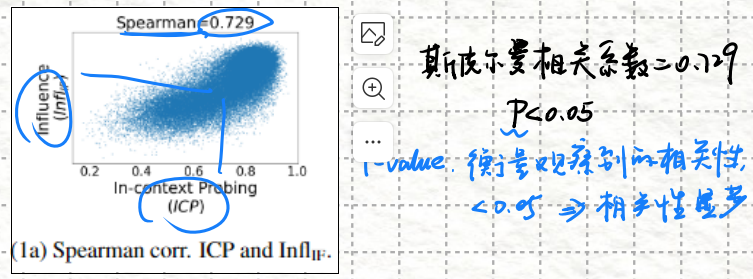
Spearman相关系数分析:计算ICP分数和影响分数之间的Spearman等级相关性。
ICP分数的分类:将ICP分数按照不同的区间分类(例如:>0.9, >0.8等)。
ICP和影响分数的重叠分析:分析ICP和影响分数在不同分数区间内的重叠情况,来评估它们的关系。

2. 代码
2.1 读取文件路径和命令行参数
data_dir = join(dirname(dirname(abspath(__file__))), "data/scores")
parser = argparse.ArgumentParser()
parser.add_argument("--icp_score_path", default=join(data_dir, "data/scores/icp_scores.json"), type=str,
help="path to icp scores")
parser.add_argument("--infl_score_path", default=join(data_dir, "data/scores/infl_ip.json"), type=str,
help="path to influence scores")
args = parser.parse_args()
data_dir变量定义了一个相对路径指向数据所在的文件夹data/scores。
ICP分数的路径:--icp_score_path
{"0": [0.85], "1": [0.7], "2": [0.87], "3": [0.86], "4": [0.89], "5": [0.73], "6": [0.88], "7": [0.85], "8": [0.82], "9": [0.76], ...... }
影响分数的路径:--infl_score_path
2.2 读取 JSON 文件
def read_json_file(path):
with open(path) as f:
data = json.load(f)
return data读取给定路径的JSON文件,解析并返回数据。
2.3 读取影响分数(PyTorch 张量文件)
def read_infl_scores(path):
scores = torch.load(path, map_location=torch.device('cpu')).numpy()
scores = np.mean(scores, axis=0)
return scores读取的是一个PyTorch保存的张量(infl_ip.json)PyTorch张量详解-CSDN博客,然后使用numpy()将其转为NumPy数组。
假设这个文件中保存了多维数据,这里通过np.mean(axis=0)对数据进行降维,得到每个样本的平均影响分数。
2.4 读取 ICP 分数(JSON 格式)
def read_icp_scores(path):
scores = read_json_file(path)
scores = np.array([scores[str(i)][0] for i in range(len(scores))])
return scores读取 icp_scores.json 文件中的数据,每个样本的ICP分数是以{[score]}的形式存储的(即每个ID对应一个包含单个分数的列表)。将这些分数转换为NumPy数组。
2.5 可视化函数:绘制分数分布
def plot_score_distribution(scores, outfile, title='', xlabel='', ylabel='') -> None:
"""
Sort scores and plot them
Args:
scores (List[float]): array of scores
title (str, Optional): plot title
xlabel (str, Optional): x-axis label
ylabel (str, Optional): y-axis label
outfile (str): path to save plot
Returns:
None
"""
scores = np.sort(scores)
x = list(range(len(scores)))
plt.scatter(x, scores, s=1)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
plt.title(title)
plt.tight_layout()
plt.savefig(outfile)
plt.clf()用于绘制分数的散点图。
分数首先进行升序排序,x轴表示样本的索引(排序后的),y轴表示ICP或影响分数。保存为图片文件。
2.6 分数分类函数:解析分类条件
def parse_inequality(op):
"""
Parse an inequality string
Args:
op (str): inequality string
Returns:
[op, n1, n2]: list of op (str), n1 (float), n2 (float)
"""
# return [op, n1, n2]
m = re.match(r'<=(0.[0-9]+)', op)
if m:
return ['<=', float(m.group(1)), None]
m = re.match(r'>(0.[0-9]+)', op)
if m:
return ['>', float(m.group(1)), None]
m = re.match(r'(0.[0-9]+)-([0-9]+.[0-9]+)', op)
if m:
return ['range', float(m.group(1)), float(m.group(2))]
return None这个函数用于解析给定的分类条件字符串(例如:<=0.5、>0.5 或 0.5 - 0.6)。它使用正则表达式将这些条件解析成相应的操作符(如<=)和数值(如0.5)。
2.7 ICP分数的分类(按区间)
def categorize_icp_scores(icp_scores, categories = ['<=0.5', '>0.5', '>0.6','>0.7', '>0.8', '>0.85', '>0.9', '>0.95']):
"""
Categorize icp scores into score bins.
Args:
icp_scores (List[float]): icp scores
categories (List[str]): score bins
Returns:
icp_bin_to_count (Dict[str, int]): number of prompts in each score bin
icp_bin_to_prompt_id (Dict[str, List[int]]): mapping of prompt ids to icp score bins
"""
icp_bin_to_prompt_id = defaultdict(list)
parsed_categories = [parse_inequality(category) for category in categories]
for prompt_id in range(len(icp_scores)):
score = icp_scores[prompt_id]
for category in categories:
[op, n1, n2] = parse_category(category)
if op == '<=' and score <= n1:
icp_bin_to_prompt_id[category].append(prompt_id)
if op == '>' and score > n1:
icp_bin_to_prompt_id[category].append(prompt_id)
if op == 'range' and n1 <= score <n2:
icp_bin_to_prompt_id[category].append(prompt_id)
icp_bin_to_count = {category : len(icp_bin_to_prompt_id[category]) for category in icp_bin_to_prompt_id}
return icp_bin_to_count, icp_bin_to_prompt_id将ICP分数按照指定的区间(例如:<=0.5、>0.5 )进行分类。每个区间会包含若干样本ID。返回的是每个区间样本数(icp_bin_to_count )和样本ID的映射icp bin to prompt id)
2.8 ICP和影响分数的重叠分析
def find_overlaps(icp_bin_to_prompt_id, infl_scores):
"""
Get overlapping points between influence and icp at different ranking bins.
Args:
icp_bin_to_prompt_id (Dict[str, str]): mapping of prompt ids to icp score bins
infl_scores (List[float]): influence scores
Returns:
None
"""
for category, prompt_ids in icp_bin_to_prompt_id.items():
if '<=' in category:
infl_scores_idxs = np.argsort(infl_scores)
else:
infl_scores_idxs = np.argsort(infl_scores)[::-1]
n = len(prompt_ids)
infl_scores_idxs = set(infl_scores_idxs[:n])
overlaps = infl_scores_idxs.intersection(prompt_ids)
print(f"Overlaps for {category} score bin: {len(overlaps)}/{n}")对于每个ICP分数的区间,分析该区间与影响分数的重情况。对于<=类的ICP分数区间,影响分数按升序排列;对于其他区间,则按降序排列,找出前n个样本并计算交集,输出交集的大小。
2.9 相关性分析函数:Spearman 等级相关
def icp_influence_spearman(icp_scores, influence_scores):
"""
Spearman correlation between icp and influence scores.
Args:
icp_scores (List[float]): icp scores
influence_scores (List[float]) influence_scores
Returns
None
"""
res = stats.spearmanr(icp_scores, influence_scores)
correlation = round(res.correlation, 3)
pvalue = round(res.pvalue, 3)使用Scipy的 spearmanr函数计算ICP分数和影响分数之间的Spearman等级相关系数。如果 p-value 小于0.05,表示相关性灵著。
3 主程序执行流程
if __name__ == "__main__":
#读取ICP和影响分数
icp_scores = read_icp_scores(args.icp_score_path)
infl_scores = read_infl_scores(args.infl_score_path)
#绘制ICP和影响分数的分布图
# plot icp score distribution
plot_score_distribution(icp_scores,
title='ICP Score Distribution',
xlabel='',
ylabel='Scores',
outfile='') # add plot outfile here
# plot influence score distribution
plot_score_distribution(infl_scores,
title='Influence (IP) Distribution',
xlabel='',
ylabel='Scores',
outfile='') # add plot outfile here
# spearman correlation of icp and influence scores
icp_influence_spearman(icp_scores, infl_scores)
# 按区间分类sort icp scores in rank bins (e.g., >0.9, >0.8 etc)
categories_to_count, icp_bin_to_prompt_id = categorize_icp_scores(icp_scores)
# 计算重叠情况number of overlaps between icp and influence in rank bins
find_overlaps(icp_bin_to_prompt_id, infl_scores)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









