






古典密码2
3 维吉尼亚密码
概念
是使用一系列凯撒密码组成密码字母表的算法,属于多表密码的一种简单形式
有密钥,通过密钥和明文的交叉点得到密文
一个明文字母可能对应不同的密文

例子
密钥:ABCDEF AB CDEFA BCD EFABCDEFABCD 明文:CRYPTO IS SHORT FOR CRYPTOGRAPHY 密文:CSASXT IT UKSWT GQU GWYQVRKWAQJB
python加密
def vigenere_encrypt(plaintext, key):
encrypted_text = ""
key_index = 0
key = key.upper() # 将密钥转换为大写字母,方便后续处理
# 遍历明文中的每个字符
for char in plaintext:
if char.isalpha():
# 获取当前密钥字符对应的移位值
shift = ord(key[key_index % len(key)]) - ord('A')
if char.islower():
# 对小写字母进行加密处理
encrypted_text += chr((ord(char) - ord('a') + shift) % 26 + ord('a'))
else:
# 对大写字母进行加密处理
encrypted_text += chr((ord(char) - ord('A') + shift) % 26 + ord('A'))
key_index += 1
else:
# 如果字符不是字母,直接添加到加密后的文本中
encrypted_text += char
return encrypted_text
# 示例用法
plaintext = "HELLO WORLD"
key = "KEY"
encrypted_message = vigenere_encrypt(plaintext, key)
print("加密后的消息:", encrypted_message)
python破解
def vigenere_decrypt(ciphertext, key):
decrypted_text = ""
key_index = 0
key = key.upper()
for char in ciphertext:
if char.isalpha():
shift = ord(key[key_index % len(key)]) - ord('A')
if char.islower():
decrypted_text += chr((ord(char) - ord('a') - shift + 26) % 26 + ord('a'))
else:
decrypted_text += chr((ord(char) - ord('A') - shift + 26) % 26 + ord('A'))
key_index += 1
else:
decrypted_text += char
return decrypted_text
# 示例用法
ciphertext = "KHOOR ZRUOG"
key = "KEY"
decrypted_message = vigenere_decrypt(ciphertext, key)
print("解密后的消息:", decrypted_message)
工具
无需密钥破解 Vigenere Solver | guballa.de
CTF在线工具-CTF工具|CTF编码|CTF密码学|CTF加解密|程序员工具|在线编解码
题
4 培根密码
概念
根所用的密码是一种本质上用二进制数设计的,没有用通常的0和1来表示,而是采用a和b
一
| A | aaaaa | B | aaaab | C | aaaba | D | aaabb | E | aabaa |
|---|---|---|---|---|---|---|---|---|---|
| F | aabab | G | aabba | H | aabbb | I | abaaa | J | abaab |
| K | ababa | L | ababb | M | abbaa | N | abbab | O | abbba |
| P | abbbb | Q | baaaa | R | baaab | S | baaba | T | baabb |
| U | babaa | V | babab | W | babba | X | babbb | Y | bbaaa |
| Z | bbaab |
二
| a | AAAAA | g | AABBA | n | ABBAA | t | BAABA |
|---|---|---|---|---|---|---|---|
| b | AAAAB | h | AABBA | o | ABBAB | u-v | BAABB |
| c | AAABA | i-j | ABAAA | p | ABBBA | w | BABAA |
| d | AAABB | k | ABAAB | q | ABBBB | x | BABAB |
| e | AABAA | l | ABABA | r | BAAAA | y | BABBA |
| f | AABAB | m | ABABB | s | BAAAB | z | BABBB |
例子
明文 steganography
密文 BAABABAABBAABAAAABBAAAAAAABBABABBBAAABBABAAABAAAAAABBBBAABBBBBAAA
python加密
# 定义培根密码字典
bacon_dict = {'A': 'AAAAA', 'B': 'AAAAB', 'C': 'AAABA', 'D': 'AAABB', 'E': 'AABAA',
'F': 'AABAB', 'G': 'AABBA', 'H': 'AABBB', 'I': 'ABAAA', 'J': 'ABAAB',
'K': 'ABABA', 'L': 'ABABB', 'M': 'ABBAA', 'N': 'ABBAB', 'O': 'ABBBA',
'P': 'ABBBB', 'Q': 'BAAAA', 'R': 'BAAAB', 'S': 'BAABA', 'T': 'BAABB',
'U': 'BABAA', 'V': 'BABAB', 'W': 'BABBA', 'X': 'BABBB', 'Y': 'BBAAA',
'Z': 'BBAAB'}
def encrypt_bacon(text):
text = text.upper() # 将输入文本转换为大写
result = ''
for char in text:
if char.isalpha(): # 判断字符是否是字母
result += bacon_dict[char] + ' ' # 将每个字母转换为对应的培根密码编码
else:
result += ' ' # 非字母字符直接输出空格
return result
# 加密示例
plain_text = 'HELLO'
encrypted_text = encrypt_bacon(plain_text)
print(f'明文:{plain_text}')
print(f'密文:{encrypted_text}')
python破解
letters1 = [
'A', 'B', 'C', 'D', 'E', 'F', 'G',
'H', 'I', 'J', 'K', 'L', 'M', 'N',
'O', 'P', 'Q', 'R', 'S', 'T',
'U', 'V', 'W', 'X', 'Y', 'Z',
]
letters2 = [
'a', 'b', 'c', 'd', 'e', 'f', 'g',
'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't',
'u', 'v', 'w', 'x', 'y', 'z',
]
cipher1 = [
"aaaaa", "aaaab", "aaaba", "aaabb", "aabaa", "aabab", "aabba",
"aabbb", "abaaa", "abaab", "ababa", "ababb", "abbaa", "abbab",
"abbba", "abbbb", "baaaa", "baaab", "baaba", "baabb",
"babaa", "babab", "babba", "babbb", "bbaaa", "bbaab",
]
cipher2 = [
"AAAAA", "AAAAB", "AAABA", "AAABB", "AABAA", "AABAB", "AABBA",
"AABBB", "ABAAA", "ABAAA", "ABAAB", "ABABA", "ABABB", "ABBAA",
"ABBAB", "ABBBA", "ABBBB", "BAAAA", "BAAAB", "BAABA",
"BAABB", "BAABB", "BABAA", "BABAB", "BABBA", "BABBB",
]
def bacon1(string):
lists = []
# 分割,五个一组
for i in range(0, len(string), 5):
lists.append(string[i:i+5])
# print(lists)
# 循环匹配,得到下标,对应下标即可
for i in range(0, len(lists)):
for j in range(0, 26):
if lists[i] == cipher1[j]:
# print(j)
print(letters1[j], end="")
print("")
def bacon2(string):
lists = []
# 分割,五个一组
for i in range(0, len(string), 5):
lists.append(string[i:i+5])
# append :在list列表末尾添加一个元素
# print(lists)
# 循环匹配,得到下标,对应下标即可
for i in range(0, len(lists)):
for j in range(0, 26):
if lists[i] == cipher2[j]:
# print(j)
print(letters2[j], end="")
print("")
工具
CTF在线工具-CTF工具|CTF编码|CTF密码学|CTF加解密|程序员工具|在线编解码
5 rot13
概念
它的原理是将明文中的每个字母都向后移动13位,即A变为N,B变为O,以此类推。这样加密后的密文只有字母被替换,其他字符不变。解密时只需要将密文再次进行Rot13加密即可得到原文
ASCII+13或-13
例子
原字符串: ABCDEFGHIJKLM NOPQRSTUVWXYZ abcdefghijklm nopqrstuvwxyz
转换成: NOPQRSTUVWXYZ ABCDEFGHIJKLM nopqrstuvwxyz abcdefghijklm
python加密
def rot13_encrypt(plaintext: str) -> str: ciphertext = "" for c in plaintext: if c.isalpha(): if c.isupper(): new_ascii = (ord(c) - 65 + 13) % 26 + 65 else: new_ascii = (ord(c) - 97 + 13) % 26 + 97 ciphertext += chr(new_ascii) else: ciphertext += c return ciphertext
python破解
def rot13_decrypt(ciphertext: str) -> str: plaintext = "" for c in ciphertext: if c.isalpha(): if c.isupper(): new_ascii = (ord(c) - 65 - 13) % 26 + 65 else: new_ascii = (ord(c) - 97 - 13) % 26 + 97 plaintext += chr(new_ascii) else: plaintext += c return plaintext
工具
CTF在线工具-CTF工具|CTF编码|CTF密码学|CTF加解密|程序员工具|在线编解码
6 猪圈密码
概念
猪圈密码的密码表由一些特定的符号组成,通常是用格子将字母划分开,每个字母对应一个特定的图案符号

工具
CTF在线工具-在线猪圈密码加密|在线猪圈密码解密|猪圈密码算法|Pigpen Cipher
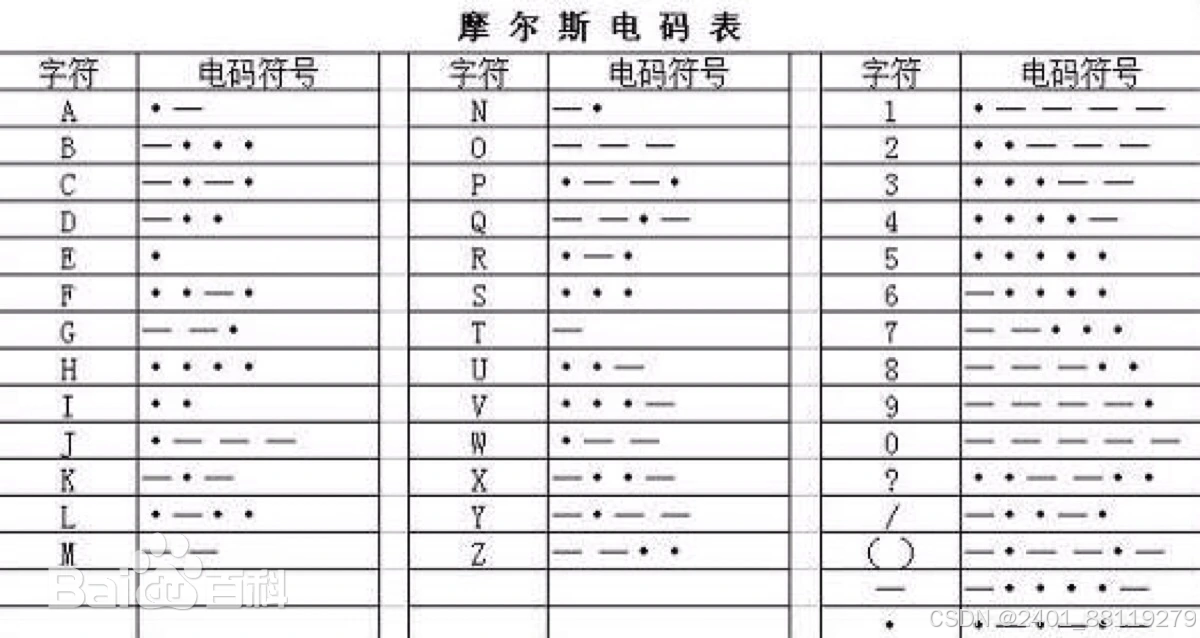
7 摩斯密码
概念
摩尔斯电码只使用零和一两种状态的二进制代码,它的代码包括五种:短促的点信号“・”,保持一定时间的长信号“—”,表示点和划之间的停顿、每个词之间中等的停顿,以及句子之间长的停顿

















 4978
4978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









