






二叉树的性质
1.若规定根节点的层数为1,则一棵非空二叉树的第i层上最多有2^(i-1)个节点。
2.若规定根节点的层数为1,则深度为h的二叉树的最大结点数是2^h-1.
3.对任何一棵二叉树,如果度为0其叶结点个数为n0,度为2的分支结点个数为n2,则有n0=n2+1.
4.若规定根节点的层数为1,具有n个结点的满二叉树的深度为:h=log2(n+1).(ps:2为底数,n+1为对数。
5.对于具有n个结点的完全二叉树,如果按照从上到下从左到右的数组顺序对所有节点从0开始编号,则对于序号为i的结点有:
1.若i>0,i位置节点的双亲序号:(i-1)/2;i=0时,i为根节点编号,无双亲结点。
2.若2i+1<n,左孩子序号:2i+1;2i+1>=n时无左孩子。
3.若2i+2<n,右孩子序号:2i+2;2i+2>=n时无右孩子
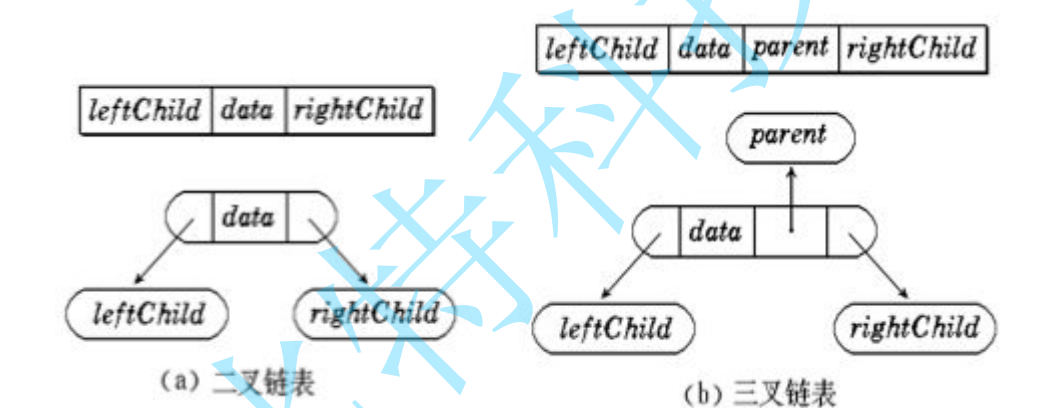
二叉树的存储结构
1.顺序存储
用数组来存储,一般使用数组只适合表示完全二叉树,否则会有空间的浪费。而现实中只有堆才会用数组来存储。二叉树顺序存储在物理上是一个数组,在逻辑上是一棵二叉树。
2.链式存储
用链表表示一棵二叉树,即用链来指示元素的逻辑关系。链式结构分为二叉链和三叉链。
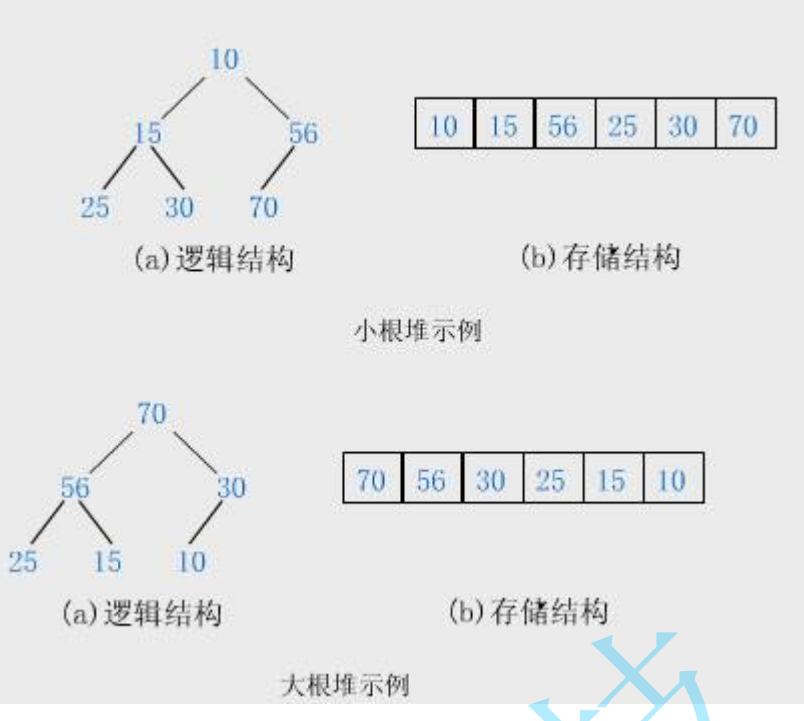
堆
将一个集合中的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中。根节点最大的堆叫做大根堆或最大堆,根节点最小的堆叫做最小堆或小根堆。
表示二叉树的值在数组位置中父子下标的关系:
parent=(child-1)/2;
leftchild=parent*2+1;
rightchild=parent*2+2;
堆的性质:
1.堆中某个节点的值总是不大于或不小于其父节点的值。
2.堆总是一棵完全二叉树。
堆的实现
1.向下调整算法
前提:左右子树必须是一个堆。
int a[]={1,5,3,8,7,6};
这个数组逻辑上可以看做一棵完全二叉树,但还不是一个堆。我们从倒数的第一个非叶子节点的子树开始调整,一直调整到根节点的树,就可以调整成堆。
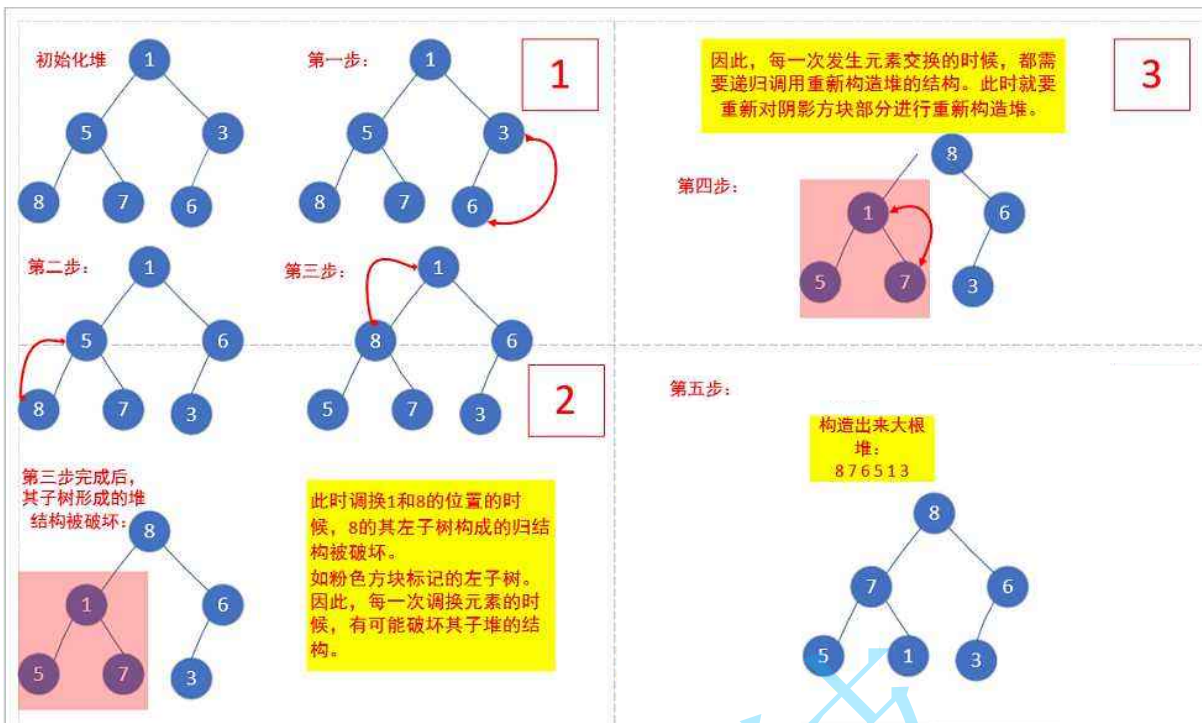
//大根堆,向下调整算法。
typedef int HPDatatype;
void Adjustdown(HPDatatype* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child] < a[child + 1])
{
child++;
}
if (a[child] > a[parent])
{
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
向上调整算法:
void AdjustUp(HPDatatype* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
//建堆
//向上调整建堆
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);//数组中模拟一个个插入数据的过程。
//时间复杂度为O(N*logN)
}
//向下调整
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
//大的数往上浮,小的数往下沉。从最后一个结点的父亲开始。
//时间复杂度为O(N)
}
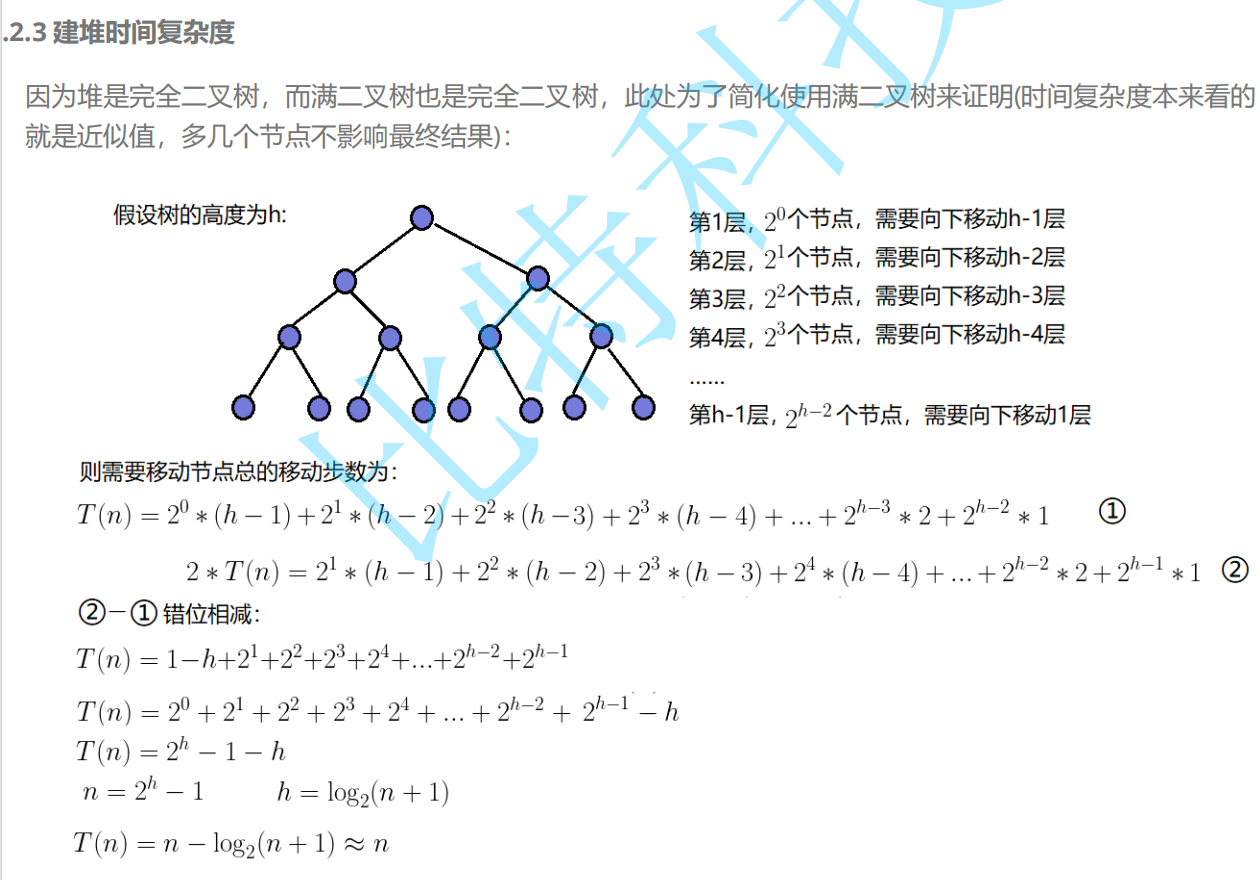
因此,建堆的时间复杂度为O(N).
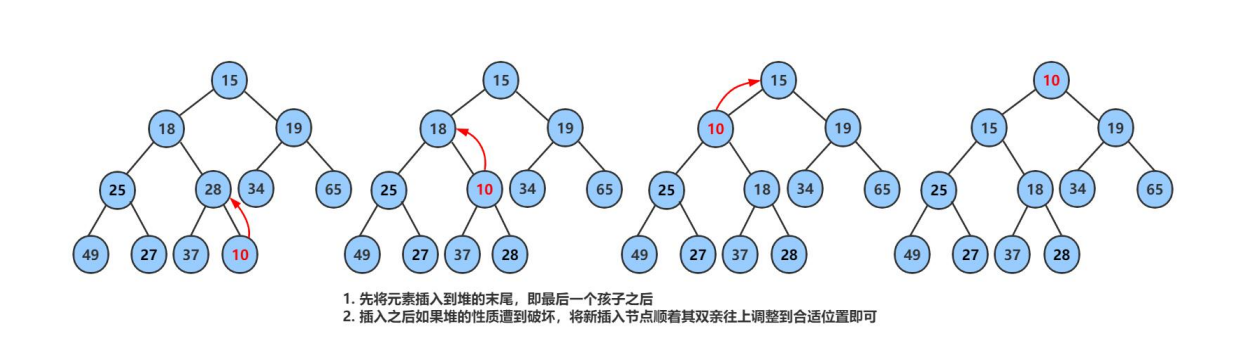
堆的插入
先插入一个数字10到数组的尾上,在进行向上调整算法,直到满足堆。
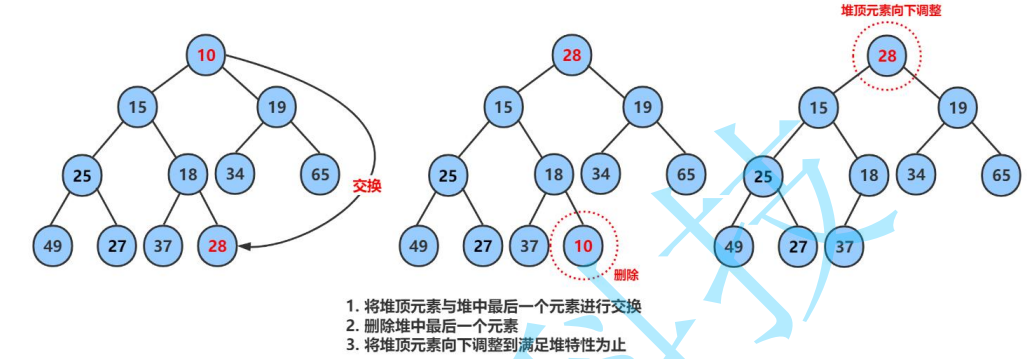
堆的删除
只限于删除堆顶的数据,将堆顶数据和最后一个数据交换,然后删除数组的最后一个数据,再进行向下调整算法。
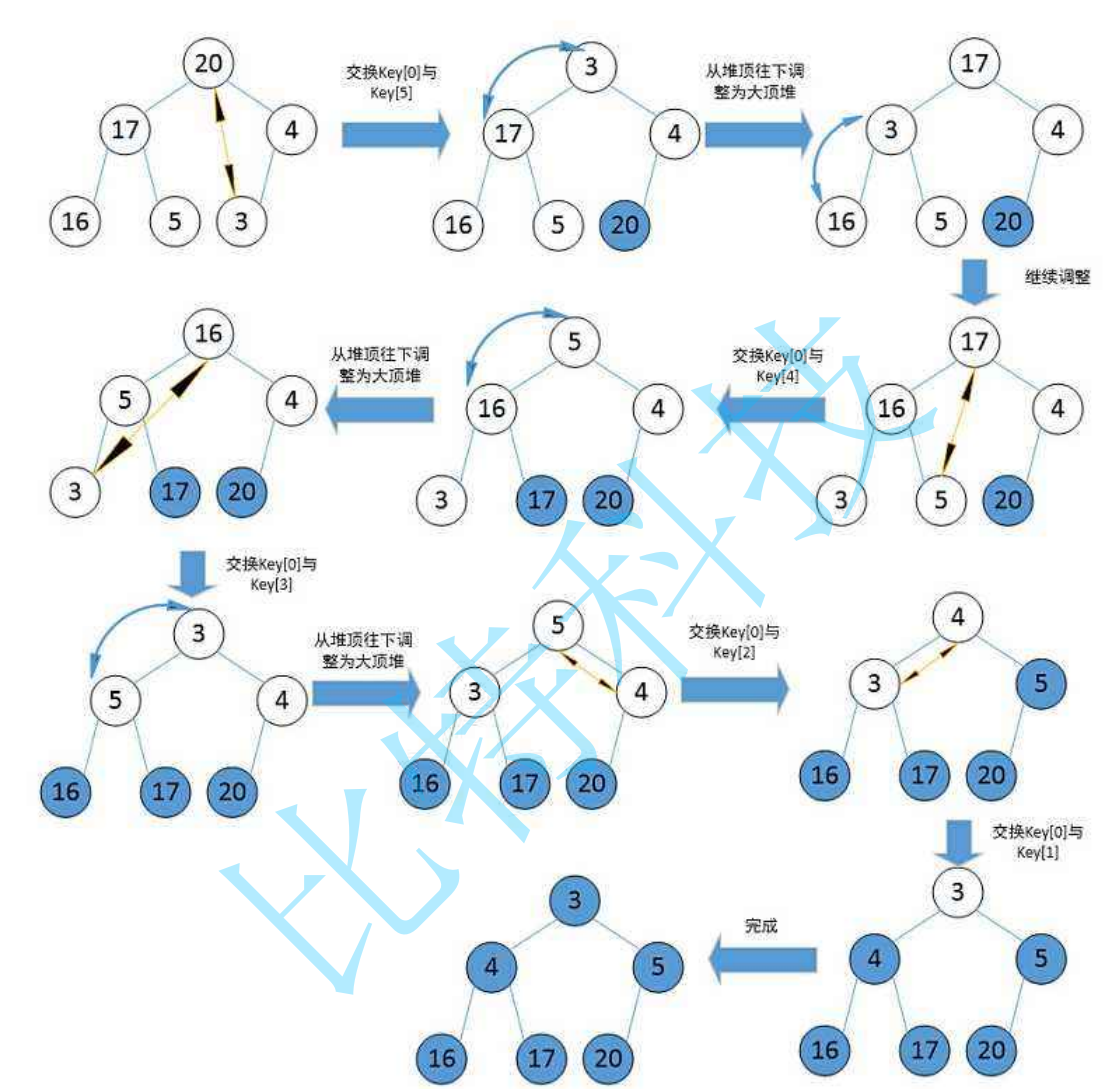
堆的应用
1.堆排序:即利用堆的思想来进行排序,分为两步:
- 建堆
升序:建大堆
降序:建小堆 - 利用堆删除思想来进行排序
掌握了向下调整算法,就可以完成堆排序。
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
swap(&a[end], &a[0]);
AdjustDown(a, end, 0);
end--;
}
}
2.Top-K问题:求数据结合中前K个最大或最小的元素,一般情况下数据量都比较大。
比如:世界500强,专业前十名等。
最直接简单的方式是排序,但如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳方式是用堆解决。
1.用数据集合中前K个元素来建堆
前K个最大的元素,则建小堆
前K个最小的元素,则建大堆。
2.用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素。
例如:找出N个数里最大的前K个:N很大时,内存存不下,数据要放在磁盘文件中,无法随意访问。
遍历剩下的数据,如果这个数据比堆顶的元素大,就替代他进堆(向下调整)
最后这个小堆的数据就是最大的前K个。
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include <time.h>
void swap(int* p1, int* p2)
{
int t = *p1;
*p1 = *p2;
*p2 = t;
}
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child] < a[child + 1])
{
child++;
}
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void printTopk(const char* file, int k)
{
//1.建堆:用数据中的前k个元素建小堆
int* topk = (int*)malloc(sizeof(int) * k);
assert(topk);
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
perror("fopen error");
return;
}
//读出前K个元素建小堆
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &topk[i]);
}
for (int i = (k - 2) / 2; i >= 0; i--)
{
AdjustDown(topk, k, i);
}
int val = 0;
int ret = fscanf(fout, "%d", &val);
while (ret != EOF)
{
if (ret > topk[0])
{
topk[0] = val;
AdjustDown(topk, k, 0);
}
ret = fscanf(fout, "%d", &val);
}
for (int i = 0; i < k; i++)
{
printf("%d ", topk[i]);
}
printf("\n");
free(topk);
fclose(fout);
}
void CreatData()
{
int n = 10000000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; i++)
{
int x = rand() % 1000000;
fprintf(fin,"%d\n",x);
}
fclose(fin);
}
int main()
{
//CreatData();
printTopk("data.txt", 10);
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









