







人工智能
一、numpy
注:import numpy as np
1.将array转化成ndarray对象
array函数: Numpy模块中的array函数可以将Python原⽣列表类型转换为Numpy的ndarray类型。
-
创建数组
-
语法: 使⽤ np.array() 函数,传⼊⼀个列表对象即可创建⼀维数组。
-
示例: b = np.array([1, 2, 3, 4, 5, 6]),结果 b 是⼀个包含这些元素的⼀维数组。
-
参数: dtype 参数,⽤于指定数组元素的数据类型,如 dtype=float 将元素转为浮点数。如: a = np.array([1, 2, 3, 4, 5, 6], dtype=complex),结果 a 是⼀个元素类型为复数的数组。
ndmin 参数,⽤于指定⽣成数组的最⼩维度。如: a = np.array([1, 2, 3, 4, 5, 6], ndmin=3),结果 a 是⼀个形状为 (1, 1, 6) 的三维数组。
-
-
创建多维数组: 通过向array函数传递列表类型的参数可以⽣成多维数组,例如⼆维数组的每个列表元素代表⼀维数组的⼀⾏
-
⽅法: 传⼊⼀个嵌套列表,即可创建⼆维数组。
-
示例: a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]),结果 a 是⼀个 3x3 的⼆维数组
import numpy as np list1=[1,2,3,4,5] np.array(list1,dtype=float,ndmin=3) array([[[1., 2., 3., 4., 5.]]])
-
2.生成ndarray 对象
1>有规律
-
numpy.arange(start, stop, step, dtype)
起始值,终止值(不包含),步长(默认为1)
- 示例: x = np.arange(0, 6, dtype=int),结果 x 是包含 [0, 1, 2, 3, 4, 5] 的⼀维整数数组
-
np.zeros(shape)
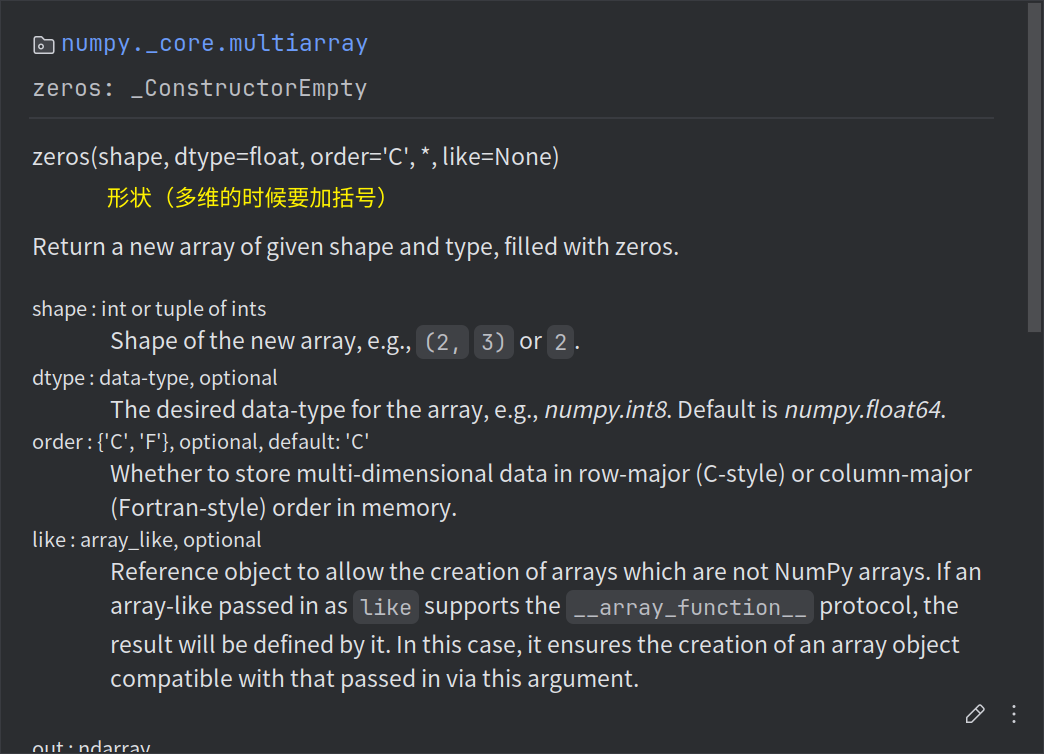
全零数组:应⽤场景: 机器学习初始化参数、预分配数组空间
相似函数
a=np.array([1,2,3,4,5]) np.zeros_like(a) array([0, 0, 0, 0, 0])
-
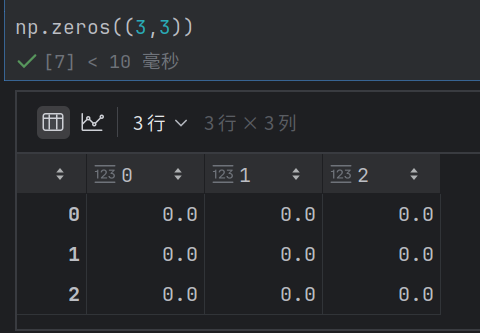
np.ones(shape)
全⼀数组:
特点: 与zeros()参数结构相同,仅填充值不同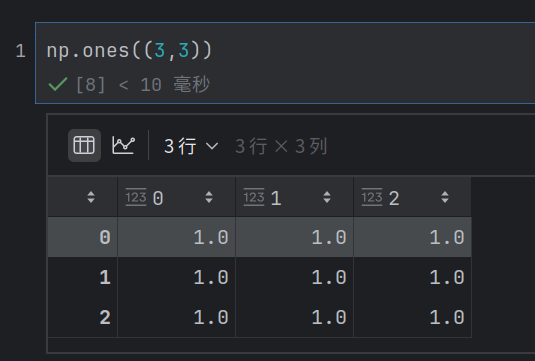
相似函数
a=np.array([1,2,3,4,5]) np.ones_like(a) array([1, 1, 1, 1, 1]) -
np.empty(shape)
未初始化数组:
o 优势: ⽐zeros()效率更⾼,适合⽴即赋值的场景
o 注意: 内容不可预测,必须后续赋值使⽤,使用的是原来存储的数据
-
np.linspace(start,stop,num,endpoint,retstep,dtype)
等分数组
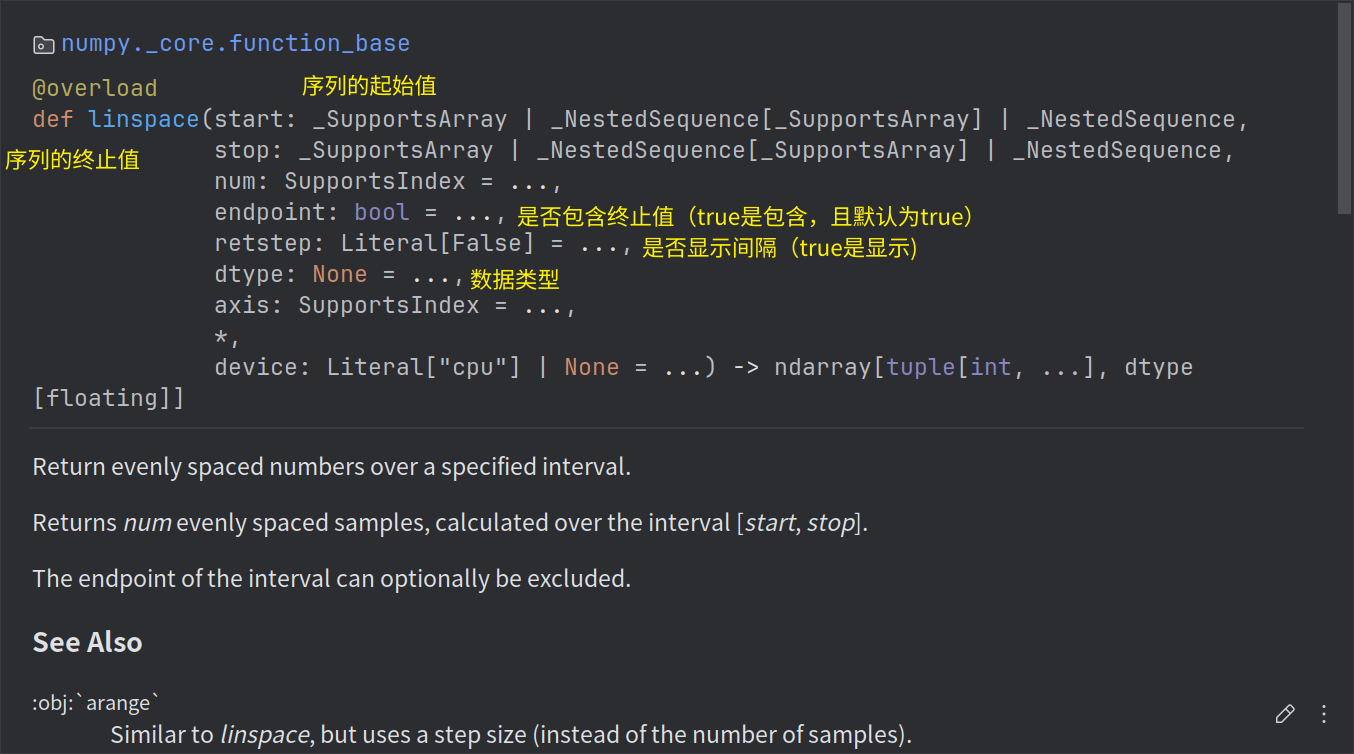
np.linspace(1,100,50) # array([ 1. , 3.02040816, 5.04081633, 7.06122449, 9.08163265, 11.10204082, 13.12244898, 15.14285714, 17.16326531, 19.18367347, 21.20408163, 23.2244898 , 25.24489796, 27.26530612, 29.28571429, 31.30612245, 33.32653061, 35.34693878, 37.36734694, 39.3877551 , 41.40816327, 43.42857143, 45.44897959, 47.46938776, 49.48979592, 51.51020408, 53.53061224, 55.55102041, 57.57142857, 59.59183673, 61.6122449 , 63.63265306, 65.65306122, 67.67346939, 69.69387755, 71.71428571, 73.73469388, 75.75510204, 77.7755102 , 79.79591837, 81.81632653, 83.83673469, 85.85714286, 87.87755102, 89.89795918, 91.91836735, 93.93877551, 95.95918367, 97.97959184, 100. ]) -
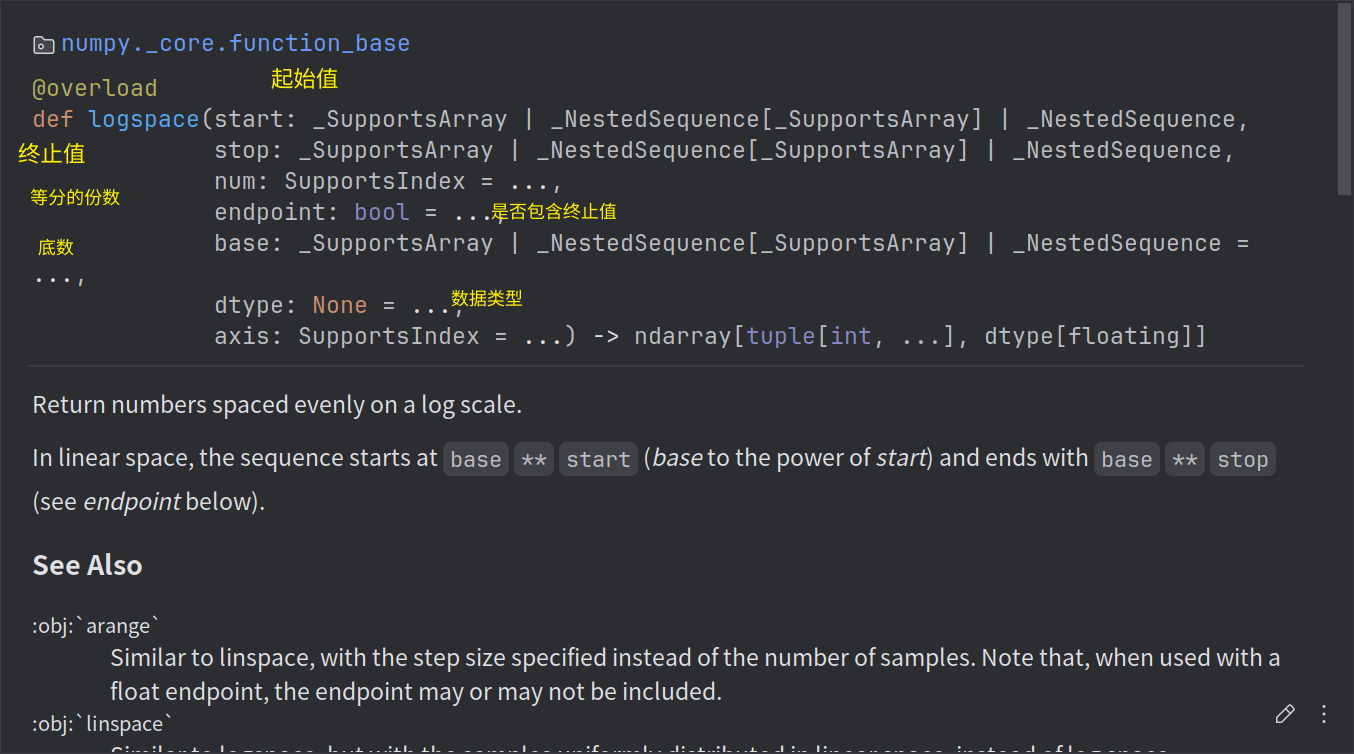
np.logspace()
对数等分
np.logspace(0,9,10,base=2) array([ 1., 2., 4., 8., 16., 32., 64., 128., 256., 512.])

2>随机生成
-
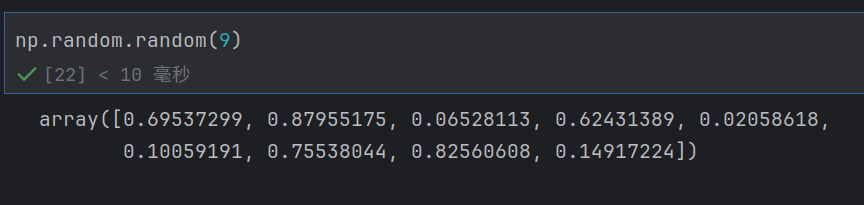
np.random.random(num)
注:只能生成(0,1)的随机数,且size无法指定为NULL
-
np.random.randint(low,high=None,size=None )
指定范围内的随机整数⽣成: np.random.randint(low, high=None, size=None)
-
参数说明:
- low: 随机整数的下界(包含)。
- high: 随机整数的上界(不包含),默认为None。
- size: 输出数组的形状。
-
示例:
arr = np.random.randint(10, size=10)⽣成⼀个包含10个[0, 10)范围内随机整数的⼀维数组。arr = np.random.randint(5, 10, size=(3, 4))⽣成⼀个3⾏4列的⼆维数组,元素为[5, 10)范围内的随机整数。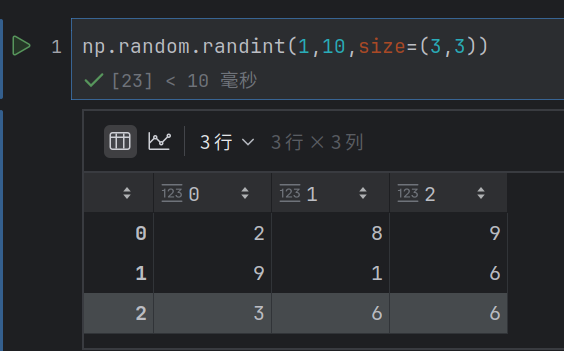
-
-
np.random.randn(d0, d1, …, dn)
正态分布随机数⽣成:可以⽣成具有标准正态分布(期望为0,⽅差为1)的随机数。
可以⽣成多维数组如size=(2, 3, 4)⽣成⼀个2x3x4的三维数组。
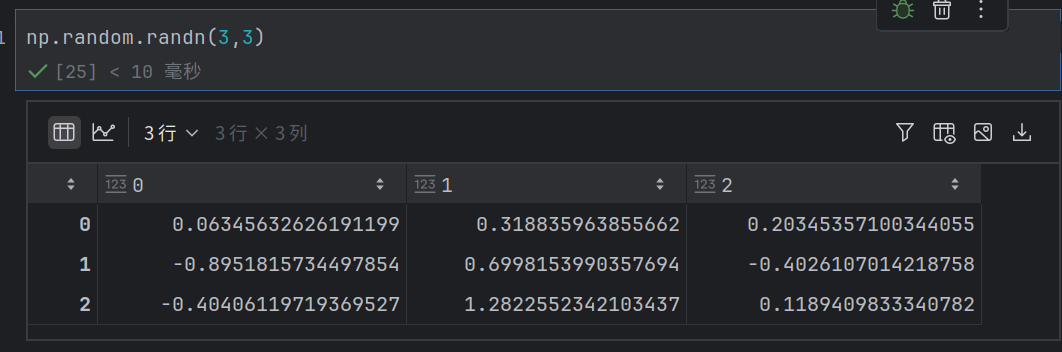
示例:
ox = np.random.randn()⽣成⼀个标准正态分布的随机数。
o **y = np.random.randn(2, 4)**⽣成⼀个2⾏4列的⼆维数组,元素为标准正态分布
的随机数。
oz = np.random.randn(2, 3, 4)⽣成⼀个2x3x4的三维数组,元素为标准正态分
布的随机数。 -
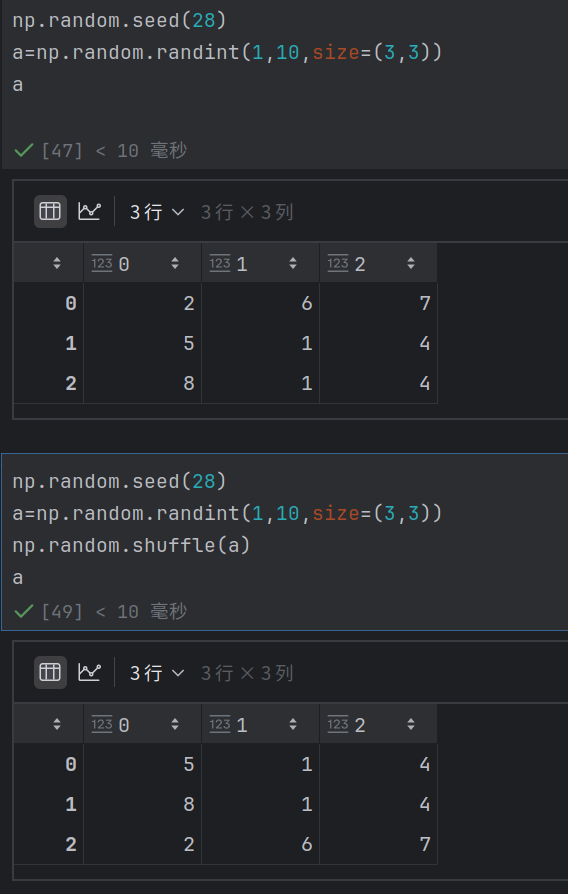
np.random.seed()【种子】
种⼦设定: 使⽤np.random.seed(seed)可以设定随机⽣成器的种⼦,使得每次运⾏⽣成的随机数序列相同。
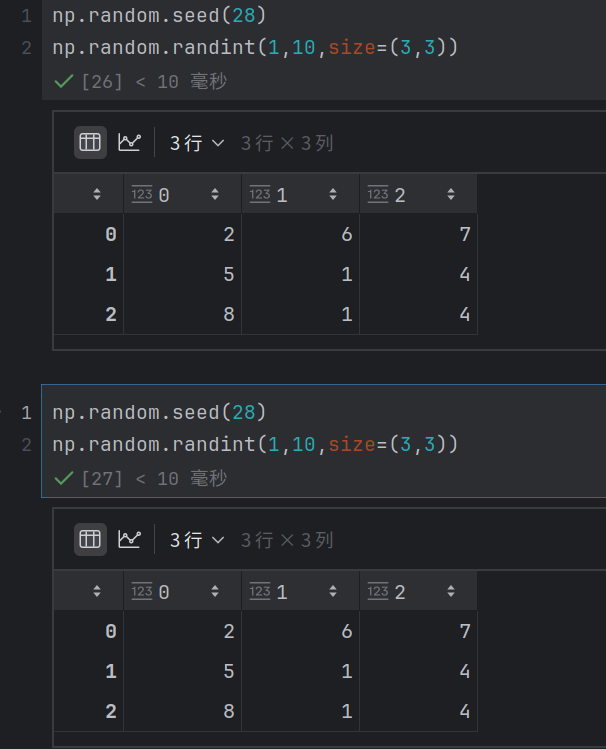
随机数的生成是公式计算的结果,当控制一个seed之后输出的结果是一样的
-
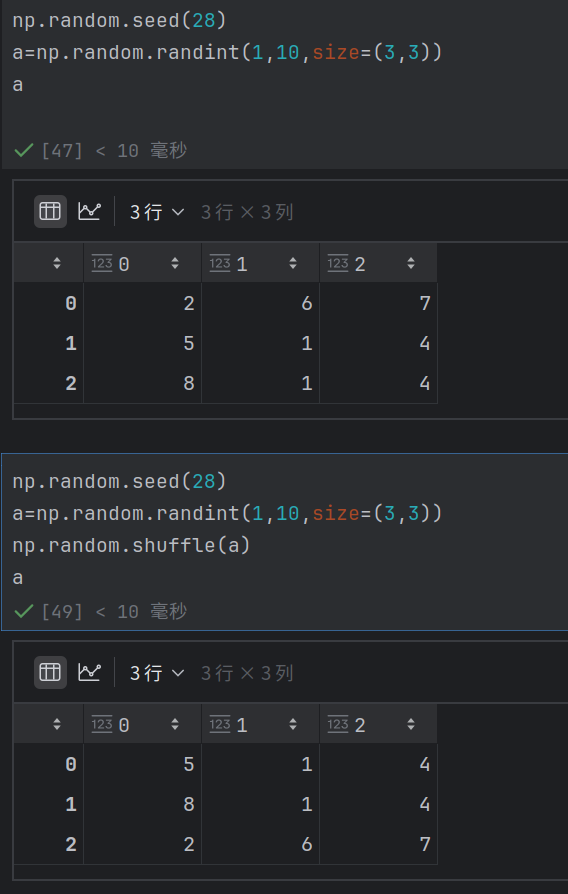
np.random.shuffle(x)
就地随机排列: 使⽤np.random.shuffle(x)可以对序列x进⾏就地随机排列,不返回任何值。
示例:
oarr = np.array([1, 2, 3, 4, 5])创建⼀个数组。
onp.random.shuffle(arr)对数组进⾏就地随机排列,arr的元素顺序会改变。list1=[1,2,3,4,5] np.random.shuffle(list1) list1 [5, 2, 4, 3, 1]
3.ndarray数组的属性
-
同类型集合: ndarray是⼀系列同类型数据的集合,以零下标开始索引
-
内存结构(就可以使用切片操作): 每个元素在内存中有相同存储⼤⼩区域,包含:
-
数据指针
-
内存数据块
-
dtype描述元素类型
-
shape元组表示维度⼤⼩
-
-
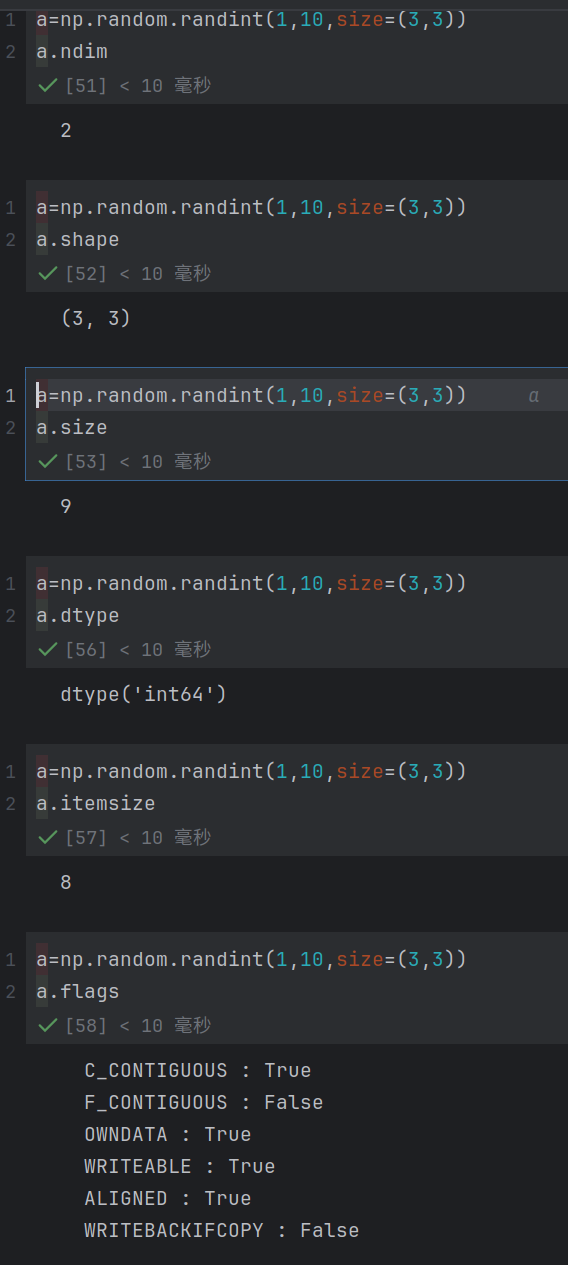
核⼼属性:
ndim: 维度数量(秩)
shape: 数组维度形状(矩阵为n⾏m列)
size: 元素总数(shape各维度乘积)
dtype: 元素数据类型
itemsize: 单个元素字节⼤⼩
flags: 内存信息
-
4.ndarray数组的切片,索引,改维,拼接,分割,复制,转置
-
切片和索引
访问⽅式: ndarray对象的内容可以通过索引或切⽚来访问和修改,与Python中list的切
⽚操作⼀样。
索引参数: ndarray数组可以基于0-n的下标进⾏索引,并设置start, stop及step参数,从
原数组中切割出⼀个新数组(但是新数组的地址仍然指向该数组,即为浅拷贝)。 -
改维
-
reshape⽅法
示例代码:
arr = np.arange(12); arr = arr.reshape(4,3)解释: 将⼀维数组arr重塑为4⾏3列的⼆维数组。
注意: 重塑时,新形状的元素总数必须与原数组相同,否则会报错。
-
ravel方法
作⽤: ravel函数可以将多维数组变成⼀维数组。
示例:
将三维数组b变成⼀维数组a1:a1 = b.ravel()
特点: 不需要传⼊参数,直接调⽤即可实现降维。 -
flatten函数同样可以将多维数组变成⼀维数组。
-
ravel 和flatten
在Numpy中,ravel返回的是数组的视图(view),⽽flatten返回的是数
组的副本(copy),但在⼤多数情况下,⼆者效果相同。
-
-
拼接
-
⽔平拼接(hstack):
使⽤hstack函数可以将两个或多个数组在⽔平⽅向(列⽅向)上进⾏拼接。
示例:
o 数组a为[[1,2,3],[4,5,6]]
o 数组b为[[‘a’,‘b’,‘c’],[‘d’,‘e’,‘f’]]
o 使⽤np.hstack([a,b])进⾏⽔平拼接,结果为
[[‘1’,‘2’,‘3’,‘a’,‘b’,‘c’],[‘4’,‘5’,‘6’,‘d’,‘e’,‘f’]] -
垂直拼接(vstack):
使⽤vstack函数可以将两个或多个数组在垂直⽅向(⾏⽅向)上进⾏拼接。
示例:
o 数组a为[[1,2,3],[4,5,6]]
o 数组b为[[‘a’,‘b’,‘c’,‘m’],[‘d’,‘e’,‘f’,‘n’]]使⽤np.vstack([a,b])进⾏垂直拼接,结果为
[[‘1’,‘2’,‘3’],[‘4’,‘5’,‘6’],[‘a’,‘b’,‘c’,‘m’],[‘d’,‘e’,‘f’,‘n’]] -
concatenate:
1)默认情况
默认⾏为:
np.concatenate函数在默认情况下(axis=0)会沿着第⼀个轴(⾏⽅向)进⾏拼接,相当于vstack。
示例:
o 数组a和b形状相同
o 使⽤np.concatenate([a,b])或np.concatenate([a,b],axis=0),结果与vstack相同
2)指明⽅向
指定轴拼接: 可以通过axis参数指定沿着哪个轴进⾏拼接。
示例:
o axis=0时,按⾏拼接,相当于vstack
o axis=1时,按列拼接,相当于hstack
o 对于形状不⼀致的数组,拼接时除拼接轴外,其余轴的⻓度必须相同
3)三维数组的拼接
对于三维数组,可以沿着不同的轴(axis=0,1,2)进⾏拼接。
示例:
数组aa形状为(3,4,3)
数组bb形状也为(3,4,3)
使⽤np.concatenate([aa,bb], axis=0),结果形状为(6,4,3),即第⼀个维度拼接
使⽤np.concatenate([aa,bb], axis=1),结果形状为(3,8,3),即第⼆个维度拼接
使⽤np.concatenate([aa,bb], axis=2),结果形状为(3,4,6),即第三个维度拼接
-
-
分割(numpy.split(ary,indices_or_sections,axis))
split⽅法: 使⽤np.split等⽅法可以分隔数组。
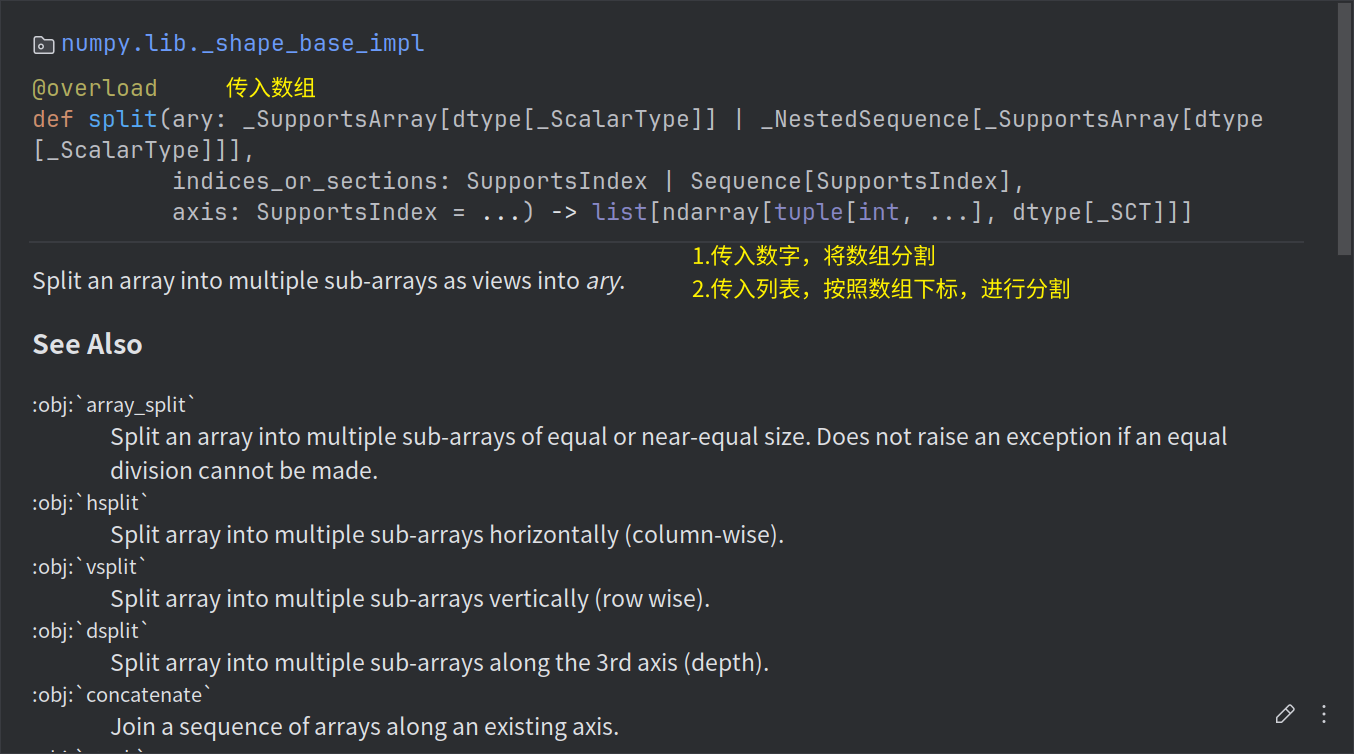
参数说明:
o ary: 被分割的数组
o indices_or_sections: 如果是整数则平均切分,如果是数组则指定切分位置
o axis: 切分维度,默认为0(横向切分),1为纵向切分a=np.random.randint(1,10,10) np.split(a,2) [array([8, 6, 3, 9, 6]), array([7, 2, 2, 4, 9])]a=np.random.randint(1,10,size=(2,2)) np.split(a,2) [array([[1, 1]]), array([[1, 6]])]整数切分: 传⼊整数4会将12个元素的数组平均分成4份,每份3个元素
数组切分: 传⼊数组[3,5]会在索引3和5的位置切分,得到[0,1,2]、[3,4]、[5-11]三部分
切分原理: 数组参数表示在哪些索引位置前进⾏切分横向切分:axis = 0时按⾏切分,将4⾏数组分成2个2⾏的⼦数组
纵向切分:axis = 1时按列切分,需确保能整除,否则会报错
错误处理: 对3列数组纵向切分2份会报错,需先reshape为可整除的形状 -
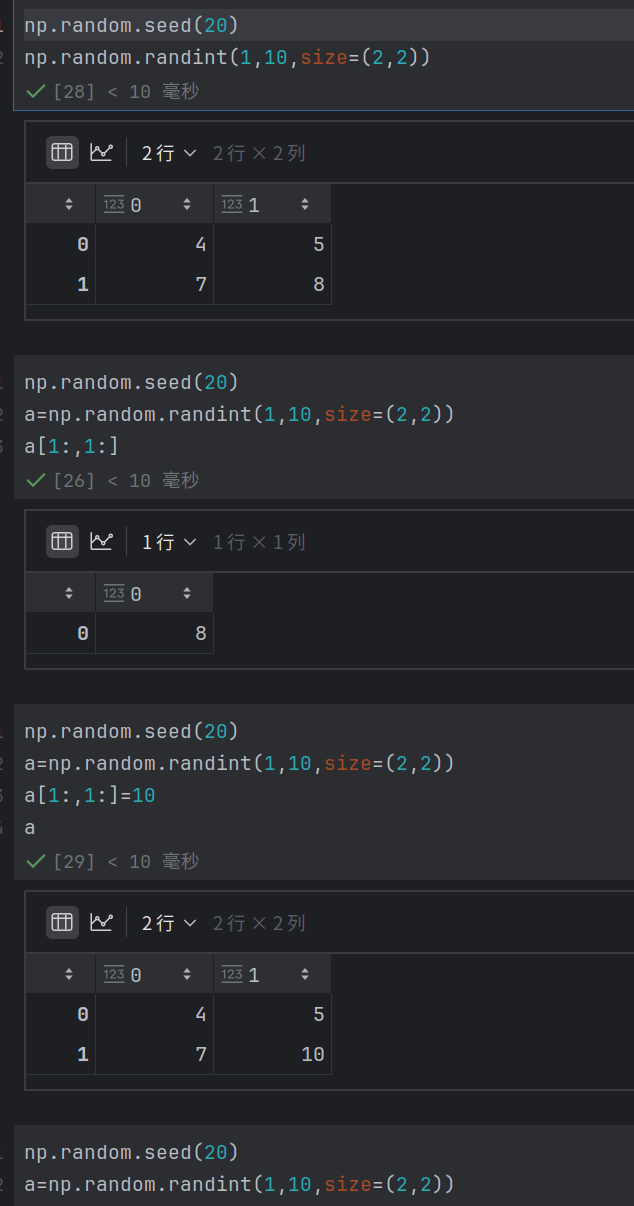
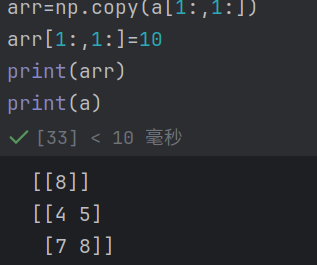
复制及深拷贝(arr1=np.copy(arr))
copy函数: 使⽤np.copy函数可以实现数组的深拷⻉。
示例代码: sub_array = np.copy(a[:2,:2])
解释: 将数组a的前两⾏前两列复制到⼀个新的数组sub_array中,修改sub_array不
会影响原数组a。
注意: 直接通过切⽚操作取得的数组视图会与原数组共享内存,修改视图会影响原数
组,使⽤copy可以避免这种情况。注:浅拷贝和深拷贝
-
转置(transpose)
功能: 将数组的⾏列互换,相当于数学中的矩阵转置
两种⽤法:
o np.transpose(a)
o a.transpose()多维转置: 可以指定轴顺序,如将1×3×3×4数组转为3×3×4×1
形状变化: 转置后数组的shape会相应改变a=np.random.randint(1,10,size=(2,2)) print(a) print(a.transpose([1,0])) [[3 8] [7 7]] [[3 7] [8 7]]
5.numpy的运算
-
算术函数
-
基本运算法则(+,-,*,/)
运算条件:当两个ndarray对象形状相同时,会进⾏对应位置的运算
运算⽅式:⽀持直接使⽤运算符(+,-,*,/)或显式调⽤函数(add/subtract/multiply/divide)
⼴播机制:当数组形状不同时,NumPy会⾃动将较⼩数组"⼴播"扩展⾄较⼤数组的形状再进⾏运算⼴播机制详解:当a(3x3)与b(1x3)运算时,b会被⾃动复制扩展为3x3的数组再进⾏运算
np.random.seed(20) a=np.random.randint(1,10,size=(2,2)) print(a) b=np.array([2,2]) print(a*b) [[4 5] [7 8]] [[ 8 10]36 484 9.0 8.455767262643882 6.5 [ 6. 12.] [[121 484] [ 1 4]] [[3.31662479 4.69041576] [1. 1.41421356]] inf 1 22 [[11 22] [ 1 2]] 1 [14 16]]输出参数:(out参数)
np.random.seed(20) a=np.random.randint(1,10,size=(2,2)) print(a) b=np.array([2,2]) c=np.add(a,b,out=a) print(b) print(a) print(c) [[4 5] [7 8]] [2 2] [[ 6 7] [ 9 10]] [[ 6 7] [ 9 10]] -
数学函数
-
三⻆函数:np.sin(), np.cos(), np.tan()
⻆度转换:需要先将⻆度转换为弧度(乘以np.pi / 180)
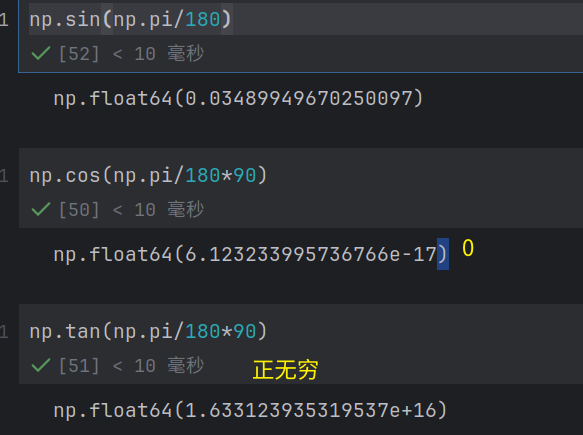
-
取整函数:
around():四舍五⼊,但需注意其舍⼊规则的特殊性
floor():向下取整(地板函数)
ceil():向上取整(天花板函数)实际应⽤:在机器学习中常⽤于批次数据量的计算
注意事项:==around()函数在边界情况(如4.5)==的舍⼊⾏为可能与预期不符,建议谨慎使⽤
a=np.random.random(10) print(a) np.around(a) [0.49794007 0.67941112 0.65078591 0.26879524 0.06732467 0.77144514 0.48098413 0.32920641 0.51064106 0.26362883] array([0., 1., 1., 0., 0., 1., 0., 0., 1., 0.])a=np.random.random(10)*10 print(a) np.around(a) [8.25823577 1.56391719 7.34300519 4.08643432 7.78687904 8.03970568 7.86071444 5.92287019 6.64489203 6.46567287] array([8., 2., 7., 4., 8., 8., 8., 6., 7., 6.])a=np.array([1.5,2.5,3.5,4.5,5.5]) np.around(a) array([2., 2., 4., 4., 6.])a=np.random.random(10)*10 print(a) np.floor(a) [2.68290634 6.07767079 0.4815737 6.95500639 2.99271878 1.65635555 3.3225194 1.65437746 9.14637981 2.84025006] array([2., 6., 0., 6., 2., 1., 3., 1., 9., 2.])a=np.random.random(10)*10 print(a) np.ceil(a) [1.07607265 1.1700177 7.55523599 8.38894458 0.35537027 1.2144377 8.91008055 5.15092234 9.24419012 5.8124263 ] array([ 2., 2., 8., 9., 1., 2., 9., 6., 10., 6.])
-
-
-
聚合函数
求和运算:使⽤np.sum(temp)对数组[1,2,3,5,5]所有元素求和,结果为16
乘积运算:np.prod(temp)计算所有元素乘积,结果为150
均值计算:np.mean(temp)求得平均值为3.2
⽅差计算:np.var(temp)计算结果为2.56
标准差:np.std(temp)得到1.6,与⽅差关系为 2.56 = 1.6中位数:np.median(temp)结果为3.0,与平均数不同,表示排序后中间位置的值
幂运算:np.power(temp,2)对每个元素平⽅,得到[1,4,9,25,25],需注意必须传⼊两个参数
开⽅运算:np.sqrt(temp)计算平⽅根,结果为36
极值运算:
o np.min(temp)取最⼩值1
o np.max(temp)取最⼤值5
o np.argmin(temp)返回最⼩值索引0
o np.argmax(temp)返回第⼀个最⼤值索引3(多个相同值时取第⼀个)
指数运算:
o np.exp(10)计算e10≈22026.47
o np.log(10)计算ln10≈2.3026
o 两者互为反函数关系,满⾜ln(ex) = x
数学特性:
o 对数函数单调递增,保持极值位置不变
o 对数化可将连乘转为连加:log(ab) = loga + logb
o 在机器学习中常⽤于损失函数优化
特殊值:
o np.inf表示⽆穷⼤
o 常⽤于数值计算中的边界条件处理a=np.array([[11,22],[1,2]]) print(np.sum(a)) print(np.prod(a)) print(np.mean(a)) print(np.std(a)) print(np.median(a)) print(np.median(a,axis=0)) print(np.power(a,2)) print(np.sqrt(a)) print(np.inf) print(np.min(a)) print(np.max(a)) print(np.around(a)) print(np.argmax(a)) 36 484 9.0 8.455767262643882 6.5 [ 6. 12.] [[121 484] [ 1 4]] [[3.31662479 4.69041576] [1. 1.41421356]] inf 1 22 [[11 22] [ 1 2]] 1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









