







基于机器学习的道路交通状态分析,本项目利用关联规则算法挖掘分析影响交通状况的原因,再利用随机森林算法完成交通状况预测。
文章目录
 项目内容lwen(9551)+dataset+code
项目内容lwen(9551)+dataset+code

1

以下文字及代码仅供参考。
基于机器学习的道路交通状态分析
第1章 绝论
1.1 研究背景
随着城市化进程的加快,道路交通问题日益严重,包括交通拥堵、交通事故等。为了改善这些问题,需要深入了解影响交通状况的各种因素,并进行有效的预测和管理。
1.2 研究的目的及意义
本研究旨在利用关联规则算法挖掘影响交通状况的原因,并通过随机森林算法对交通状况进行预测。这不仅有助于提高道路使用效率,还能为城市规划提供科学依据。
第2章 数据分析研究思路简介
2.1 数据来源
数据来源于多个渠道,如交通摄像头、传感器网络、GPS设备等,涵盖了车流量、速度、天气条件、事件报告等多个方面。
2.2 随机森林部分数据处理
从你提供的图片文字信息来看,这部分内容主要描述了在随机森林部分数据处理中的数据清洗步骤。以下是对这部分内容的详细解释和补充:
2.2 随机森林部分数据处理
2.2.1 数据清洗
在选取的道路中有一些道路是比较偏僻的或道路状况良好,这样的道路不论是在恶劣的天气又或者是在高峰时段都不会发生拥堵,它产生的数据也会让实验出现很大的偏差,因此我们需要删除这样的道路。在这里我们是将整个数据集导入数据库中,使用数据库语言来进行筛选并删除。除此之外,在进一步的实验后我们发现了一些采集的字段是不必要的,这样的数据也需要清洗掉。
具体步骤如下:
-
数据导入与筛选:
- 将所有原始数据导入数据库。
- 使用SQL或其他数据库查询语言,根据特定条件(如道路类型、交通状况等)筛选出需要的数据。
-
删除不必要的字段:
- 分析数据集,确定哪些字段对模型训练没有帮助或影响不大。
- 删除这些不必要的字段,减少数据冗余,提高模型效率。
-
示例代码:
import pandas as pd # 假设df是原始数据集 df = pd.read_csv('path/to/traffic_data.csv') # 删除不需要的列 df_cleaned = df.drop(columns=['unnecessary_column_1', 'unnecessary_column_2']) # 示例:删除特定条件下的行 df_filtered = df_cleaned[df_cleaned['road_status'] != '偏僻'] # 保存清理后的数据 df_filtered.to_csv('cleaned_traffic_data.csv', index=False) -
图示说明:
- 图1:显示了原始数据集的部分内容,包括多个字段。
- 图2:展示了经过数据清洗后的数据集,去除了不必要的字段。
- 2.2.1 数据清洗:去除重复值、处理缺失值。
- 2.2.2 数据归一化:将不同尺度的数据调整到同一尺度,以避免某些特征在模型中占据过多权重。
- 2.2.3 数据数值化:将分类变量转换为数值型,以便于模型处理。
2.3 关联规则部分数据处理
针对关联规则挖掘,需要对数据进行离散化处理,确保所有特征都是离散形式,以适应Apriori算法的要求。
第3章 数据分析方法介绍
3.1 Apriori算法介绍
Apriori算法是一种经典的关联规则挖掘算法,用于发现大型数据库中的频繁项集及其相关联规则。
3.2 Apriori算法基本概念
- 最小支持度(min_support):项集出现的最低频率。
- 最小置信度(min_confidence):规则成立的最低概率。
3.3 随机森林算法介绍
随机森林是一种集成学习方法,由多个决策树组成,通过投票或平均来改进预测结果。
3.4 随机森林算法基本概念
- Bagging:从训练集中有放回地抽取样本构建多棵决策树。
- 特征随机选择:在每个节点上随机选择一部分特征作为分裂候选。
第4章 算法分析研究思路简介
4.1 关联规则Apriori研究思路
- 通过设定不同的最小支持度和最小置信度,挖掘出影响交通状况的关键因素。
- 对比固定因素与变化因素的影响,评估不同条件下交通状态的变化规律。
4.2 随机森林算法研究思路
- 利用历史交通数据训练随机森林模型,预测未来的交通状况。
- 分析模型的重要性得分,识别对交通状态影响较大的特征。
第5章 代码实现
5.1 关联规则Apriori代码实现
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
# 示例数据
data = [['A', 'B', 'C'], ['B', 'C'], ['A', 'B'], ['A', 'C'], ['A', 'B', 'C', 'D']]
# 数据编码
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 应用Apriori算法
frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.8)
print("Frequent Itemsets:")
print(frequent_itemsets)
print("\nAssociation Rules:")
print(rules)
5.2 随机森林代码实现
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import pandas as pd
import numpy as np
# 加载并预处理数据(此处假设已有预处理好的DataFrame df)
# df = pd.read_csv('path/to/traffic_data.csv')
# 特征和标签分离
X = df.drop(columns=['target']) # 假设'target'是目标列
y = df['target']
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# 训练模型
rf_model.fit(X_train, y_train)
# 预测
predictions = rf_model.predict(X_test)
# 评估
mse = mean_squared_error(y_test, predictions)
print(f'Mean Squared Error: {mse}')
# 特征重要性
importances = rf_model.feature_importances_
indices = np.argsort(importances)[::-1]
print("Feature ranking:")
for f in range(X.shape[1]):
print(f"{f + 1}. feature {X.columns[indices[f]]} ({importances[indices[f]]})")
第6章 结论
内容主要描述了基于Apriori算法的关联规则挖掘实验分析。以下是对这部分内容的详细解释和补充:
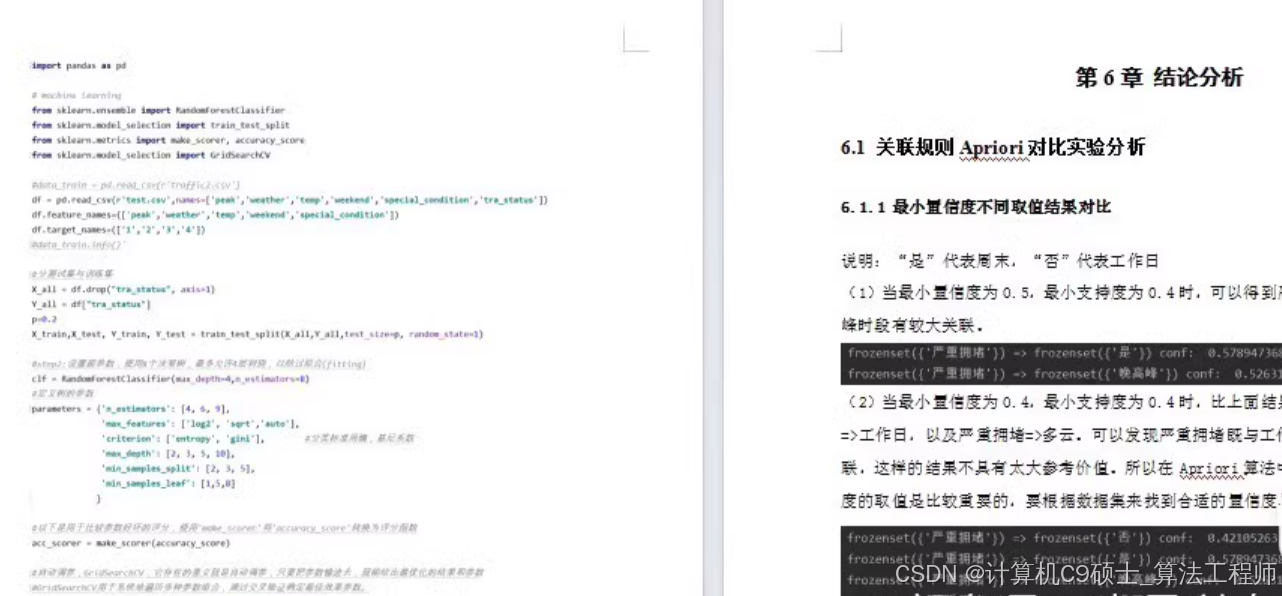
第6章 结论分析
6.1 关联规则 Apriori 对比实验分析
6.1.1 最小置信度不同取值结果对比
说明:“是”代表周末,“否”代表工作日。
-
当最小置信度为0.5,最小支持度为0.4时:
- 可以得到严重拥堵与周末、以及晚高峰时段有较大关联。
- 示例规则:
frozenset({'严重拥堵'}) => frozenset({'是'})conf: 0.5789473684210527frozenset({'严重拥堵'}) => frozenset({'晚高峰'})conf: 0.5263157894736842
-
当最小置信度为0.4,最小支持度为0.4时:
- 比上面结果新增的关联有:严重拥堵=>工作日,以及严重拥堵=>多云。
- 示例规则:
frozenset({'严重拥堵'}) => frozenset({'否'})conf: 0.42105263frozenset({'严重拥堵'}) => frozenset({'多云'})conf: 0.5789473684210527frozenset({'严重拥堵'}) => frozenset({'晚高峰'})conf: 0.5263157894736842
结论:
- 当最小置信度和最小支持度取不同的值时,得到的关联规则会有显著差异。
- 在Apriori算法中,最小置信度和最小支持度的取值是比较重要的,需要根据数据集来找到合适的阈值。
6.1.2 固定因素与变化因素对比
固定因素:
- 周末(“是”)和工作日(“否”)。
- 晚高峰时段。
变化因素:
- 天气条件(如多云)。
结论:
- 固定因素对交通状况的影响较为明显,尤其是在周末和晚高峰时段。
- 变化因素如天气条件也会对交通状况产生影响,但其影响程度可能不如固定因素显著。
附代码
以下是Python代码示例,用于实现Apriori算法的关联规则挖掘:
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
# 加载数据
df = pd.read_csv('traffic_data.csv')
# 数据预处理
# 假设数据集中包含'peak', 'weather', 'temp', 'weekend', 'special_condition', 'tra_status'
# 将数据转换为事务格式
transactions = df[['peak', 'weather', 'temp', 'weekend', 'special_condition']].values.tolist()
# 编码事务
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df_encoded = pd.DataFrame(te_ary, columns=te.columns_)
# 应用Apriori算法
frequent_itemsets = apriori(df_encoded, min_support=0.4, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.5)
# 输出结果
print("Frequent Itemsets:")
print(frequent_itemsets)
print("\nAssociation Rules:")
print(rules)
解释
- 数据加载:使用
pandas读取CSV文件中的数据。 - 数据预处理:将数据转换为事务格式,以便应用Apriori算法。
- 编码事务:使用
TransactionEncoder将事务数据编码为数值形式。 - 应用Apriori算法:使用
apriori函数计算频繁项集,并使用association_rules生成关联规则。 - 输出结果:打印频繁项集和关联规则。
6.1 关联规则Apriori对比实验分析
- 6.1.1 最小置信度不同取值结果对比:展示不同最小置信度设置下的关联规则数量和质量差异。
- 6.1.2 固定因素与变化因素对比:比较固定因素下交通状态的变化趋势,以及引入变化因素后的不同。
6.2 随机森林结果分析
总结随机森林模型的预测性能,特别是其准确性、稳定性和解释力。
第7章 思考融合
7.1 时代背景
讨论当前社会背景下交通问题的重要性及其发展趋势。
7.2 社会影响
分析项目成果可能带来的社会效益,如减少交通拥堵、降低事故率等。
7.3 社会意义
探讨该研究对城市管理和社会生活的长远影响。
第8章 学习总结
回顾整个项目的实施过程,总结经验教训,提出未来研究方向。
附录:完整代码(Jupyter Notebook)
以下是一个简化的Jupyter Notebook示例代码片段,涵盖Apriori算法和随机森林算法的实现:
# 导入必要的库
import pandas as pd
import numpy as np
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 关联规则Apriori算法实现
def apriori_analysis(transactions):
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
df = pd.DataFrame(te_ary, columns=te.columns_)
frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True)
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.8)
return frequent_itemsets, rules
# 随机森林算法实现
def random_forest_analysis(X, y):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
predictions = rf_model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
importances = rf_model.feature_importances_
indices = np.argsort(importances)[::-1]
return mse, importances, indices
# 示例调用
transactions = [['A', 'B', 'C'], ['B', 'C'], ['A', 'B'], ['A', 'C'], ['A', 'B', 'C', 'D']]
frequent_itemsets, rules = apriori_analysis(transactions)
print("Apriori Results:")
print(frequent_itemsets)
print("\nAssociation Rules:")
print(rules)
# 假设有预处理好的DataFrame df
# df = pd.read_csv('path/to/traffic_data.csv')
# X = df.drop(columns=['target'])
# y = df['target']
# mse, importances, indices = random_forest_analysis(X, y)
# print(f"Random Forest MSE: {mse}")
# for f in range(X.shape[1]):
# print(f"{f + 1}. feature {X.columns[indices[f]]} ({importances[indices[f]]})")



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









