







使用遥感影像-语义分割数据集进行对比实验 以Postdam和Vaihingen两个数据集为例,也可对比WHDLD武汉大学数据集,2021LoveDa数据集,华为杯数据集等
图像分割遥感数据集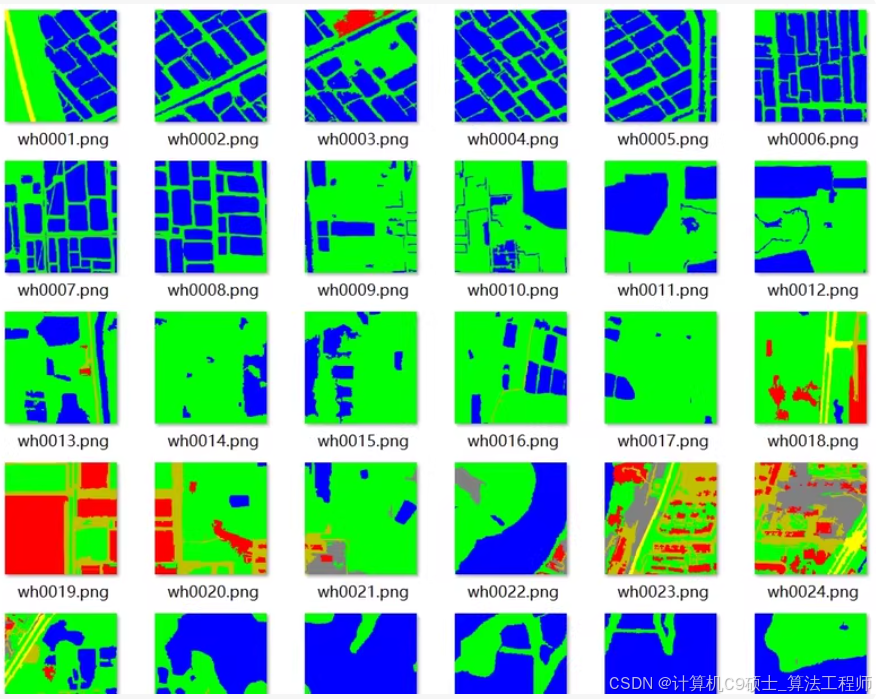
遥感影像-语义分割数据集包括:
Postdam数据集
Vaihingen数据集
WHDLD武汉大学数据集
2021LoveDa数据集
GID数据集
华为杯数据集
HRSCD数据集
NWPU VHR-10数据集
_做对比实验
使用遥感影像-语义分割数据集进行对比实验,几个步骤:数据准备、模型选择与训练、评估指标计算以及结果可视化。以Postdam和Vaihingen两个数据集为例,如何应用这些数据集,详细的代码示例。
1. 数据准备
首先,确保你已经下载了所需的数据集,并将其解压到本地目录。对于大多数数据集,你需要将它们转换为适合深度学习框架(如PyTorch或TensorFlow)使用的格式。
示例:将Potsdam和Vaihingen数据集转换为PyTorch格式
import os
from PIL import Image
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
class RemoteSensingDataset(Dataset):
def __init__(self, img_dir, mask_dir, transform=None):
self.img_dir = img_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = sorted(os.listdir(img_dir))
self.masks = sorted(os.listdir(mask_dir))
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.images[idx])
mask_path = os.path.join(self.mask_dir, self.masks[idx])
image = np.array(Image.open(img_path).convert("RGB"))
mask = np.array(Image.open(mask_path).convert("L"), dtype=np.float32)
if self.transform is not None:
augmentations = self.transform(image=image, mask=mask)
image = augmentations["image"]
mask = augmentations["mask"]
return image, mask
# 数据增强
transform = transforms.Compose([
transforms.ToTensor(),
# 其他数据增强操作可以在这里添加
])
# 加载数据集
potsdam_dataset = RemoteSensingDataset(
img_dir="path/to/potsdam/images",
mask_dir="path/to/potsdam/masks",
transform=transform
)
vaihingen_dataset = RemoteSensingDataset(
img_dir="path/to/vaihingen/images",
mask_dir="path/to/vaihingen/masks",
transform=transform
)
train_loader_potsdam = DataLoader(potsdam_dataset, batch_size=4, shuffle=True)
train_loader_vaihingen = DataLoader(vaihingen_dataset, batch_size=4, shuffle=True)
2. 模型选择与训练
选择一个适合语义分割任务的模型架构,例如U-Net、DeepLab等。这里我们使用U-Net作为示例。
U-Net模型定义
import torch.nn as nn
import torch.nn.functional as F
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512)
self.up2 = Up(512, 256)
self.up3 = Up(256, 128)
self.up4 = Up(128, 64)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
def __init__(self, in_channels, out_channels):
super(Up, self).__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
训练脚本
import torch.optim as optim
def train_model(model, dataloaders, criterion, optimizer, num_epochs=25):
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 10)
for phase in ['train']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = criterion(outputs, labels.long())
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
print(f'{phase} Loss: {epoch_loss:.4f}')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = UNet(n_channels=3, n_classes=6).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
dataloaders = {'train': train_loader_potsdam}
train_model(model, dataloaders, criterion, optimizer, num_epochs=10)
3. 评估指标计算
常见的语义分割评估指标包括像素准确率(Pixel Accuracy)、平均交并比(Mean Intersection over Union, mIoU)等。
def calculate_metrics(preds, targets, num_classes):
hist = np.zeros((num_classes, num_classes))
for p, t in zip(preds, targets):
hist += fast_hist(p.flatten(), t.flatten(), num_classes)
acc = np.diag(hist).sum() / hist.sum()
iu = np.diag(hist) / (hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist))
mean_iu = np.nanmean(iu)
return acc, mean_iu
def fast_hist(a, b, n):
k = (a >= 0) & (a < n)
return np.bincount(n * a[k].astype(int) + b[k], minlength=n ** 2).reshape(n, n)
# 假设preds和targets是预测和真实标签
acc, mean_iu = calculate_metrics(preds, targets, num_classes=6)
print(f"Accuracy: {acc}, Mean IoU: {mean_iu}")
4. 结果可视化
为了直观地查看模型的预测效果,可以将预测结果与原始图像和真实标签进行对比展示。
import matplotlib.pyplot as plt
def visualize_results(images, masks, preds, num_samples=3):
fig, axes = plt.subplots(num_samples, 3, figsize=(15, 5*num_samples))
for i in range(num_samples):
ax = axes[i]
ax[0].imshow(images[i].permute(1, 2, 0))
ax[0].set_title('Image')
ax[1].imshow(masks[i], cmap='gray')
ax[1].set_title('Ground Truth')
ax[2].imshow(preds[i], cmap='gray')
ax[2].set_title('Prediction')
plt.show()
# 预测
model.eval()
with torch.no_grad():
images, masks = next(iter(train_loader_potsdam))
images = images.to(device)
masks = masks.to(device)
preds = model(images)
preds = torch.argmax(preds, dim=1).cpu().numpy()
visualize_results(images.cpu(), masks.cpu().numpy(), preds)
如何使用Postdam和Vaihingen数据集进行语义分割模型的训练、评估及结果可视化。你可以根据需要调整模型架构、训练参数以及评估指标。对于其他数据集(如WHDLD武汉大学数据集、2021LoveDa数据集等)每个数据集可能有不同的标注方式和类别数量,因此在处理时需要注意这些差异。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









