







如何通过训练车辆车型数据集建立 _基于深度学习yolov8的道路车辆车型检测系统 检测道路车辆中的小汽车 公共汽车 货车等
文章目录
以下文字及代码仅供参考。
基于YOLOV8的车辆检测系统 基于深度学习的车辆检测系统
预先设立目标,软件类构建基础
项目介绍:
软件:Pycharm+Anaconda
环境:python=3.8 opencv-python PyQt5 torch1.9
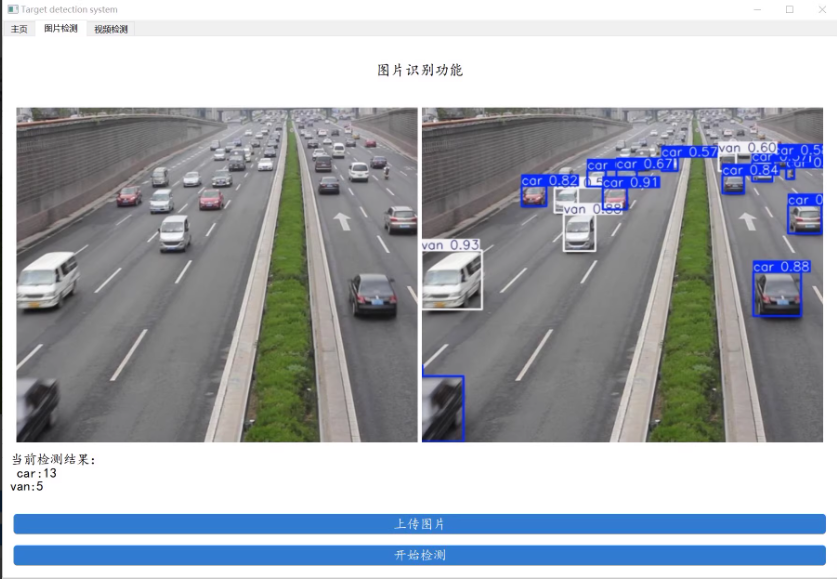
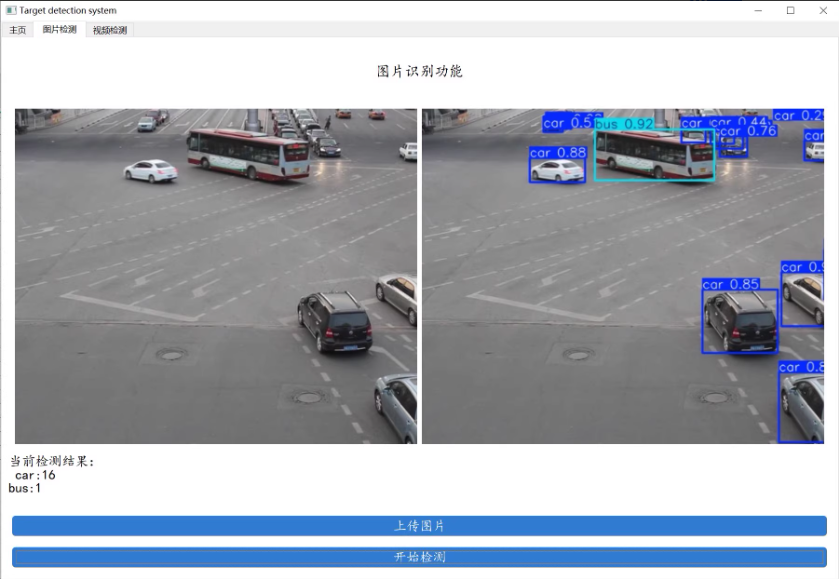
车辆种类一共分为4类[“car”、“bus”、“van”、“others”]
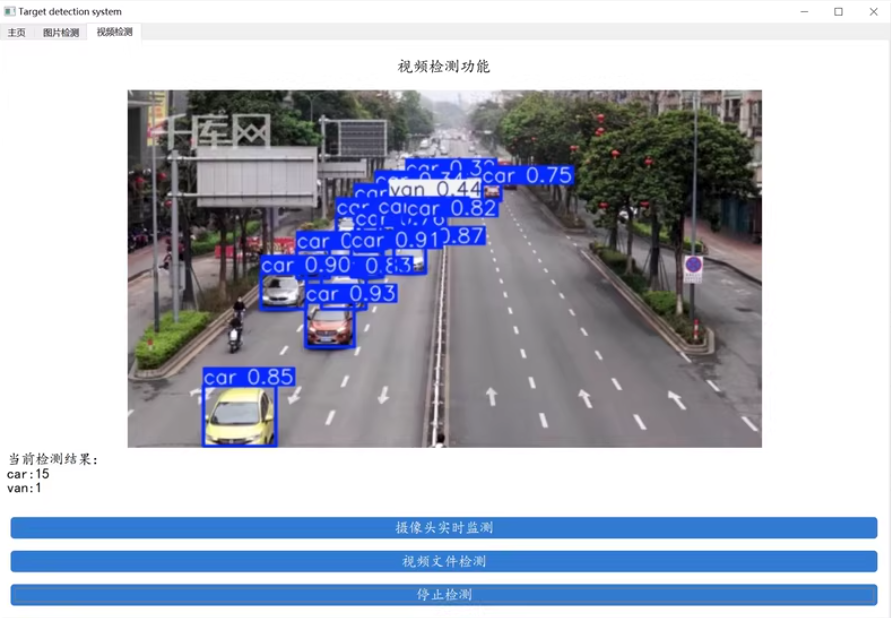
预实现功能
功能: 系统可用于车辆检测系统; 支持图片、视频及摄像头进行检测: 界面可实时显示目标位置、目标总数、置信度等信息: 支持图片或者视频的检测结果保存;
选择图片/视频/摄像头进行对于车辆检测。
基于YOLOv8的车辆检测系统:实时图像与视频分析解决方案
主函数
1. 主程序 (main.py)
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QFileDialog
from PyQt5.uic import loadUi
import cv2
import torch
from PIL import Image
from torchvision.transforms import ToTensor
class VehicleDetectionSystem(QMainWindow):
def __init__(self):
super().__init__()
loadUi('ui/main_window.ui', self)
self.model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt')
self.init_ui()
def init_ui(self):
self.btn_image.clicked.connect(self.detect_image)
self.btn_video.clicked.connect(self.detect_video)
self.btn_camera.clicked.connect(self.detect_camera)
def detect_image(self):
file_path, _ = QFileDialog.getOpenFileName(self, "Select Image", "", "Images (*.png *.xpm *.jpg)")
if file_path:
img = Image.open(file_path)
results = self.model(img)
results.show()
# Save or display results as needed
def detect_video(self):
file_path, _ = QFileDialog.getOpenFileName(self, "Select Video", "", "Videos (*.mp4 *.avi)")
if file_path:
cap = cv2.VideoCapture(file_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = self.model(frame)
results.render()
cv2.imshow('Video Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
def detect_camera(self):
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
results = self.model(frame)
results.render()
cv2.imshow('Camera Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
app = QApplication(sys.argv)
window = VehicleDetectionSystem()
window.show()
sys.exit(app.exec_())
为了构建一个基于YOLOv8的车辆检测系统,包含用户界面(UI)设计、模型推理和结果展示等,以下是一个详细的指南,包括所有必要的代码部分。这个项目将使用PyTorch进行深度学习模型推理,PyQt5用于创建图形用户界面。
1. 环境搭建
首先确保安装了必要的库:
pip install torch torchvision torchaudio opencv-python PyQt5
2. 模型加载与初始化
在model.py中编写模型加载函数:
import torch
def load_model(model_path):
model = torch.hub.load('ultralytics/yolov5', 'custom', path=model_path)
return model
3. 主程序逻辑
创建主程序文件main.py,负责处理用户输入、调用模型并显示结果:
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QFileDialog, QLabel, QVBoxLayout, QWidget
from PyQt5.QtGui import QPixmap
import cv2
from PIL import Image
import numpy as np
from model import load_model
class VehicleDetectionSystem(QMainWindow):
def __init__(self):
super().__init__()
self.model = load_model('path/to/best.pt')
self.init_ui()
def init_ui(self):
self.setWindowTitle('车辆检测系统')
self.setGeometry(100, 100, 800, 600)
self.image_label = QLabel(self)
self.image_label.setFixedSize(780, 580)
self.button_image = QPushButton('选择图片', self)
self.button_image.clicked.connect(self.detect_image)
self.button_video = QPushButton('选择视频', self)
self.button_video.clicked.connect(self.detect_video)
layout = QVBoxLayout()
layout.addWidget(self.image_label)
layout.addWidget(self.button_image)
layout.addWidget(self.button_video)
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
def detect_image(self):
file_name, _ = QFileDialog.getOpenFileName(self, "选择图片", "", "Images (*.png *.xpm *.jpg)")
if file_name:
img = Image.open(file_name)
results = self.model(img)
results.render()
for im in results.imgs:
q_img = QImage(im, im.shape[1], im.shape[0], QImage.Format_RGB888)
self.image_label.setPixmap(QPixmap.fromImage(q_img))
def detect_video(self):
file_name, _ = QFileDialog.getOpenFileName(self, "选择视频", "", "Videos (*.mp4 *.avi)")
if file_name:
cap = cv2.VideoCapture(file_name)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
results = self.model(frame)
results.render()
cv2.imshow('Video Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = VehicleDetectionSystem()
ex.show()
sys.exit(app.exec_())
4. 用户界面设计
上面的main.py文件已经包含了简单的UI设计,通过PyQt5创建了一个基本的窗口,其中包括一个用于显示图像/视频的标签和两个按钮(一个用于选择图片,另一个用于选择视频)。如果你希望使用.ui文件来设计更复杂的UI,可以使用Qt Designer工具创建.ui文件,并通过uic.loadUi()加载到Python脚本中。
5. 测试数据准备
确保你的测试图片和视频存放在指定的路径下,以便在运行时能够正确加载。
6. 运行程序
确保所有的依赖项都已安装,并且模型路径设置正确。然后可以通过以下命令运行程序:
python main.py
以上文字及代码仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









