







深度学习目标检测算法Yolo训练葡萄果实数据集 检测葡萄串,实现对农业自动化、精准农业等具有重要价值,自动识别并定位图像中的葡萄串
以下文字及代码仅供参考。
文章目录
数据集描述:
葡萄果园葡萄串检测数据集,2951张,yolo/voc标注
图像尺寸:864*1296

1
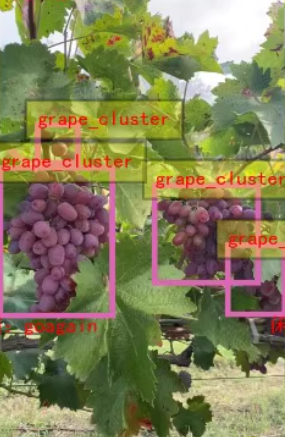
葡萄果园葡萄串检测数据集

数据集概述
- 图像总数:2951张
- 标注方式:支持YOLO和VOC两种格式
- 图像尺寸:864*1296像素
- 类别数:1个(grape_cluster)
数据划分
- 训练集:包含2296张图像
- 验证集:包含352张图像
- 测试集:包含303张图像

类别详情
- 类别名称:grape_cluster
- 出现于2908张图像中,总计有15475个标注框。
数据集用途
,研究者可以训练模型来自动识别并定位图像中的葡萄串,对于农业自动化、精准农业等具有重要价值。
以下是基于 YOLOv5 的葡萄果园葡萄串检测数据集的完整处理流程,包括数据准备、格式转换、数据划分、环境搭建、模型训练、推理和性能评估。我们将使用提供的信息(如图像数量、类别名称等)进行配置。
1. 数据准备
1.1 数据目录结构
假设数据集目录结构如下:
dataset/
├── images/
│ ├── train/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
│ ├── val/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
│ ├── test/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
├── labels/
│ ├── train/
│ │ ├── img1.txt
│ │ ├── img2.txt
│ │ └── ...
│ ├── val/
│ │ ├── img1.txt
│ │ ├── img2.txt
│ │ └── ...
│ ├── test/
│ │ ├── img1.txt
│ │ ├── img2.txt
│ │ └── ...
- 图像文件存储在
images/train/、images/val/和images/test/。 - 标注文件(YOLO格式)存储在
labels/train/、labels/val/和labels/test/。
1.2 YOLO 格式标注
每张图像对应的 .txt 文件包含以下内容:
<object-class> <x_center> <y_center> <width> <height>
<object-class>:类别索引(从 0 开始,这里只有grape_cluster类别,索引为 0)。<x_center>, <y_center>, <width>, <height>:归一化到[0, 1]的边界框坐标。
如果数据集提供的是 VOC 格式的 XML 文件,需要将其转换为 YOLO 格式。可以使用以下代码完成转换:
import xml.etree.ElementTree as ET
import os
def convert_voc_to_yolo(voc_xml_path, yolo_label_dir, class_mapping):
tree = ET.parse(voc_xml_path)
root = tree.getroot()
image_size = [int(root.find('size')[0].text), int(root.find('size')[1].text)]
yolo_lines = []
for obj in root.findall('object'):
class_name = obj.find('name').text
class_id = class_mapping[class_name]
bndbox = obj.find('bndbox')
xmin = float(bndbox.find('xmin').text)
ymin = float(bndbox.find('ymin').text)
xmax = float(bndbox.find('xmax').text)
ymax = float(bndbox.find('ymax').text)
# 归一化
x_center = (xmin + xmax) / 2.0 / image_size[0]
y_center = (ymin + ymax) / 2.0 / image_size[1]
width = (xmax - xmin) / image_size[0]
height = (ymax - ymin) / image_size[1]
yolo_lines.append(f"{class_id} {x_center} {y_center} {width} {height}")
base_name = os.path.splitext(os.path.basename(voc_xml_path))[0]
with open(os.path.join(yolo_label_dir, f"{base_name}.txt"), 'w') as f:
f.write("\n".join(yolo_lines))
# 示例调用
class_mapping = {'grape_cluster': 0}
convert_voc_to_yolo('path/to/xml/file.xml', 'path/to/yolo/labels/', class_mapping)
2. 环境搭建
安装依赖并克隆 YOLOv5 仓库:
# 安装 Python 环境
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 # CUDA 版本
pip install -r requirements.txt
# 克隆 YOLOv5 仓库
git clone https://github.com/ultralytics/yolov5
cd yolov5
3. 数据配置
3.1 创建数据配置文件
创建 data.yaml 文件,定义数据集路径和类别信息:
train: ../dataset/images/train
val: ../dataset/images/val
test: ../dataset/images/test
nc: 1
names: ['grape_cluster']
4. 模型训练
4.1 配置超参数
创建或修改 hyp.scratch.yaml 文件,调整超参数(如学习率、权重衰减等)。
4.2 启动训练
运行以下命令启动训练:
python train.py --img 864 --batch 16 --epochs 50 --data data.yaml --cfg yolov5s.yaml --weights yolov5s.pt --name grape_detection
--img 864:输入图像大小为 864x1296(YOLOv5 自动调整)。--batch 16:批量大小为 16。--epochs 50:训练 50 个 epoch。--cfg yolov5s.yaml:使用 YOLOv5 小型模型。--weights yolov5s.pt:预训练权重。--name grape_detection:保存实验结果的名称。
5. 模型推理
5.1 单张图像推理
使用训练好的模型对单张图像进行推理:
python detect.py --weights runs/train/grape_detection/weights/best.pt --img 864 --conf 0.25 --source path/to/image.jpg
5.2 批量推理
对整个文件夹的图像进行推理:
python detect.py --weights runs/train/grape_detection/weights/best.pt --img 864 --conf 0.25 --source path/to/test_images/
6. 性能评估
6.1 计算 mAP
运行以下命令评估模型性能:
python val.py --data data.yaml --weights runs/train/grape_detection/weights/best.pt --img 864 --task test
输出包括 mAP(平均精度均值)、Precision(精确率)、Recall(召回率)等指标。
7. 推理代码(Python API)
如果需要将 YOLOv5 集成到自定义代码中,可以使用以下代码:
from PIL import Image
import torch
from yolov5 import detect
# 加载模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/grape_detection/weights/best.pt')
# 推理单张图像
img_path = 'path/to/image.jpg'
results = model(img_path)
# 显示结果
results.show() # 可视化
print(results.pandas().xyxy[0]) # 打印检测结果
8. 总结
通过上述步骤,您可以完成基于 YOLOv5 的葡萄果园葡萄串检测任务。具体流程包括:
- 数据准备与格式转换(VOC 转 YOLO)。
- 环境搭建与数据配置。
- 模型训练与超参数调整。
- 模型推理与性能评估。
以上文字及代码仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









