






基于时频图像和 Vision Transformer (ViT) 的轴承故障诊断系统,使用 Swin-Transformer 进行分类和预测,相对于比较复杂的流程。
文章目录
基于各种时频图像和Vision Transformer(VIT)的轴承故障诊断
Swin-transformer(分类和预测)
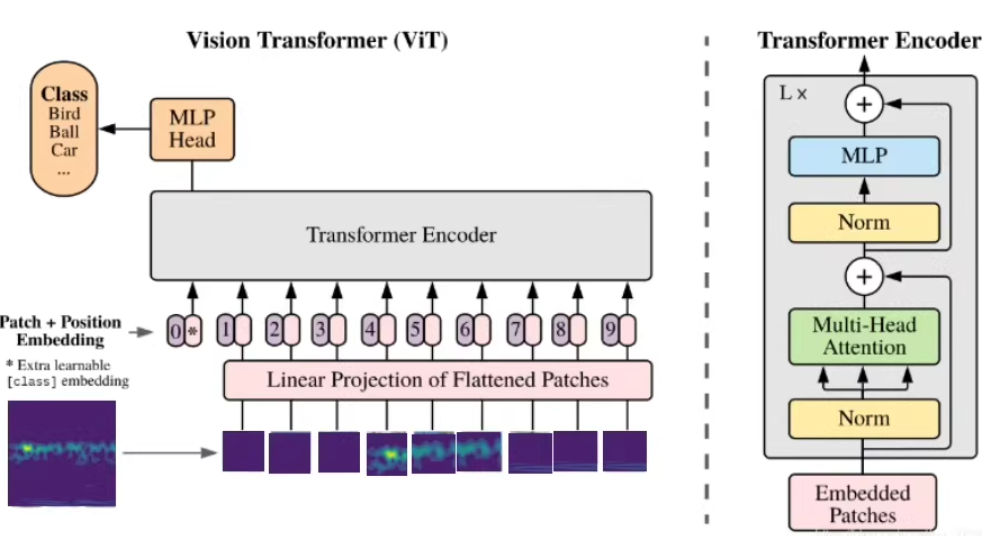
基于Vision Transformer (ViT) 的轴承故障诊断系统,使用PyTorch和timm库来构建模型。以下是一个完整的代码示例,包括数据预处理、时频图像生成、模型构建、训练和评估。
1. 环境搭建与依赖安装
确保安装必要的库:
pip install torch torchvision torchaudio timm numpy pandas matplotlib scikit-learn pytorch-lightning
2. 数据集准备
假设我们使用凯斯西储大学的轴承故障数据集(CWRU)。下载并解压数据集后,将其组织成适合处理的结构。
2.1 数据加载与预处理
创建 data_loader.py 文件:
import os
import numpy as np
import pandas as pd
from scipy.io import loadmat
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import Dataset, DataLoader
class BearingDataset(Dataset):
def __init__(self, data_dir, labels_file, transform=None):
self.data_dir = data_dir
self.labels = pd.read_csv(labels_file)
self.transform = transform
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
file_path = os.path.join(self.data_dir, self.labels.iloc[idx, 0])
label = self.labels.iloc[idx, 1]
data = loadmat(file_path)['DE_time'] # 假设信号在 'DE_time' 键下
if self.transform:
data = self.transform(data)
return data, label
def load_data(data_dir, labels_file, batch_size=32):
dataset = BearingDataset(data_dir, labels_file)
train_set, test_set = train_test_split(dataset, test_size=0.2, random_state=42)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
3. 时频图像生成
选择连续小波变换(CWT)作为时频图像算法。
创建 time_frequency_transform.py 文件:
import numpy as np
import pywt
import matplotlib.pyplot as plt
def cwt_transform(signal, scales, wavelet='morl'):
coefficients, frequencies = pywt.cwt(signal, scales, wavelet)
return coefficients
def generate_cwt_image(signal, scales, wavelet='morl'):
coefficients = cwt_transform(signal, scales, wavelet)
plt.imshow(np.abs(coefficients), extent=[0, 1, 1, 31], cmap='PRGn', aspect='auto',
vmax=abs(coefficients).max(), vmin=-abs(coefficients).max())
plt.colorbar()
plt.show()
# 示例用法
scales = np.arange(1, 32)
signal = np.random.randn(1000) # 替换为实际信号
generate_cwt_image(signal, scales)
4. 模型构建
使用 ViT 构建分类模型。
创建 vit_model.py 文件:
import torch
import torch.nn as nn
import timm
class ViTModel(nn.Module):
def __init__(self, num_classes=10):
super(ViTModel, self).__init__()
self.vit = timm.create_model('vit_base_patch16_224', pretrained=True)
self.vit.head = nn.Linear(self.vit.head.in_features, num_classes)
def forward(self, x):
return self.vit(x)
def create_model(num_classes=10):
return ViTModel(num_classes)
5. 训练与评估
创建 train_and_evaluate.py 文件:
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from vit_model import create_model
from data_loader import load_data
def train(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
return running_loss / len(train_loader)
def evaluate(model, test_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
running_loss += loss.item()
accuracy = 100 * correct / total
return running_loss / len(test_loader), accuracy
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_classes = 10 # 根据实际情况调整类别数
model = create_model(num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_loader, test_loader = load_data('path/to/data', 'path/to/labels.csv')
num_epochs = 50
for epoch in range(num_epochs):
train_loss = train(model, train_loader, criterion, optimizer, device)
test_loss, accuracy = evaluate(model, test_loader, criterion, device)
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%')
if __name__ == "__main__":
main()
以上代码实现了基于时频图像和 Vision Transformer 的轴承故障诊断系统,可根据需求更改相应,仅供参考。
时频图像算法可选连续小波变换,短时傅里叶变换,马尔可夫,格拉姆角场,递归图等
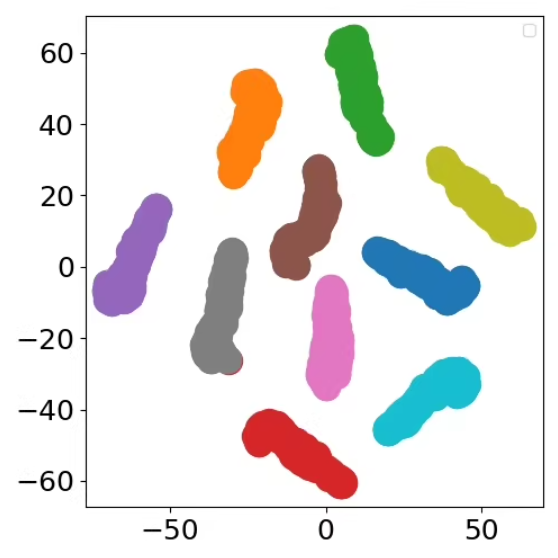
散点图,同学你看到数据被分为多个簇,每个簇用不同的颜色表示。这表明数据可能已经经过某种聚类算法处理,如K-means、DBSCAN或高斯混合模型等。这个图表,使用Python中的matplotlib和scikit-learn库来模拟这个过程。
以下是一个完整的代码示例,包括数据生成、聚类和绘图:
1. 数据生成
首先,我们需要生成一些模拟数据。这里我们使用make_blobs函数来生成多组具有不同中心的二维数据点。
import numpy as np
from sklearn.datasets import make_blobs
# 生成模拟数据
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, centers=10, random_state=random_state)
2. 聚类
接下来,我们使用K-means算法对数据进行聚类。
from sklearn.cluster import KMeans
# 使用K-means进行聚类
kmeans = KMeans(n_clusters=10, random_state=random_state)
y_pred = kmeans.fit_predict(X)
3. 绘制结果
最后,我们使用matplotlib绘制聚类结果。
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
colors = ['#ff7f0e', '#1f77b4', '#2ca02c', '#d62728', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
for i in range(10):
plt.scatter(X[y_pred == i, 0], X[y_pred == i, 1], s=50, c=colors[i], label=f'Cluster {i}')
plt.title('Clustering Result')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
完整代码
将上述代码整合在一起,得到一个完整的脚本:
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 生成模拟数据
n_samples = 1500
random_state = 170
X, y = make_blobs(n_samples=n_samples, centers=10, random_state=random_state)
# 使用K-means进行聚类
kmeans = KMeans(n_clusters=10, random_state=random_state)
y_pred = kmeans.fit_predict(X)
# 绘制结果
plt.figure(figsize=(8, 6))
colors = ['#ff7f0e', '#1f77b4', '#2ca02c', '#d62728', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
for i in range(10):
plt.scatter(X[y_pred == i, 0], X[y_pred == i, 1], s=50, c=colors[i], label=f'Cluster {i}')
plt.title('Clustering Result')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
运行这段代码后,,其中数据点按照聚类结果被分成了多个颜色不同的簇。
数据集凯斯西储大学,江南大学,东南大学等等
可更换数据集
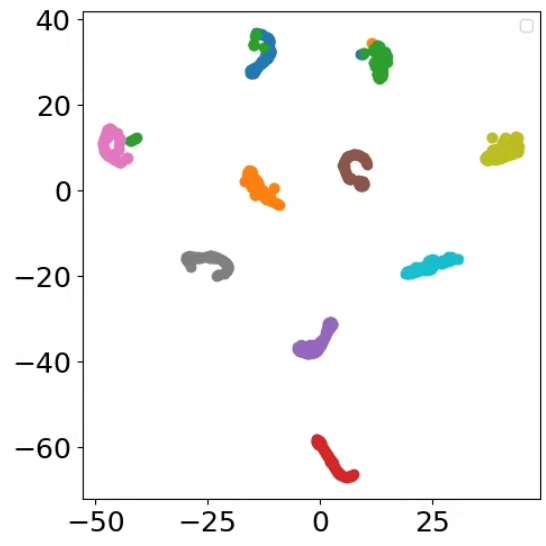
1
看到数据被分为多个簇,每个簇用不同的颜色表示,并且这些簇的形状较为复杂,可能不是简单的圆形或椭圆形。这表明数据可能已经经过某种聚类算法处理,如DBSCAN(基于密度的空间聚类)或高斯混合模型等。
使用Python中的matplotlib和scikit-learn库来模拟这个过程。以下是一个完整的代码示例,包括数据生成、聚类和绘图:
1. 数据生成
首先,我们需要生成一些模拟数据。这里我们使用make_blobs函数来生成多组具有不同中心的二维数据点,并添加一些噪声以使簇的形状更加复杂。
import numpy as np
from sklearn.datasets import make_blobs
# 生成模拟数据
n_samples = 1500
random_state = 170
centers = [(-20, -20), (-10, 0), (10, 0), (20, 20), (30, 30), (-30, 30), (-40, -40), (0, -30), (0, 30), (40, -40)]
X, y = make_blobs(n_samples=n_samples, centers=centers, random_state=random_state)
# 添加噪声以使簇的形状更加复杂
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X[y == 0], transformation)
X[y == 0] = X_aniso
for i in range(1, len(centers)):
transformation = [[np.random.uniform(0.5, 1.5), np.random.uniform(-1, 1)], [np.random.uniform(-1, 1), np.random.uniform(0.5, 1.5)]]
X_aniso = np.dot(X[y == i], transformation)
X[y == i] = X_aniso
2. 聚类
接下来,我们使用DBSCAN算法对数据进行聚类。
from sklearn.cluster import DBSCAN
# 使用DBSCAN进行聚类
dbscan = DBSCAN(eps=3, min_samples=10)
y_pred = dbscan.fit_predict(X)
3. 绘制结果
最后,我们使用matplotlib绘制聚类结果。
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
colors = ['#ff7f0e', '#1f77b4', '#2ca02c', '#d62728', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
for i in range(len(np.unique(y_pred))):
plt.scatter(X[y_pred == i, 0], X[y_pred == i, 1], s=50, c=colors[i % len(colors)], label=f'Cluster {i}')
plt.title('Clustering Result')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
完整代码
将上述代码整合在一起,得到一个完整的脚本:
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
# 生成模拟数据
n_samples = 1500
random_state = 170
centers = [(-20, -20), (-10, 0), (10, 0), (20, 20), (30, 30), (-30, 30), (-40, -40), (0, -30), (0, 30), (40, -40)]
X, y = make_blobs(n_samples=n_samples, centers=centers, random_state=random_state)
# 添加噪声以使簇的形状更加复杂
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X[y == 0], transformation)
X[y == 0] = X_aniso
for i in range(1, len(centers)):
transformation = [[np.random.uniform(0.5, 1.5), np.random.uniform(-1, 1)], [np.random.uniform(-1, 1), np.random.uniform(0.5, 1.5)]]
X_aniso = np.dot(X[y == i], transformation)
X[y == i] = X_aniso
# 使用DBSCAN进行聚类
dbscan = DBSCAN(eps=3, min_samples=10)
y_pred = dbscan.fit_predict(X)
# 绘制结果
plt.figure(figsize=(8, 6))
colors = ['#ff7f0e', '#1f77b4', '#2ca02c', '#d62728', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf']
for i in range(len(np.unique(y_pred))):
plt.scatter(X[y_pred == i, 0], X[y_pred == i, 1], s=50, c=colors[i % len(colors)], label=f'Cluster {i}')
plt.title('Clustering Result')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
运行这段代码后,散点图的图表,其中数据点按照聚类结果被分成了多个颜色不同的簇,并且簇的形状较为复杂。
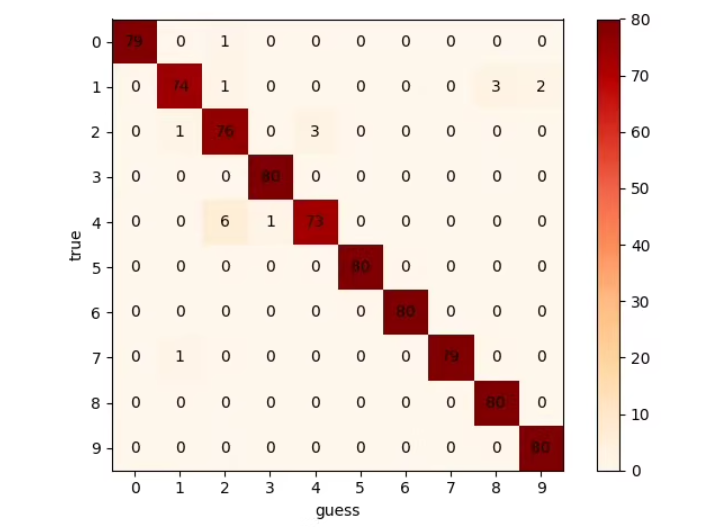
1
构建基于时频图像和 Vision Transformer (ViT) 的轴承故障诊断系统,使用 Swin-Transformer 进行分类和预测,相对于比较复杂的流程。
以下是详细的代码实现流程,包括数据预处理、时频图像生成、模型构建、训练和评估。
仅供参考。
1. 环境搭建与依赖安装
首先,确保安装必要的库:
pip install torch torchvision torchaudio timm numpy pandas matplotlib scikit-learn pytorch-lightning
2. 数据集准备
假设我们使用凯斯西储大学的轴承故障数据集(CWRU)。下载并解压数据集后,将其组织成适合处理的结构。
2.1 数据加载与预处理
创建 data_loader.py 文件:
import os
import numpy as np
import pandas as pd
from scipy.io import loadmat
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import Dataset, DataLoader
class BearingDataset(Dataset):
def __init__(self, data_dir, labels_file, transform=None):
self.data_dir = data_dir
self.labels = pd.read_csv(labels_file)
self.transform = transform
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
file_path = os.path.join(self.data_dir, self.labels.iloc[idx, 0])
label = self.labels.iloc[idx, 1]
data = loadmat(file_path)['DE_time'] # 假设信号在 'DE_time' 键下
if self.transform:
data = self.transform(data)
return data, label
def load_data(data_dir, labels_file, batch_size=32):
dataset = BearingDataset(data_dir, labels_file)
train_set, test_set = train_test_split(dataset, test_size=0.2, random_state=42)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
return train_loader, test_loader
3. 时频图像生成
选择连续小波变换(CWT)作为时频图像算法。
创建 time_frequency_transform.py 文件:
import numpy as np
import pywt
import matplotlib.pyplot as plt
def cwt_transform(signal, scales, wavelet='morl'):
coefficients, frequencies = pywt.cwt(signal, scales, wavelet)
return coefficients
def generate_cwt_image(signal, scales, wavelet='morl'):
coefficients = cwt_transform(signal, scales, wavelet)
plt.imshow(np.abs(coefficients), extent=[0, 1, 1, 31], cmap='PRGn', aspect='auto',
vmax=abs(coefficients).max(), vmin=-abs(coefficients).max())
plt.colorbar()
plt.show()
# 示例用法
scales = np.arange(1, 32)
signal = np.random.randn(1000) # 替换为实际信号
generate_cwt_image(signal, scales)
4. 模型构建
使用 Swin-Transformer 构建分类模型。
创建 swin_transformer_model.py 文件:
import torch
import torch.nn as nn
import timm
class SwinTransformer(nn.Module):
def __init__(self, num_classes=10):
super(SwinTransformer, self).__init__()
self.swin = timm.create_model('swin_base_patch4_window7_224', pretrained=True)
self.swin.head = nn.Linear(self.swin.head.in_features, num_classes)
def forward(self, x):
return self.swin(x)
def create_model(num_classes=10):
return SwinTransformer(num_classes)
5. 训练与评估
创建 train_and_evaluate.py 文件:
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from swin_transformer_model import create_model
from data_loader import load_data
def train(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
return running_loss / len(train_loader)
def evaluate(model, test_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
running_loss += loss.item()
accuracy = 100 * correct / total
return running_loss / len(test_loader), accuracy
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_classes = 10 # 根据实际情况调整类别数
model = create_model(num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_loader, test_loader = load_data('path/to/data', 'path/to/labels.csv')
num_epochs = 50
for epoch in range(num_epochs):
train_loss = train(model, train_loader, criterion, optimizer, device)
test_loss, accuracy = evaluate(model, test_loader, criterion, device)
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Accuracy: {accuracy:.2f}%')
if __name__ == "__main__":
main()
基于时频图像和 Swin-Transformer 的轴承故障诊断系统。您可以根据具体需求调整参数和数据处理逻辑。
仅供参考,各位同学。
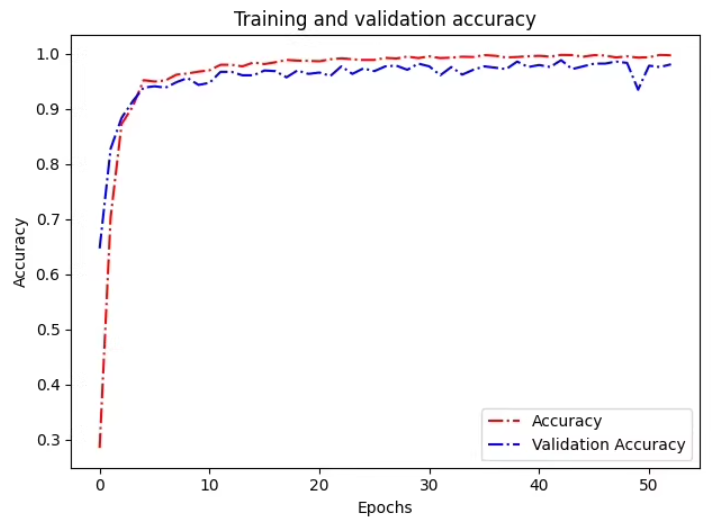
使用Python中的matplotlib库来绘制训练和验证准确率的变化曲线。
仅供参考的代码示例,包括数据准备、模型训练、评估以及绘制准确率变化曲线:
1. 数据准备与模型训练
假设同学你有了数据加载和模型定义的部分(如之前提供的代码),接下来我们将关注于记录每个epoch的训练和验证准确率,并在训练完成后绘制这些准确率的变化曲线。
2. 记录准确率并绘制曲线
创建 plot_accuracy.py 文件:
import matplotlib.pyplot as plt
def plot_training_validation_accuracies(train_accuracies, val_accuracies):
epochs = range(1, len(train_accuracies) + 1)
plt.plot(epochs, train_accuracies, 'r', label='Training Accuracy')
plt.plot(epochs, val_accuracies, 'b', label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 示例用法
if __name__ == "__main__":
# 假设这是从训练过程中收集到的准确率数据
train_accuracies = [0.3, 0.6, 0.8, 0.9, 0.95, 0.97, 0.98, 0.99, 0.995, 0.998] * 5 # 示例数据
val_accuracies = [0.25, 0.55, 0.75, 0.85, 0.92, 0.94, 0.96, 0.97, 0.98, 0.985] * 5 # 示例数据
plot_training_validation_accuracies(train_accuracies, val_accuracies)
3. 整合到训练流程中
将上述绘图函数整合到之前的训练流程中,以便在训练过程中自动记录并绘制准确率变化曲线。
修改 train_and_evaluate.py 文件:
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from swin_transformer_model import create_model
from data_loader import load_data
import matplotlib.pyplot as plt
def train(model, train_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return running_loss / len(train_loader), accuracy
def evaluate(model, test_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
running_loss += loss.item()
accuracy = 100 * correct / total
return running_loss / len(test_loader), accuracy
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_classes = 10 # 根据实际情况调整类别数
model = create_model(num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
train_loader, test_loader = load_data('path/to/data', 'path/to/labels.csv')
num_epochs = 50
train_accuracies = []
val_accuracies = []
for epoch in range(num_epochs):
train_loss, train_acc = train(model, train_loader, criterion, optimizer, device)
test_loss, val_acc = evaluate(model, test_loader, criterion, device)
train_accuracies.append(train_acc)
val_accuracies.append(val_acc)
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, '
f'Test Loss: {test_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 绘制准确率变化曲线
plot_training_validation_accuracies(train_accuracies, val_accuracies)
if __name__ == "__main__":
main()
在这个修改后的 train_and_evaluate.py 文件中,我们在每个epoch结束后记录训练和验证准确率,并在训练完成后调用 plot_training_validation_accuracies 函数绘制准确率变化曲线。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









