







玉米粒好坏目标检测数据集

共1311张图像,共2类别,2类别分别是
好 坏
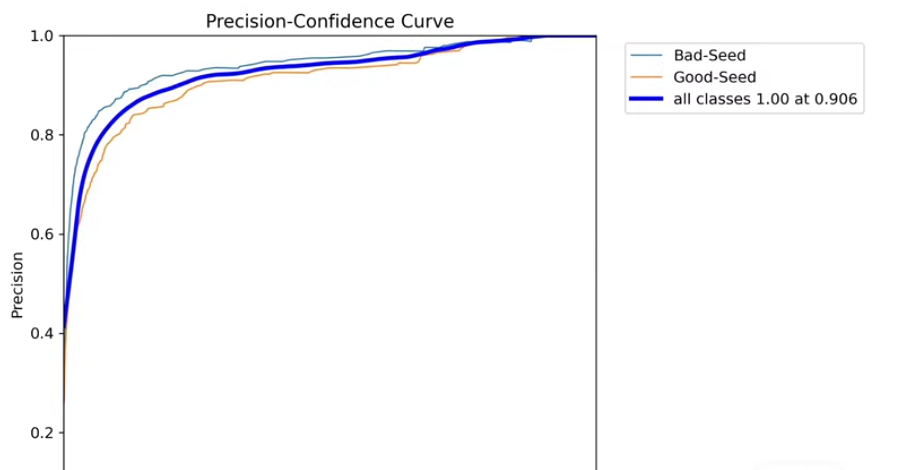
map50 99%以上
数据集划分:【训练集、验证集、测试集】【941:267:133】
数据集采用YOLO标注格式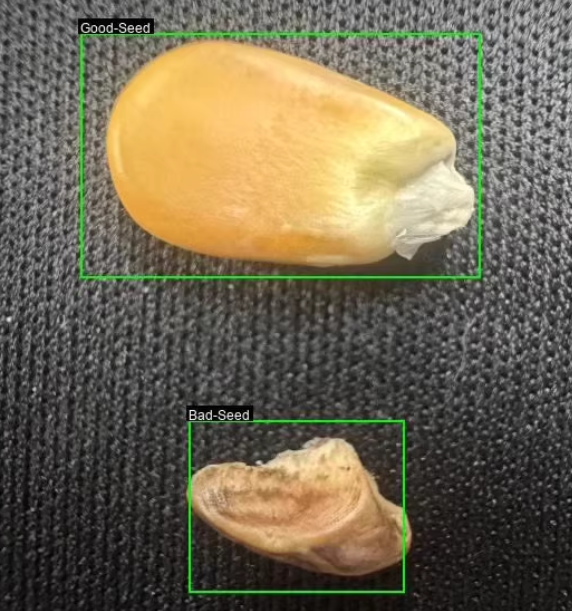
玉米粒好坏目标检测的数据集,包含1311张图像,分为“好”和“坏”两个类别。数据集已经按照941:267:133的比例划分为训练集、验证集和测试集,并且标注格式为YOLO格式。
数据集准备与组织结构
同学首先,确保你的数据集按照以下目录结构进行组织:
corn_seeds_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
├── labels/
│ ├── train/
│ ├── val/
│ └── test/
└── corn_seeds.yaml
YAML配置文件
创建一个corn_seeds.yaml文件来定义数据集的配置:
train: ./images/train
val: ./images/val
test: ./images/test
nc: 2
names: ['Good-Seed', 'Bad-Seed']
安装依赖库
确保安装了必要的Python库,特别是Ultralytics的YOLOv8库:
pip install ultralytics
加载预训练模型
使用YOLOv8加载一个预训练模型,例如yolov8n.pt(小型模型)或yolov8l.pt(大型模型),根据你的硬件资源选择合适的模型:
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt')
训练模型
使用你的数据集对模型进行训练:
results = model.train(
data='path/to/corn_seeds.yaml',
epochs=100, # 根据需要调整训练轮数
imgsz=640, # 输入图像大小
batch=16, # 批次大小
name='corn_seed_detector',
project='runs/corn_seeds',
save=True,
save_period=5, # 每5个epoch保存一次权重
device=0 # 使用GPU(若可用)
)
模型评估
在验证集上评估模型性能:
metrics = model.val()
print(f"mAP@0.5: {metrics.box.map50:.4f}, mAP@0.5:0.95: {metrics.box.map:.4f}")
推理预测
在新的图像上进行推理预测:
import cv2
# 加载训练好的模型权重
model = YOLO('path/to/best.pt')
# 对单张图片进行预测
img_path = 'path/to/test_image.jpg'
results = model.predict(source=img_path, show=True, conf=0.25)
for result in results:
annotated_frame = result.plot() # 绘制检测框和标签
cv2.imshow("Detection", annotated_frame)
cv2.waitKey(0)
cv2.destroyAllWindows()
基于训练好的模型权重构建一套用于玉米粒好坏识别的深度学习系统,
从加载预训练模型到部署整个系统的各个环节。
1. 环境准备
同学首先,确保你的环境中安装了所有必要的依赖库。如果你使用的是YOLOv8作为模型框架,可以这样安装:
pip install ultralytics
此外,根据需要可能还需要安装其他库如opencv-python等,以便进行图像处理和显示结果。
2. 加载预训练模型
在你的Python脚本或Jupyter Notebook中,加载训练好的模型权重:
from ultralytics import YOLO
# 替换为你的模型权重文件路径
model = YOLO('path/to/your/best.pt')
3. 推理与检测
编写代码对新图像进行推理,识别其中的玉米粒并判断其好坏。
对单张图片进行推理
import cv2
# 单张图片推理示例
img_path = 'path/to/test_image.jpg'
results = model.predict(source=img_path, save=True, conf=0.5) # conf参数调整置信度阈值
for result in results:
img = cv2.imread(img_path)
for box in result.boxes:
x1, y1, x2, y2 = [int(x) for x in box.xyxy]
cls = int(box.cls.item())
label = f'{result.names[cls]} {box.conf.item():.2f}'
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('Detected Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
批量处理图像
如果你想批量处理图像,只需遍历指定目录下的所有图片,并对每一张执行上述推理逻辑。
4. 构建用户界面
系统更加用户友好,可以考虑构建一个简单的图形用户界面(GUI)。PyQt或Tkinter都是不错的选择。
这里给出一个简单的Tkinter例子来打开本地图片并显示检测结果:
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
def open_image():
file_path = filedialog.askopenfilename()
if not file_path:
return
img = Image.open(file_path)
img = img.resize((600, 600)) # 调整大小以适应窗口
img_tk = ImageTk.PhotoImage(img)
# 进行预测并将结果显示
results = model.predict(source=file_path, save=False)
# 假设你已经将预测结果绘制回原图
# 更新label显示新的图片
panel.configure(image=img_tk)
panel.image = img_tk
root = tk.Tk()
panel = tk.Label(root)
panel.pack(pady=10)
btn = tk.Button(root, text="Open Image", command=open_image)
btn.pack(side="bottom")
root.mainloop()
5. 部署
-
导出模型:为了方便部署,可以将模型导出为ONNX格式。
model.export(format="onnx") -
Web服务:利用Flask或FastAPI创建一个RESTful API服务,接收上传的图片并返回检测结果。
-
移动应用:通过TensorFlow Lite或者ONNX Runtime将模型部署到移动端。
结论
构建一套基于深度学习的玉米粒好坏识别系统。该系统不仅能对单一图像做出准确的分类,还能扩展为支持批量处理、GUI交互以及多种部署方式



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









