







医学类数据集的训练应用 yolov8如何训练舌象舌头舌苔检测数据集,依据训练的舌苔数据集权重,推理,建立基于深度学习舌苔检测系统
以下文字及代码仅供参考。
医学类数据集 舌象舌头舌苔检测数据集
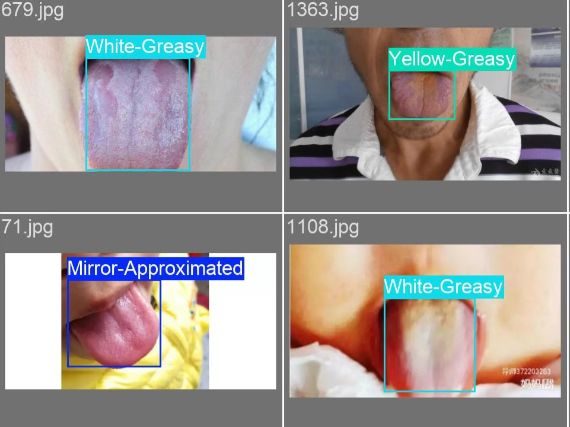
1
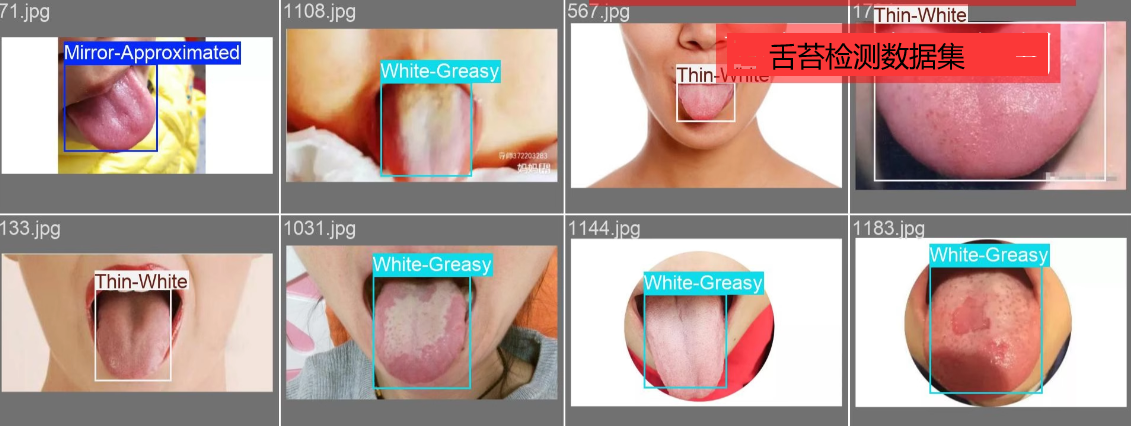
舌象检测 YOLO 数据集统计表(共 5 类)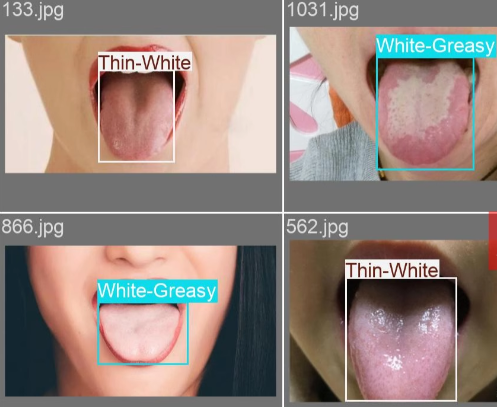
| 类别名称 | 图片数量 | 标注框数量 | 训练集图片数(约80%) | 验证集图片数(约20%) |
|---|---|---|---|---|
| Mirror-Approximated | 112 | 112 | 90 | 22 |
| White-Greasy | 691 | 691 | 553 | 138 |
| Thin-White | 532 | 532 | 426 | 106 |
| Yellow-Greasy | 85 | 85 | 68 | 17 |
| Grey-Black | 52 | 52 | 40 | 12 |
| 总计 | 1472 | 1472 | 1177 (80%) | 295 (20%) |
数据说明:
- 数据集总图片数:1472 张
- 总标注框数:1472 个(每张图一个标注框)
- 按照 8:2 的比例划分为训练集和验证集
- 所有类别的标注框数量与图片数量一致(即每张图片仅包含一个舌象对象)
使用YOLOv8训练你的舌苔检测数据集,并基于训练好的权重建立一个深度学习舌苔检测系统,同学需要按照以下步骤进行操作。从准备环境、组织数据、编写训练代码到推理过程进行详细介绍。
示例代码哦
准备环境
首先确保安装了必要的依赖库:
pip install ultralytics opencv-python-headless matplotlib
组织数据
确保你的数据集已经按照YOLO格式组织好,即包含图像和相应的标注文件(.txt),这些标注文件应该位于与图像相同的目录下,并且命名相同但扩展名为.txt。每个标注文件应包括类别ID和边界框坐标(中心x, 中心y, 宽度, 高度),所有值均归一化。
创建YOLO配置文件
创建一个data.yaml文件,用于描述数据集的路径和类别信息。例如:
train: /path/to/train/images
val: /path/to/val/images
nc: 5 # 类别数量
names: ['Mirror-Approximated', 'White-Greasy', 'Thin-White', 'Yellow-Greasy', 'Grey-Black']
编写训练代码
下面是一个简单的Python脚本,用于加载数据集并开始训练:
from ultralytics import YOLO
# 加载预训练模型或随机初始化
model = YOLO('yolov8n.yaml') # 使用YOLOv8 nano架构作为示例,可以根据需要调整
# 开始训练
results = model.train(data='/path/to/data.yaml', epochs=100, imgsz=640, batch=16)
# 训练完成后保存最佳权重
best_weights_path = model.save('/path/to/save/best.pt')
print(f"Best weights saved to {best_weights_path}")
推理与部署
完成训练后,你可以使用训练得到的最佳权重对新的图像进行预测。以下是进行推理的一个简单例子:
from ultralytics import YOLO
import cv2
def detect_image(image_path):
# 加载训练好的模型权重
model = YOLO('/path/to/save/best.pt')
# 对新图片进行预测
results = model.predict(source=image_path, save=True, conf=0.25)
for result in results:
img = cv2.imread(image_path)
for box in result.boxes:
x1, y1, x2, y2 = [int(x) for x in box.xyxy]
cls = int(box.cls.item())
label = f'{result.names[cls]} {box.conf.item():.2f}'
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(img, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.imshow('Detected Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
detect_image('path/to/test_image.png') # 替换为你要测试的图片路径
如何进行性能评估?
性能评估是任何深度学习系统的重要组成部分,对于医疗应用如舌苔检测系统。通过性能评估,模型的准确性、召回率、精确度等关键指标,并根据这些信息进行优化。基于YOLOv8的舌苔检测系统进行性能评估的步骤和方法。
1. 准备验证集
确保图像同学已经按照8:2的比例划分了训练集和验证集。验证集用于在训练过程中以及训练完成后评估模型的性能。验证集应尽可能反映实际应用场景中的数据分布。
2. 使用验证集评估模型
使用YOLOv8提供的内置函数来评估模型在验证集上的表现。这可以通过调用model.val()函数完成。
from ultralytics import YOLO
# 加载训练好的模型权重
model = YOLO('/path/to/save/best.pt')
# 在验证集上评估模型性能
metrics = model.val()
# 打印评估结果
print(f"Model mAP: {metrics.box.map}") # 输出mAP值
print(f"Model mAP@0.5: {metrics.box.map50}") # 输出mAP@0.5值
print(f"Model mAP@0.5:0.95: {metrics.box.map}") # 输出mAP@0.5:0.95值
这里metrics.box.map代表平均精度均值(mean Average Precision, mAP),是衡量目标检测模型整体性能的一个重要指标。map50表示IoU阈值为0.5时的mAP,而map通常指的是IoU从0.5到0.95之间的平均mAP。
3. 分类报告
同学如果需要更详细的分类性能分析,可以生成一个分类报告,显示每个类别的精确度、召回率、F1分数等:
from sklearn.metrics import classification_report
# 假设y_true和y_pred分别是真实标签和预测标签列表
# 注意:你需要将YOLO输出转换成适合classification_report格式的数据
print(classification_report(y_true, y_pred, target_names=['Mirror-Approximated', 'White-Greasy', 'Thin-White', 'Yellow-Greasy', 'Grey-Black']))
请注意,YOLO输出的是边界框及其对应的类别,直接获取每个图像的分类标签可能需要额外的处理步骤,例如根据置信度最高的预测框确定每个图像的类别。是的
4. 可视化混淆矩阵
混淆矩阵是一个强大的工具,可以帮助理解模型在不同类别上的表现。你可以使用matplotlib或seaborn库来绘制混淆矩阵:
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# 计算混淆矩阵
cm = confusion_matrix(y_true, y_pred)
# 绘制混淆矩阵
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d', xticklabels=['Mirror-Approximated', 'White-Greasy', 'Thin-White', 'Yellow-Greasy', 'Grey-Black'], yticklabels=['Mirror-Approximated', 'White-Greasy', 'Thin-White', 'Yellow-Greasy', 'Grey-Black'])
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.show()
仅供参考学习,同学


















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









