






如何训练自己的数据集——游泳溺水数据集
图片数量: 1715张图片
标注格式: YOLO txt格式
类别nc: 2
类别名称: [’ Drowning’,’ Swimming’]
实例统计: [[’ Dr owning ’
951],[’ Swimming’
2165] ]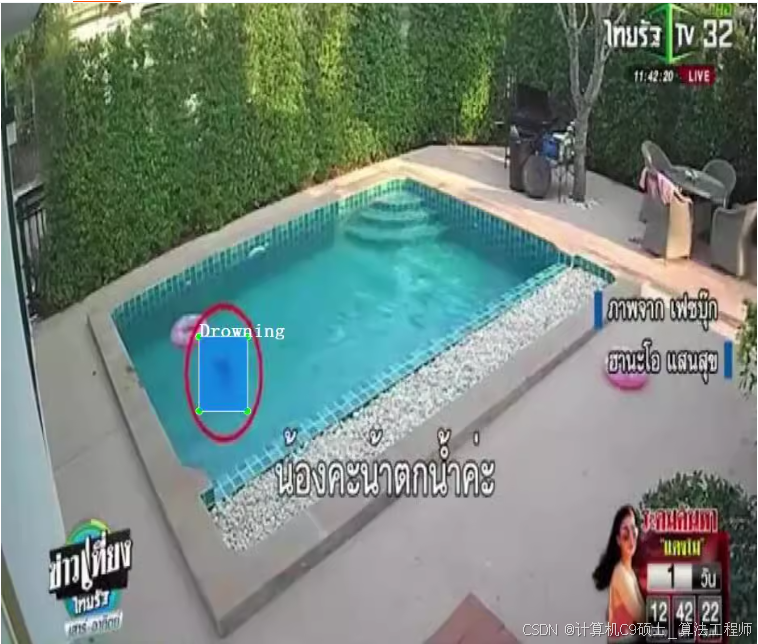

使用YOLOv8来训练你的游泳和溺水检测数据集。以下是详细的步骤和完整的代码示例。
步骤概述
- 安装依赖
- 准备数据集
- 配置YOLOv8
- 训练模型
- 可视化评估
1. 安装依赖
首先确保你已经安装了必要的库,特别是ultralytics库,它是YOLOv8的核心库。
pip install ultralytics
2. 准备数据集
假设你的数据集格式符合YOLO的要求,即图像文件夹和对应的标注文件夹。数据集结构应如下所示:
datasets/
├── images/
│ ├── train/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ └── ...
│ └── val/
│ ├── img1.jpg
│ ├── img2.jpg
│ └── ...
└── labels/
├── train/
│ ├── img1.txt
│ ├── img2.txt
│ └── ...
└── val/
├── img1.txt
├── img2.jpg
└── ...
每个.txt文件对应一张图片,内容格式为:
<class_id> <x_center> <y_center> <width> <height>
其中,坐标值都是归一化的(范围在0到1之间)。
3. 配置YOLOv8
创建一个YAML文件来配置数据集路径和类别信息。例如,创建一个名为swimming_drowning.yaml的文件:
train: ../datasets/images/train
val: ../datasets/images/val
nc: 2
names: ['Drowning', 'Swimming']
注意:类别名称应该是 'Drowning' 和 'Swimming',而不是 ' Dr owing ' 或 ' Swimming '。
4. 训练模型
编写训练脚本,使用YOLOv8进行训练。以下是完整的训练脚本:
解释
- 加载预训练模型:我们从预训练的YOLOv8n模型开始。
- 训练模型:使用
train方法进行训练。参数包括数据集配置文件路径、训练轮数、图像大小、批量大小、工作线程数和设备。 - 评估模型:使用
val方法对模型进行评估。 - 导出模型:将训练好的模型导出为ONNX格式以便部署。
- 可视化评估:使用
predict方法在验证集上进行预测,并显示和保存结果。
运行脚本
保存上述脚本到一个Python文件中,例如train_swimming_drowning.py,然后运行该脚本:
python train_swimming_drowning.py
、


















 2735
2735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









