







基于YOLOv8➕pyqt5的裂缝检测系统
文章目录
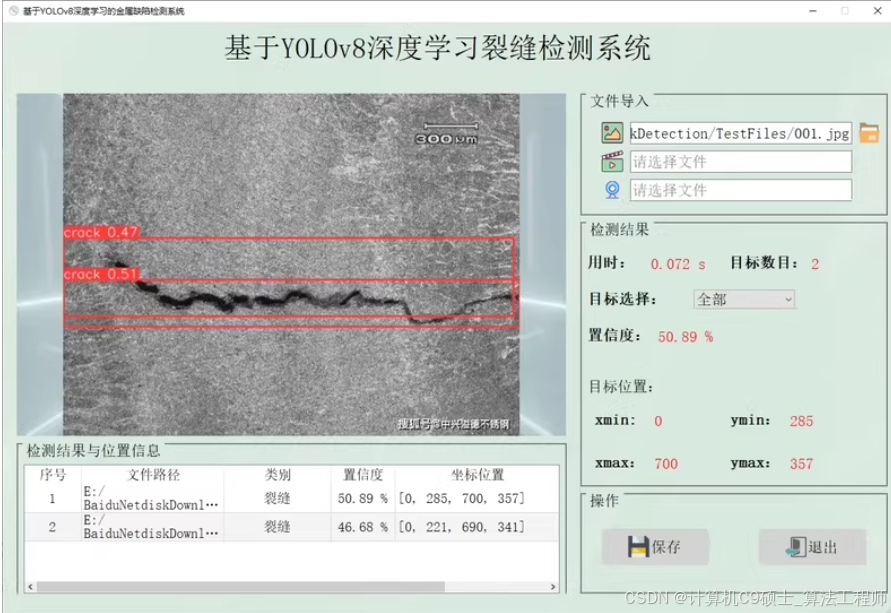
构建一个基于YOLOv8和PyQt5的裂缝检测系统涉及多个步骤,包括数据集准备、模型训练、评估以及用户界面的设计。
项目介绍:
算法:YOLOv8/yolov11
软件:Pycharm+Anaconda
环境:python=3.9 opencv PyQt5 torch1.9
功能:在界面中选择各种图片,可以是自己在路边拍摄的图片,可以选择视频,可以调用摄像头,进行裂缝检测,检测速度快,检测精度高。
以下文章及代码仅供参考。
为了实现一个基于YOLOv8(的裂缝检测系统,并集成到PyQt5界面中,使其支持图片、视频和摄像头输入,下面是一个详细的指南。从环境设置开始,直到实现最终的功能。
训练流程
1. 数据集准备
首先,确保你的数据集已准备好,并按照YOLO格式组织。每个图像文件夹应包含相应的标签文件夹,其中标签文件使用YOLO格式记录边界框信息(类别ID, x_center, y_center, width, height),所有数值均为相对于图像尺寸的归一化值。
创建data.yaml文件来描述数据集路径及类别信息:
train: ./path/to/train/images
val: ./path/to/val/images
nc: 1 # 假设只有一个类别 - 裂缝
names: ['crack']
2. 环境设置
安装必要的依赖项并配置环境:
conda create -n yolov5_env python=3.9
conda activate yolov5_env
pip install torch==1.9 torchvision torchaudio
pip install opencv-python PyQt5
pip install ultralytics # 安装YOLOv5或YOLOv8的相关库
3. 模型训练
下载预训练模型权重,并在自己的数据集上进行微调。下面是一个简单的训练脚本示例:
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov5s.pt') # 或者选择其他合适的预训练模型
# 开始训练
model.train(data='path/to/data.yaml', epochs=100, imgsz=640)
epochs: 训练轮次,可以根据需要调整。imgsz: 输入图像尺寸,建议根据硬件资源调整大小。
4. 数据增强
在data.yaml文件中启用数据增强:
augment: True # 启用数据增强
YOLOv5内置支持多种数据增强方法,包括翻转、旋转、裁剪等,可以有效增加训练集多样性,提高模型泛化能力。
环境设置
首先确保你的开发环境已正确配置:
- 安装Anaconda:用于管理Python环境。
- 创建并激活环境:
conda create -n yolov5_env python=3.9 conda activate yolov5_env - 安装必要的依赖:
pip install torch==1.9 torchvision torchaudio pip install opencv-python PyQt5 pip install ultralytics # 安装YOLOv5或YOLOv8的相关库
数据集准备
确保你的数据集按照YOLO格式组织,并准备好data.yaml文件,描述训练集和验证集路径及类别信息。
模型训练
使用YOLOv5/v8模型对裂缝数据集进行训练。这里以YOLOv5为例:
from ultralytics import YOLO
model = YOLO('yolov5s.pt') # 使用预训练模型作为起点
model.train(data='path/to/data.yaml', epochs=100, imgsz=640)
UI设计与功能实现
接下来是关键部分——构建PyQt5界面,并集成裂缝检测功能。
UI设计
在PyCharm中创建一个新的PyQt5项目,编写UI代码如下:
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QPushButton, QFileDialog, QLabel, QVBoxLayout, QWidget
from PyQt5.QtGui import QPixmap, QImage
from PyQt5.QtCore import Qt, QThread, pyqtSignal
import cv2
from ultralytics import YOLO
class CrackDetectionApp(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
self.model = YOLO('runs/train/exp/weights/best.pt') # 加载最佳权重
def initUI(self):
self.setWindowTitle('裂缝检测系统')
self.setGeometry(100, 100, 800, 600)
self.button_image = QPushButton('上传图片', self)
self.button_image.clicked.connect(self.upload_image)
self.button_video = QPushButton('上传视频', self)
self.button_video.clicked.connect(self.upload_video)
self.button_camera = QPushButton('调用摄像头', self)
self.button_camera.clicked.connect(self.use_camera)
self.image_label = QLabel(self)
self.image_label.setGeometry(10, 50, 780, 540)
layout = QVBoxLayout()
layout.addWidget(self.button_image)
layout.addWidget(self.button_video)
layout.addWidget(self.button_camera)
layout.addWidget(self.image_label)
container = QWidget()
container.setLayout(layout)
self.setCentralWidget(container)
def upload_image(self):
fname, _ = QFileDialog.getOpenFileName(self, '打开图片', '', "Image files (*.jpg *.png)")
if fname:
self.detect_cracks(fname)
def detect_cracks(self, source):
results = self.model.predict(source=source, save=True) # 可选地保存结果
image = cv2.imread(results[0].path)
for box in results[0].boxes.xyxy:
pt1, pt2 = tuple(map(int, box[:2])), tuple(map(int, box[2:]))
cv2.rectangle(image, pt1, pt2, (0, 255, 0), 2)
self.display_image(image)
def display_image(self, img):
rgb_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w, ch = rgb_img.shape
bytes_per_line = ch * w
convert_to_Qt_format = QImage(rgb_img.data, w, h, bytes_per_line, QImage.Format_RGB888)
pixmap = QPixmap.fromImage(convert_to_Qt_format)
self.image_label.setPixmap(pixmap)
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = CrackDetectionApp()
ex.show()
sys.exit(app.exec_())
视频和摄像头支持
为了处理视频和摄像头输入,你可以扩展上述代码,添加相应的按钮和逻辑。考虑到篇幅限制,这里仅提供概念性的指导:
- 视频处理:可以使用OpenCV读取视频帧,逐帧处理并显示。
- 摄像头支持:利用OpenCV的
cv2.VideoCapture(0)方法捕获摄像头图像,同样逐帧处理。
1. 数据预处理与增强
-
图像尺寸 (
imgsz):YOLO模型通常要求输入图像具有固定的尺寸。你可以根据硬件资源和任务需求调整这个值。较大的图像尺寸可以提供更丰富的细节信息,但也会增加计算成本。model.train(data='path/to/data.yaml', imgsz=640) # 调整图像尺寸为640x640 -
数据增强:通过数据增强技术(如翻转、旋转、裁剪等),可以增加训练集的多样性,从而提高模型的泛化能力。YOLOv5内置支持多种数据增强方法,你也可以自定义增强策略。
# 在data.yaml中配置数据增强选项 augment: True # 启用数据增强
2. 训练参数
-
批次大小 (
batch_size):决定了每次迭代中使用的样本数量。较大的批次大小有助于加速训练过程,但也需要更多的内存。可以根据GPU显存大小调整该参数。model.train(data='path/to/data.yaml', batch_size=16) -
学习率 (
lr0,lrf):初始学习率(lr0)和最终学习率(lrf)是影响训练效果的重要因素。一般情况下,较小的学习率有助于模型收敛,但可能会导致训练速度变慢。model.train(data='path/to/data.yaml', lr0=0.01, lrf=0.1) -
训练轮次 (
epochs):指定了模型训练的总次数。更多轮次可能带来更好的性能,但也增加了过拟合的风险。model.train(data='path/to/data.yaml', epochs=100)
3. 模型架构
-
选择不同的YOLO版本:YOLO有多个版本(如YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x),它们在精度和速度之间有不同的权衡。一般来说,较大的模型(如YOLOv5x)能提供更高的准确度,但计算成本也更高。
model = YOLO('yolov5x.pt') # 使用YOLOv5x模型 -
自定义网络结构:如果标准模型不能满足需求,可以通过修改模型架构来适应特定任务,例如添加或删除某些层。
4. 正则化与正负样本平衡
-
权重衰减 (
weight_decay):用于防止模型过拟合的一种正则化技术。model.train(data='path/to/data.yaml', weight_decay=0.0005) -
正负样本比例:在目标检测任务中,正负样本的比例对模型训练至关重要。可以通过调整
obj和cls损失函数中的权重来进行控制。
5. 验证与评估
-
验证集比例 (
val_split):指定训练集中用于验证的部分比例。合理的验证集可以帮助监控模型的泛化能力。model.train(data='path/to/data.yaml', val_split=0.1) # 10%的数据作为验证集 -
评估指标:除了默认的mAP外,还可以关注其他指标如精确率、召回率等,以便全面了解模型性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









