







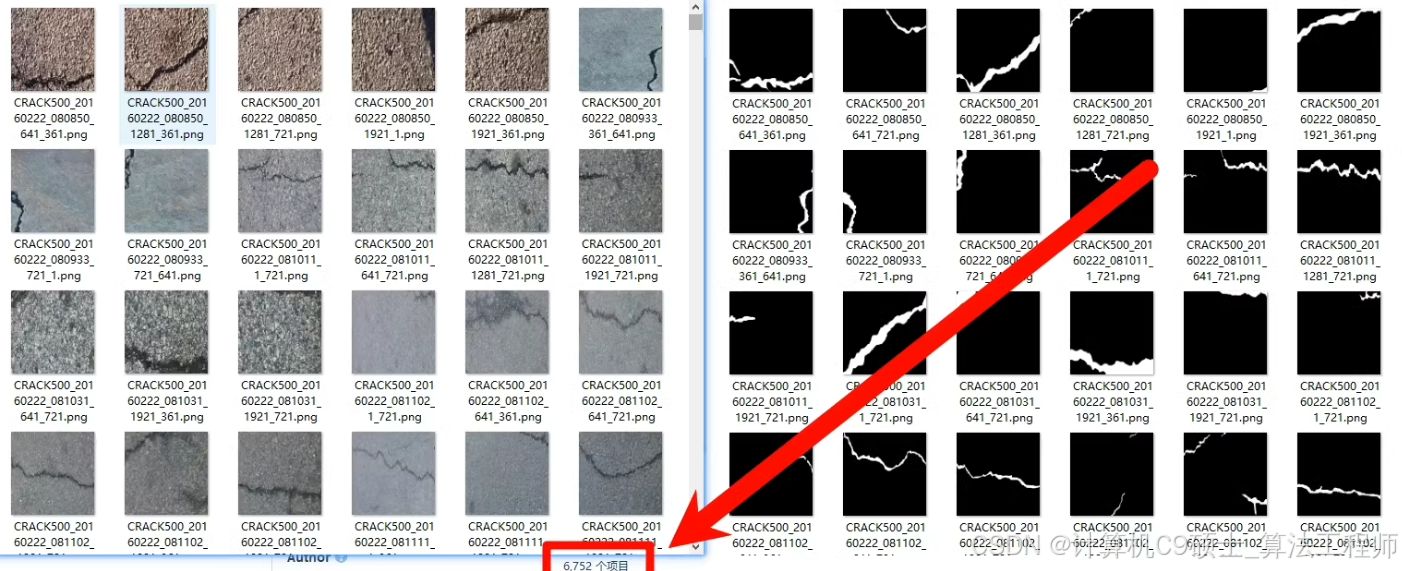
道路裂缝检测数据集
数据集概述
数据来源:该数据集由10个子数据集预处理和大小调整为400x400,具体子数据集包括:
Crack500
Deepcrack
Sdnet
Cracktree
Gaps
Volker
Rissbilder
Noncrack
Massimo
Ceramic
数据规模:共6000多张图像,每张图像都有对应的像素级标签。
图像格式:JPG
标签格式:二值标签,有两种格式:
0-255像素
0-1像素
用途:适用于UNet、UNet++、FCN、SegFormer、DeepLab等语义分割算法。
数据集结构
深色版本
road_crack_detection/
├── dataset/
│ ├── images/
│ │ └── *.jpg
│ ├── labels_0_255/
│ │ └── *.png
│ ├── labels_0_1/
│ │ └── *.png
├── models/
│ └── unet/
│ └── unetpp/
│ └── fcn/
│ └── segformer/
│ └── deeplab/
├── src/
│ ├── train.py
│ ├── predict.py
│ ├── utils.py
│ ├── dataset.py
├── weights/
│ └── best_model.pth
├── requirements.txt
└── README.md
- 安装依赖
首先,确保你已经安装了必要的库。创建一个requirements.txt文件,内容如下:
深色版本
torch
torchvision
numpy
pandas
matplotlib
tqdm
pyyaml
opencv-python
然后,使用以下命令安装依赖:
bash
深色版本
pip install -r requirements.txt
2. 数据集准备
确保你的数据集已经按照以下结构组织:
深色版本
dataset/
├── images/
│ └── *.jpg
├── labels_0_255/
│ └── *.png
├── labels_0_1/
│ └── *.png
每个文件夹中包含对应的图像文件和标签文件。确保所有图像文件都是.jpg格式,标签文件是PNG格式。
- 数据集类
创建一个数据集类,用于加载和预处理数据。
3.1 src/dataset.py
python
深色版本
import os
import torch
from torch.utils.data import Dataset
from torchvision import transforms
from PIL import Image
class RoadCrackDataset(Dataset):
def init(self, image_dir, label_dir, transform=None, label_type=‘0_1’):
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = transform
self.image_files = os.listdir(image_dir)
self.label_type = label_type
def __len__(self):
return len(self.image_files)
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.image_files[index])
label_path = os.path.join(self.label_dir, self.image_files[index].replace('.jpg', '.png'))
image = Image.open(img_path).convert("RGB")
label = Image.open(label_path).convert("L")
if self.label_type == '0_255':
label = np.array(label) // 255
else:
label = np.array(label)
if self.transform:
image = self.transform(image)
label = torch.from_numpy(label).long()
return image, label
def get_data_loaders(image_dir, label_dir, batch_size=16, num_workers=4, label_type=‘0_1’):
transform = transforms.Compose([
transforms.Resize((400, 400)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
dataset = RoadCrackDataset(image_dir, label_dir, transform=transform, label_type=label_type)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_loader, val_loader
- 模型定义
这里以UNet为例,定义模型并进行训练。
4.1 src/train.py
python
深色版本
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from src.dataset import get_data_loaders
import torch.nn as nn
import torch.nn.functional as F
from models.unet import UNet
def train_model(image_dir, label_dir, epochs=100, batch_size=16, learning_rate=1e-4, label_type=‘0_1’):
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
model = UNet(n_channels=3, n_classes=2)
model = model.to(device)
train_loader, val_loader = get_data_loaders(image_dir, label_dir, batch_size=batch_size, label_type=label_type)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
writer = SummaryWriter()
for epoch in range(epochs):
model.train()
running_loss = 0.0
for images, labels in tqdm(train_loader, desc=f"Epoch {epoch + 1}/{epochs}"):
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
writer.add_scalar('Training Loss', train_loss, epoch)
model.eval()
running_val_loss = 0.0
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_val_loss += loss.item()
val_loss = running_val_loss / len(val_loader)
writer.add_scalar('Validation Loss', val_loss, epoch)
print(f"Epoch {epoch + 1}/{epochs}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}")
torch.save(model.state_dict(), "weights/best_model.pth")
writer.close()
if name == “main”:
image_dir = “dataset/images”
label_dir = “dataset/labels_0_1”
train_model(image_dir, label_dir)
5. 模型评估
训练完成后,可以通过验证集和测试集来评估模型的性能。示例如下:
5.1 src/predict.py
python
深色版本
import torch
import matplotlib.pyplot as plt
from models.unet import UNet
from src.dataset import get_data_loaders
import numpy as np
def predict_and_plot(image_dir, label_dir, model_path, num_samples=5, label_type=‘0_1’):
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
model = UNet(n_channels=3, n_classes=2)
model.load_state_dict(torch.load(model_path))
model = model.to(device)
model.eval()
_, val_loader = get_data_loaders(image_dir, label_dir, label_type=label_type)
fig, axes = plt.subplots(num_samples, 3, figsize=(15, 5 * num_samples))
with torch.no_grad():
for i, (images, labels) in enumerate(val_loader):
if i >= num_samples:
break
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
predictions = torch.argmax(outputs, dim=1).cpu().numpy()
labels = labels.cpu().numpy()
images = images.cpu().numpy().transpose((0, 2, 3, 1))
for j in range(len(images)):
ax = axes[j] if num_samples > 1 else axes
ax[0].imshow(images[j])
ax[0].set_title("Input Image")
ax[0].axis('off')
ax[1].imshow(labels[j], cmap='gray')
ax[1].set_title("True Label")
ax[1].axis('off')
ax[2].imshow(predictions[j], cmap='gray')
ax[2].set_title("Predicted Label")
ax[2].axis('off')
plt.tight_layout()
plt.show()
if name == “main”:
image_dir = “dataset/images”
label_dir = “dataset/labels_0_1”
model_path = “weights/best_model.pth”
predict_and_plot(image_dir, label_dir, model_path)
6. 模型定义(UNet)
6.1 models/unet.py
python
深色版本
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
def init(self, in_channels, out_channels):
super(DoubleConv, self).init()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def init(self, n_channels, n_classes):
super(UNet, self).init()
self.n_channels = n_channels
self.n_classes = n_classes
self.inc = DoubleConv(n_channels, 64)
self.down1 = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(64, 128)
)
self.down2 = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(128, 256)
)
self.down3 = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(256, 512)
)
self.down4 = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(512, 1024)
)
self.up1 = nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2)
self.conv1 = DoubleConv(1024, 512)
self.up2 = nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2)
self.conv2 = DoubleConv(512, 256)
self.up3 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.conv3 = DoubleConv(256, 128)
self.up4 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.conv4 = DoubleConv(128, 64)
self.outc = nn.Conv2d(64, n_classes, kernel_size=1)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5)
x = torch.cat([x, x4], dim=1)
x = self.conv1(x)
x = self.up2(x)
x = torch.cat([x, x3], dim=1)
x = self.conv2(x)
x = self.up3(x)
x = torch.cat([x, x2], dim=1)
x = self.conv3(x)
x = self.up4(x)
x = torch.cat([x, x1], dim=1)
x = self.conv4(x)
logits = self.outc(x)
return logits
- 运行项目
确保你的数据集已经放在相应的文件夹中。
在项目根目录下运行以下命令启动训练:
bash
深色版本
python src/train.py
训练完成后,运行以下命令进行评估和可视化:
bash
深色版本
python src/predict.py - 功能说明
数据集类:RoadCrackDataset类用于加载和预处理数据。
数据加载器:get_data_loaders函数用于创建训练和验证数据加载器。
训练模型:train.py脚本用于训练UNet模型,使用交叉熵损失函数和Adam优化器。
评估模型:predict.py脚本用于评估模型性能,并可视化输入图像、真实标签和预测结果。
模型定义:unet.py文件定义了UNet模型。 - 详细注释
dataset.py
数据集类:定义了一个RoadCrackDataset类,用于加载和预处理数据。
数据加载器:定义了一个get_data_loaders函数,用于创建训练和验证数据加载器。
train.py
训练函数:定义了一个train_model函数,用于训练UNet模型。
训练过程:在每个epoch中,模型在训练集上进行前向传播和反向传播,并在验证集上进行评估。
predict.py
预测和可视化:定义了一个predict_and_plot函数,用于在验证集上进行预测,并可视化输入图像、真实标签和预测结果。
unet.py
UNet模型:定义了UNet模型的结构,包括编码器和解码器部分。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









