






开题
在DeepSeek以及Chatgpt的帮助下,我成功的在自己的电脑上部署了一个AI大模型,虽然我部署的AI无法进行很精细的操作,并且没有界面,没有记忆功能,但是我还是想分享一下我的部署步骤。
在该文章中,我可以确保你在和我电脑配置系统相似的情况下完成deepseek-v2-lite-16b-chat的基础部署,但是对于其他的AI的模型部署,我没法保证部署,只能希望你能通过该篇文章获得帮助。
如果在你配置大模型的过程中遇到了难以解决的问题,请转到文章中*“困难点以及关于一些疑难杂症的可能解决方案”*这一章节,该章节可以为你提供一些解决问题的方法,可能对你解决问题有利。
电脑配置以及模型的选择
本人电脑配置:
windows11
4070显卡,8G显存
32G运行内存
对于大模型的选择,其实可以完全不用自己选择,将你的电脑配置告诉DeepSeek,他就可以通过推理告诉你你的电脑适配的最佳大模型。
就比如我来说,最适配我的电脑的模型就是:deepseek-v2-lite-16b-chat。
同时我部署的本地AI模型也是该模型。
准备工作
我们并非使用软件部署模型,所以很多依赖项的安装以及环境的配置都需要我们自己准备。
电脑文件夹的准备
是的,关于电脑文件夹的准备,我感觉是需要或者说必要的,因为我觉得我们不需要把所有的东西都塞给C盘,并且在后期调用大模型的程序中我们同样也需要文件路径,提前准备好会在后面顺手的多。
首先:
在一个非C盘的盘根目录中创建一个文件夹,我的命名是:LocalAI
然后:
在LocalAI这个文件夹中创建三个文件夹,我分别的命名是:AIModel,code,ToolApp
AIModel:用于存放大模型的模型文件
code:用于存放调用以及使用大模型的代码文件
ToolApp:用于存放部署模型所使用的软件
注意:为了方便后续的进行,我们的文件名中尽量不要出现空格,否则在调用大模型时会出现很多莫名其妙的错误
CUDA准备
CUDA的下载以及环境的配置
在https://developer.nvidia.com/cuda-11-8-0-download-archive该网址中下载CUDA,安装时没有特别要求,但是记得安装在我们的ToolApp中。
现在要求我们将他配置到环境中,我们右击我的电脑——属性——高级系统设置——环境变量——Path——编辑,在编辑中我们将CUDA文件夹中的lip以及libnvvp两个文件夹的绝对路径添加上就好了。如果还是不会配置环境变量就自行去网络搜索,只需要记住我们要配置的只有lip和libnvvp就好了。
CUDA是否成功安装以及配置到环境的验证
在CMD中输入以下指令并运行:
nvcc --version
如果看到 release 11.8 说明安装成功,并且成功配置到环境。
python以及某些依赖项的准备
python的准备
这里我们直接下载python3.10,为何选择这个版本,我会在后续做出解答,我想对于python的下载大家都不陌生,只有一点需要大家注意,就是下载时勾选Add to PATH。这一步的目的是将python添加到电脑的环境变量中,这样我们的电脑在执行某些程序时如果需要调用python就可以直接调用而不会找不到了。
python是否成功安装以及配置到环境的验证
在CMD中输入以下指令:
python --version
按照我们的教程,理应输出:Python 3.10.XX
pyTorch准备
下载完python后我们便可以直接使用pip指令来安装AI本地部署的依赖项了,直接打开CMD,输入以下指令即可。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
这条指令是下载pytorch以及一些pytorch的依赖项。
pyTorch是否成功安装以及是否支持GPU加速的验证
在python中输入以下指令:
import torch
print(torch.cuda.is_available())
如果输出 True,则 GPU 可用,并且侧面显示已经成功安装。
其他必须依赖项的安装
在CMD中执行以下指令:
pip install transformers==4.38.2 bitsandbytes==0.43.0 sentencepiece==0.2.0 safetensors==0.4.2 install accelerate==0.27.2
这个指令会将指令中的依赖项全部下载
其他必须依赖项的安装的验证
transformers bitsandbytes accelerate,这三个依赖项在我们的配置中是必须的,所以我们需要验证他的安装是否成功,在CMD中输入以下指令:
pip show transformers bitsandbytes accelerate
按照预期,他应该会输出以下内容:
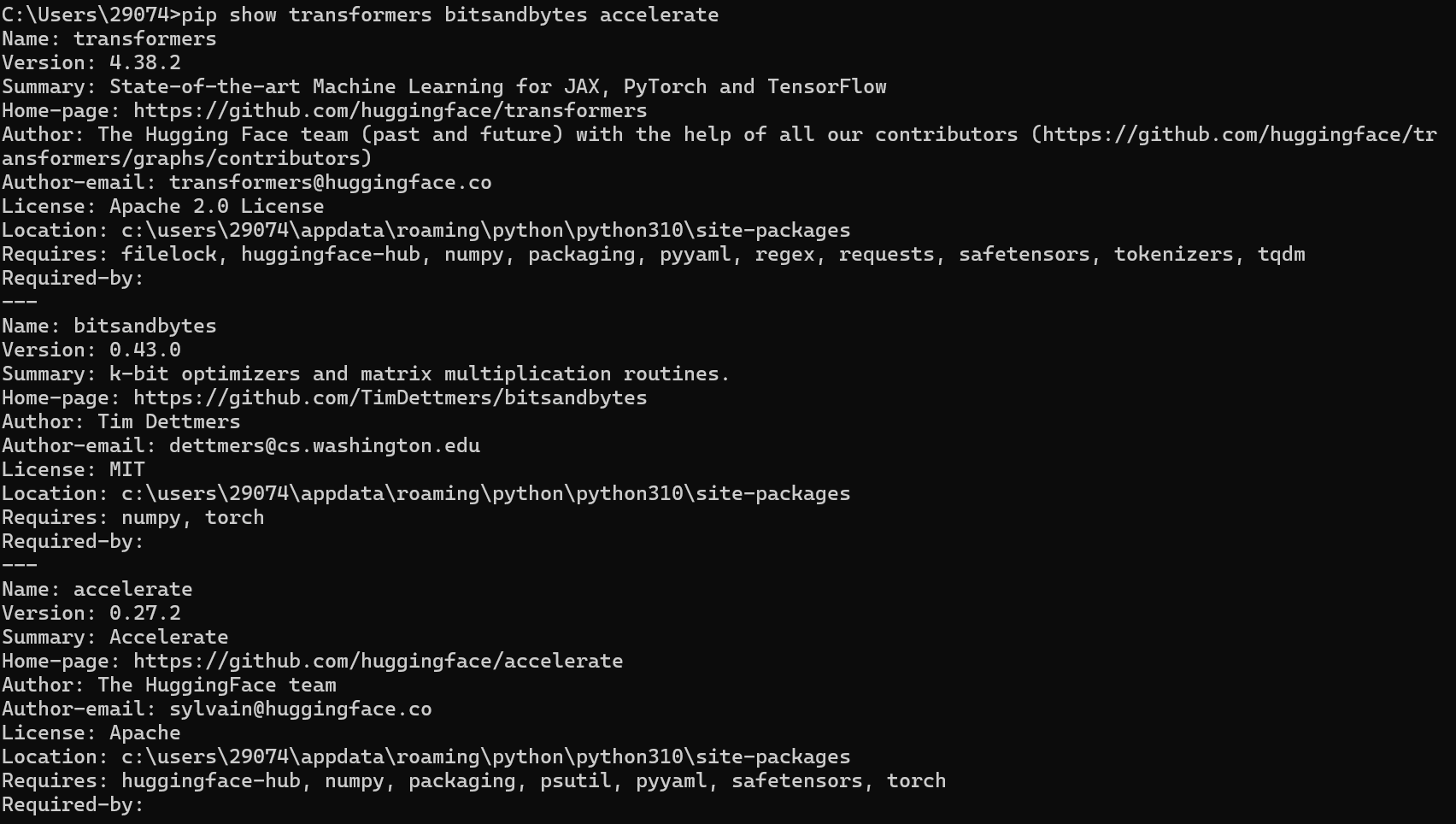
请审查版本是否一样。
模型的准备
便捷且快速的方法
这里直接给出我的下载方式:
1.找到我们创建的LocalAI文件夹,鼠标右键点击在终端中打开
2.在该终端中输入以下指令:
pip install modelscope
modelscope download --model deepseek-ai/DeepSeek-V2-Lite-Chat --local_dir ./models
第一行指令是用于安装ModelScope 库,第二句指令是用ModelScope 库下载大模型,有兴趣的可以自行了解ModelScope 库。
同理,你如果想下载其他模型,在该代码中修改相应的大模型名字就好了。
其他方法
因为ModelScope是国内的一个大模型平台,所以下载方便,但是不排除出现问题或者模型不存在,这时候我们就要寻找其他方法下载了:
1.通过Hugging Face下载:
访问https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite-Chat/tree/main该界面(国外网站)
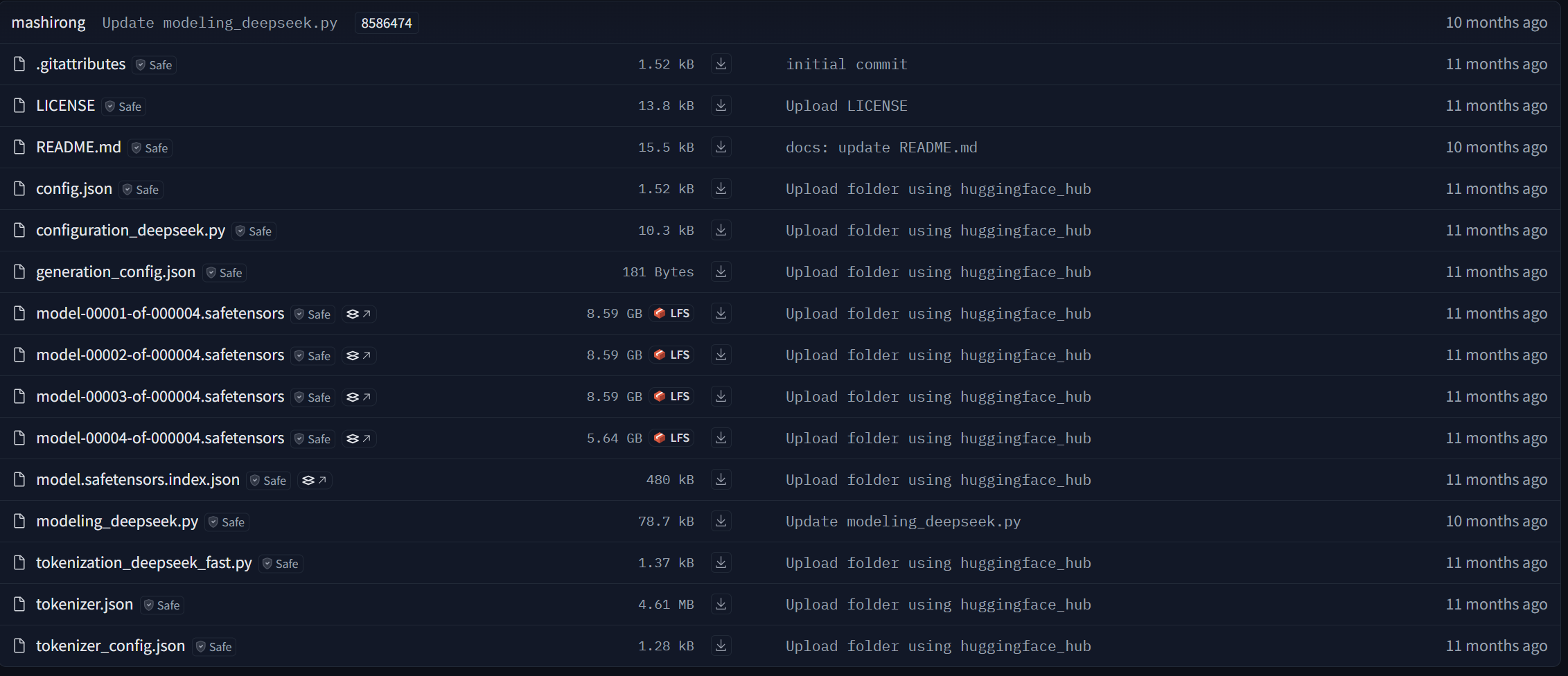
你会看到上面图片的界面,然后将图片中的所有文件全部下载下来到目标文件夹就好了。
如果想要下载其他模型,也可以在Hugging Face中搜索并下载。
2.通过AI快站镜像下载:
如果不方便访问国外网站,可以去该网站https://aifasthub.com/models/deepseek-ai,搜索相应的大模型名字然后下载到相应的模型。
模型是否成功下载的验证
所想在本地部署大模型,所下载的大模型文件必须要有:
|下面是一个简明的表格,列出了在电脑上部署本地大模型时,模型文件目录中必须包含的关键文件及其功能说明:
| 文件类别 | 示例文件名 | 功能说明 |
|---|---|---|
| 配置文件 | config.json | 定义模型架构、层数、隐藏层维度、注意力头数等超参数 |
| 模型权重文件 | pytorch_model.bin 或 model.safetensors(可能分片存储)及索引文件(如 model.safetensors.index.json) | 存储预训练好的模型权重,用于模型参数初始化 |
| 分词器文件 | tokenizer.json、tokenizer.model、vocab.json、tokenizer_config.json、special_tokens_map.json | 定义分词器配置、词汇表和特殊 token 映射,保证文本预处理正确 |
| 自定义代码 | modeling_.py、configuration_.py、tokenization_*.py | 模型自定义代码文件(若有),实现特定模型结构或分词逻辑,需使用 trust_remote_code 加载 |
| 确保这些文件齐全后,才能正确加载模型并在本地部署后进行推理或微调。 | |
|---|---|
| 注意:大模型文件中一定要有配置文件,模型权重文件,分词器文件这三种文件,但是每种文件的文件格式名不同模型未必相同,就比如我部署的模型模型权重文件是model.safetensors,其他模型可能不是这种文件,可以通过去Hugging Face上搜索该模型来了解该模型所含有的文件 |
困难点以及关于一些疑难杂症的可能解决方案
事先的一些心得和抱歉
现在我们已经完成了准备工作,其实在完成这些内容时,如果你安装的是和我相同的版本,那么你已经完成了本地部署,只需要代码给你临门一脚完成对模型的调用,但是问题来了,如果你和我部署的不是同意一个模型,该咋办呢?
很遗憾,我在这篇文章中只能告诉你,你只能碰运气,运气好的话,你所需要的模型跟我的模型所需要的环境一样,可以运行,运气不好的话你只能自行摸索了。这下你可以知道为何只有“模型的准备”这一节中我告诉了你该如何下载别的模型,而在其他模块,章节中没有告诉你如何应对其他的模型。
很抱歉,我还没有完全搞明白该如何普适性的配置本地AI,我目前也在学习,我只是将我的心得以及一些方法告诉你,希望可以减少一些你的麻烦。
我为何要在文章的中间也就是临门一脚代码的前面写这个,是因为到了代码,也就是模型的调用阶段,我的这篇文章的普适性会更低,所以我要事先告诉你,到了代码出问题的可能性会更大,但是到了代码阶段,基本就快结束了,需要你坚持下去。
对一些疑难杂症的可能解决方案
经过我的心得,我现在要告诉你该如何解决你遇到的问题,首先我总结了以下我遇到的最多的问题:1.模型的下载 2.模型环境的下载(也就是依赖项安装)3.该如何调用模型(也就是如何写代码),让下面我一一给出可能的解决方案:
1.模型的下载
对于模型的下载我想我所提供的方法已经可以解决绝大部分问题,但是有一项需要你切记,相同的模型有的时候会具有不同的名字,所以在下载模型时,如果显示不存在,记得去问一问DeepSeek或者其他可靠AI,该模型是否有其他的名字,在询问AI该如何下载大模型时,如果AI给你提供的下载方式中下载的模型名字和你所需要的模型名字不一样,你也要引起注意,可能是相同模型的不同姓名。
同时,我在下载完成模型时,我们通常要验证模型是否完整下载,你可以通过对我提供的表格来验证,也可以去该模型的发布官网去查询,当然也可以直接询问AI你所下载的大模型所包含的文件应该有哪些。
但是请注意,当你向DeepSeek等AI询问你问题的解决方法时,经常会出现该AI过拟合的状况,他会经过推理给你一个看起来合理但是其实说不通的一个解决方案,所以在你多次使用该AI提供的方法也无法解决该问题时请去浏览器寻找该问题答案或者询问其他AI例如chatGPT等AI来解决问题。
2.模型环境的下载(也就是依赖项安装)
出现这个问题,一般原因是1.依赖项的缺失 2.依赖项的版本不匹配
为了解决第一个问题,我在每个准备方法的后面都提供了验证是否成功安装的方法,如果经过那些方法没有出现应该出现的一些界面,例如版本号之类的,你就需要去重新安装,如果成功的出现了版本号但是还是提示依赖项有问题,那么大概问题出现在第二个上。
如果你的各种依赖项之间的版本不匹配,那么就会出现第二个问题,这时候你就需要去搜索你各种依赖项所需要对应的版本,我用python1.10的原因就是他所支持的依赖项版本比较多。
不知道依赖项版本之间的对应关系,直接浏览器搜索即可。
3.该如何调用模型(也就是如何写代码)
我们需要代码才能调用AI,我所提供的代码只能在你完全跟着我做,所下载的依赖项和AI完全一样时才能正确执行。因此如何解决代码问题就需要我们活用AI。
我们可以直接告诉AI我们电脑上配置的依赖项和大模型位置以及大模型名字,他就可以写出一份基础的代码,但是代码经常会出问题,就比如windows系统不支持Flash Attention,我们需要跳过对该依赖项的检查,当我们告诉DeepSeek我们的需求时,DeepSeep无法解决该问题,但是告诉chatGPT,ChatGPT解决了。但是ChatGPT又无法生成模型调用代码,只能用DeepSeek生成。
所以,想生成一份能正常运行的代码很麻烦,我能提供的帮助也很少,只有一个,那就是活用AI。
模型的调用(代码的书写)
代码的书写
代码我还没有完全琢磨清楚,我只能简单的做一些讲解,如果你所配置的模型以及依赖项和我的不同,可能需要你自行摸索。
在我们的code文件夹中创建一个python文件,并将以下代码输入:
import os
import torch
import sys
import types
import importlib.util
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# --------------------- 配置项(根据硬件调整) ---------------------
MODEL_PATH = r"E:\LocalAI\AIModel\DeepSeek\DeepSeekV2LiteChat" # 模型路径
USE_4BIT = True # 启用4-bit量化(显存需求降至约10GB)
USE_8BIT = False # 8-bit量化(显存需求约20GB)
MAX_NEW_TOKENS = 200 # 生成文本最大长度(降低内存压力)
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# --------------------- 量化配置(4-bit/8-bit) ---------------------
quantization_config = None
if USE_4BIT or USE_8BIT:
quantization_config = BitsAndBytesConfig(
load_in_4bit=USE_4BIT,
load_in_8bit=USE_8BIT,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4", # 4-bit量化类型
bnb_8bit_quant_type="nf8" if USE_8BIT else None
)
# --------------------- 加载模型(跳过Flash Attention) ---------------------
if sys.platform == "win32":
if "flash_attn" not in sys.modules:
# 创建一个 dummy 的 module spec
dummy_spec = importlib.util.spec_from_loader("flash_attn", loader=None)
dummy_module = types.ModuleType("flash_attn")
dummy_module.__spec__ = dummy_spec
# 根据模型代码中可能调用的函数名称添加 dummy 实现(仅返回 None)
dummy_module.flash_attn_unpadded = lambda *args, **kwargs: None
dummy_module.flash_attn_varlen_qkvpacked_func = lambda *args, **kwargs: None
sys.modules["flash_attn"] = dummy_module
# --------------------- 加载分词器 ---------------------
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
low_cpu_mem_usage=True,
padding_side="left", # 左对齐避免生成错位
use_fast=True # 强制使用快速分词器
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # 确保有pad token
# --------------------- 加载模型 ---------------------
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
low_cpu_mem_usage=True,
quantization_config=quantization_config,
trust_remote_code=True
)
# --------------------- 显存监控函数 ---------------------
def print_gpu_memory():
if DEVICE == "cuda":
allocated = torch.cuda.memory_allocated() / 1024**3
reserved = torch.cuda.memory_reserved() / 1024**3
print(f"[显存] 已分配: {allocated:.2f} GB | 保留: {reserved:.2f} GB")
else:
print("当前使用CPU运行")
# --------------------- 轻量生成函数 ---------------------
def light_generate(prompt: str):
print("\n" + "="*30 + " 生成开始 " + "="*30)
# 精简输入处理
inputs = tokenizer(
f"<|startoftext|>User: {prompt}\nAssistant:",
return_tensors="pt",
max_length=512, # 限制输入长度
truncation=True
).to(DEVICE)
# 低资源生成参数
outputs = model.generate(
inputs.input_ids,
max_new_tokens=MAX_NEW_TOKENS,
do_sample=True,
temperature=0.3, # 降低随机性
top_p=0.9,
repetition_penalty=1.1, # 减少重复
pad_token_id=tokenizer.eos_token_id
)
# 清理显存
torch.cuda.empty_cache()
# 解码结果
generated = tokenizer.decode(
outputs[0][inputs.input_ids.shape[1]:],
skip_special_tokens=True
)
return generated.strip()
# --------------------- 测试运行 ---------------------
if __name__ == "__main__":
print_gpu_memory() # 初始显存状态
# 测试样例(短文本验证基础功能)
test_prompts = [
"用比较霸气的话评价一下“富豪榜前六”这个微信群名"
]
for prompt in test_prompts:
print(f"\n[输入] {prompt}")
try:
reply = light_generate(prompt)
print(f"[输出] {reply}")
except RuntimeError as e:
if "CUDA out of memory" in str(e):
print("[错误] 显存不足!请尝试减小 MAX_NEW_TOKENS 或启用4-bit量化")
else:
print(f"[错误] {str(e)}")
print_gpu_memory() # 每次生成后显存状态
在该代码中只有一点需要你注意:
MODEL_PATH = r"E:\LocalAI\AIModel\DeepSeek\DeepSeekV2LiteChat"
请记住,在该句代码中的文件夹位置是你的电脑上的大模型文件的位置,前面的r不要省略,否则使用该代码时会去Hugging Face上查询模型而不是在你的本地文件中从查询模型,会报错。
test_prompts = [
"用比较霸气的话评价一下“富豪榜前六”这个微信群名"
]
这句代码是用于你对AI提问的。
代码使用
这是最后的一步,打开你的code文件夹,右击打开在终端中打开,然后输入:
python xxx.py
其中,xxx是你的python文件名字。输入之后等待两分钟左右你就可以看到回复了。
结尾
到这里,你就已经完成了本地AI的部署,但是很多地方还想当不严密,需要你继续去研究,感谢您的观看。

















 1424
1424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









