






2024深度学习发论文&模型涨点之——GNN+强化学习
图神经网络(GNN)和强化学习(RL)是机器学习领域中的两个重要研究方向。GNN擅长处理图结构数据,而RL在动态环境中进行序列决策表现出色。将两者结合,可以开发出同时学习图结构表示和做出最优决策的智能模型。
这种结合在多个领域展现出广泛的应用潜力,包括金融欺诈检测、集成工艺规划与调度、社交网络分析、推荐系统、生物信息学、交通路由、制造业调度、自动驾驶汽车控制、无线网络资源分配以及生命科学等。这种结合不仅提高了决策的准确性和效率,还优化了复杂系统的管理,并在解决实际问题中取得了显著成效。
我整理了一些GNN+强化学习【论文+代码】合集,需要的同学公人人人号【AI创新工场】自取。
论文精选
论文1:
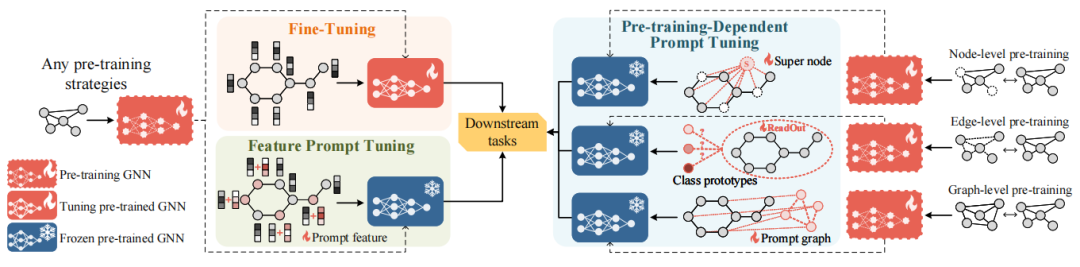
RELIEF: Reinforcement Learning Empowered Graph Feature Prompt Tuning
RELIEF:强化学习赋能的图特征提示调整
方法
强化学习优化:利用强化学习来优化图特征提示的插入过程,通过策略梯度方法优化提示插入策略。
马尔可夫决策过程(MDP):将提示纳入过程建模为MDP,处理离散和连续动作。
混合动作空间:使用混合动作空间的强化学习算法来处理离散和连续动作。
图神经网络(GNN)模型:在GNN模型中增强下游任务的性能。
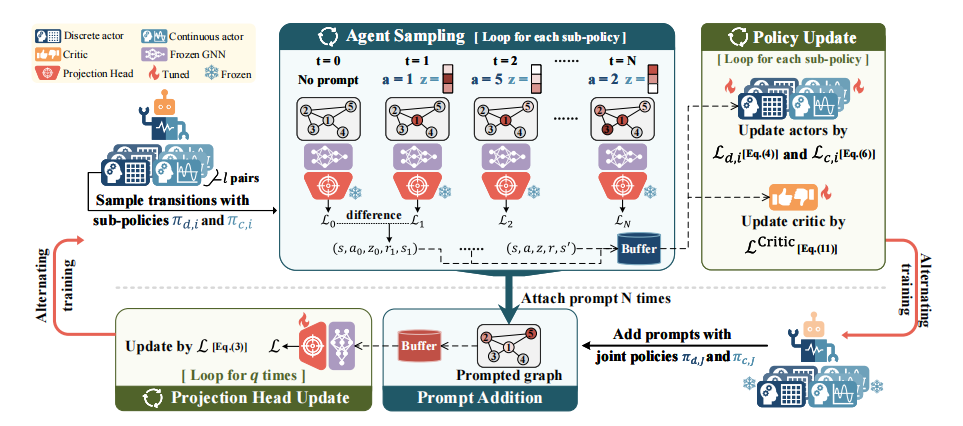
创新点
首次应用强化学习:首次将强化学习应用于图特征提示调整。
策略梯度方法:通过策略梯度方法优化提示插入策略。
性能提升:在多个图和节点级任务中验证了方法的有效性,显示出比微调和其他基于提示的方法更好的分类性能和数据效率,平均提升1.64%。
论文2:
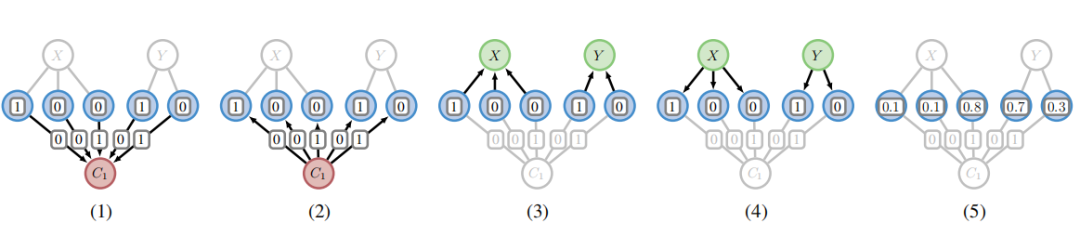
One Model, Any CSP: Graph Neural Networks as Fast Global Search Heuristics for Constraint Satisfaction
一个模型,任何CSP:图神经网络作为快速全局搜索启发式算法用于约束满足
方法
通用图神经网络架构:提出了一种通用的图神经网络架构,可以作为端到端的搜索启发式算法来训练,以解决任何约束满足问题(CSP)。
无监督策略梯度下降:通过无监督的策略梯度下降训练,生成特定问题的启发式算法。
新颖的图表示:利用新颖的图表示来处理所有可能的CSP实例。
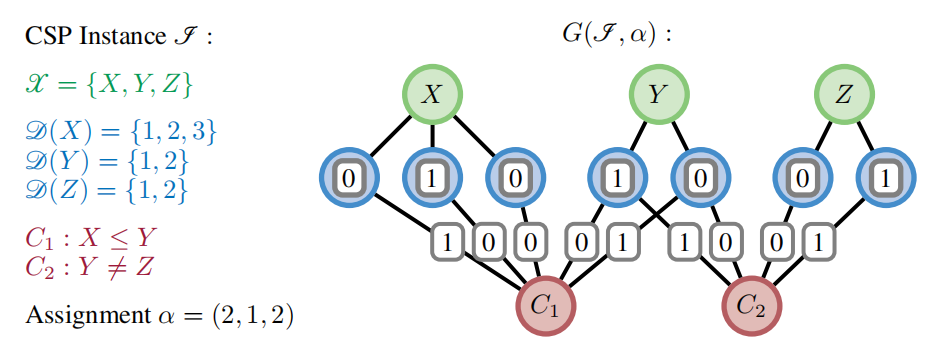
创新点
新的图表示方法:提出了一种新的图表示方法,适用于所有CSP实例,无需特定问题的图简化。
全局搜索动作空间:通过全局搜索动作空间和策略梯度方法处理指数级动作空间,显著加快了搜索速度。
性能提升:在多个重要CSP问题上验证了方法的有效性,性能优于先前的神经组合优化方法,平均提升显著。
论文3:
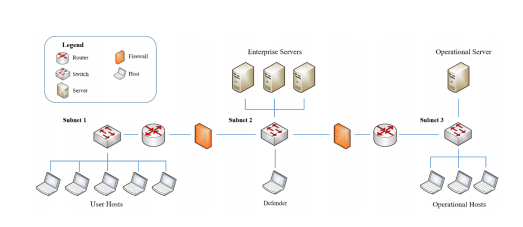
Structural Generalization in Autonomous Cyber Incident Response with Message-Passing Neural Networks and Reinforcement Learning
基于消息传递神经网络和强化学习的自主网络事件响应中的结构泛化
方法
关系学习方法:提出了一种基于关系学习的方法,假设对象间的关系在不同问题实例中保持一致。
消息传递神经网络(MPNN):使用MPNN对计算机网络状态进行编码。
强化学习优化:通过强化学习端到端优化MPNN和代理策略。
零样本泛化:使代理能够在网络结构变化时实现零样本泛化。
创新点
关系图表示:首次将关系图用于表示网络状态,通过MPNN进行编码,以处理网络结构的动态变化。
强化学习策略优化:采用强化学习方法优化代理策略,使其能够在不同网络变体上进行泛化,而无需额外训练。
性能提升:在Cyber Autonomy Gym for Experimentation (CAGE 2)环境中验证了方法的有效性,展示了代理在未训练过的网络变体上的性能提升。
论文4:
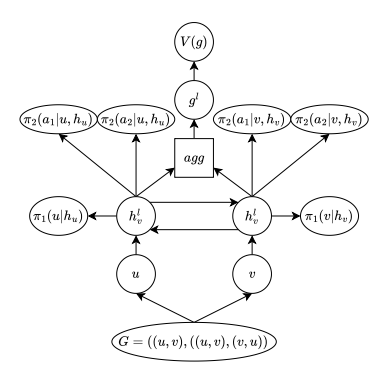
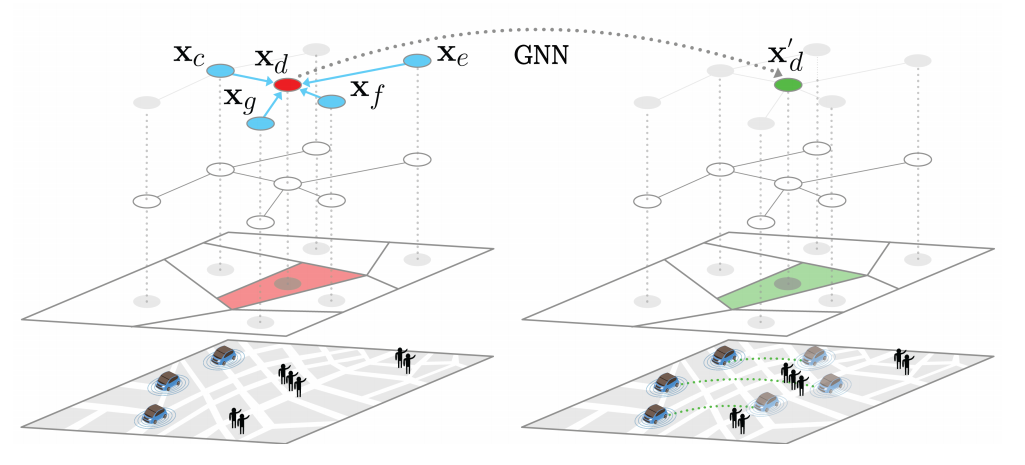
Graph Neural Network Reinforcement Learning for Autonomous Mobility-on-Demand Systems
用于自主按需出行系统的图神经网络强化学习
方法
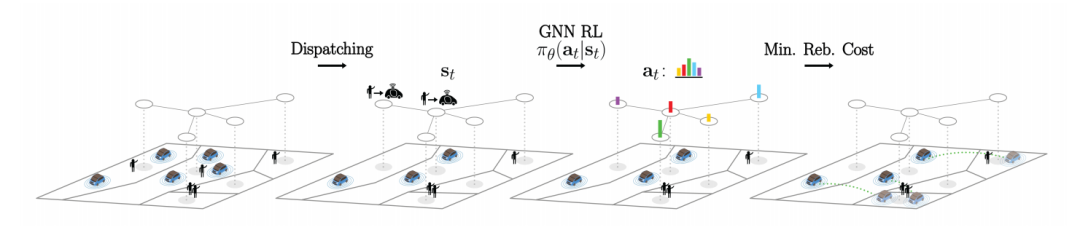
图神经网络框架:提出了一种基于图神经网络的深度强化学习框架,用于控制自主按需出行(AMoD)系统的再平衡。
节点级再平衡策略:通过学习节点级的再平衡策略来提高策略的可转移性、泛化性和可扩展性。
Actor-Critic算法:采用Actor-Critic算法,其中策略和价值函数估计器都使用图卷积来定义。
零样本转移能力:展示了策略在不同城市和不同服务区域的零样本转移能力。
创新点
新颖神经网络架构:定义了一种新颖的神经网络架构,利用图神经网络的关系表示能力来学习更有效、可扩展和泛化的策略。
性能提升:在成都和纽约的真实城市数据上验证了框架的性能,展示了策略的零样本转移能力,与控制方法相比,性能提升接近最优。
计算效率:与基于控制的方法相比,学习方法在计算复杂度上具有线性关系,显著提高了计算效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









