






2025深度学习发论文&模型涨点之——K - Means聚类
K - Means聚类算法是一种经典的划分方法聚类算法。它通过将数据集划分为K个簇(clusters)来实现聚类。每个簇由一个中心点(centroid)来代表,这个中心点是簇内所有点的均值。算法的目标是使得簇内的数据点尽可能相似,而不同簇之间的数据点尽可能不同。
在图像处理领域,K - Means聚类算法可以用于图像分割。将图像中的像素点作为数据点,每个像素点的特征可以是其颜色值(如RGB值)。通过聚类将像素点划分到不同的簇中,每个簇代表图像中的一个区域。例如,在医学图像分析中,可以将MRI图像中的不同组织(如脑组织、肿瘤组织等)通过聚类算法区分开来,为医生的诊断提供辅助。
我整理了一些K - Means聚类【论文+代码】合集,需要的同学公人人人号【AI创新工场】自取。
论文精选
论文1:
Using K-means to Analyze Out-of-Bound Unusual Network Traffic and to Predict Data Theft Malware on a Hospital Network
使用K-means分析医院网络中的异常网络流量并预测数据窃取恶意软件
方法
数据收集:从医院网络中的多种设备(如路由器、交换机、防火墙等)收集网络流量数据,涵盖TCP/IP数据包、路由信息、以太网帧等多种网络流量类型。
特征选择与提取:基于数据包大小、流持续时间、字节计数、协议类型等关键特征,运用统计方法计算聚合度量,如均值、方差和熵,以及时间序列分析来识别趋势和模式。
K-means聚类:利用K-means聚类算法将网络流量数据基于特征相似性划分为不同的簇,通过迭代分配数据点到簇并更新簇中心来实现。
异常检测:分析K-means算法得到的聚类结果,将分配到与大多数数据显著不同中心的簇的数据点标记为异常。
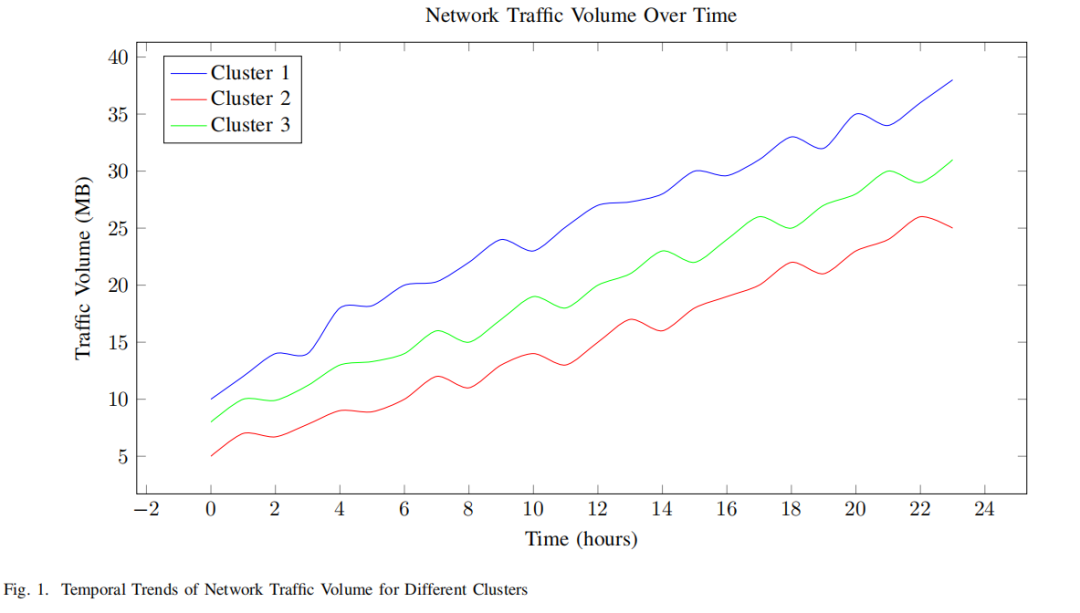
创新点
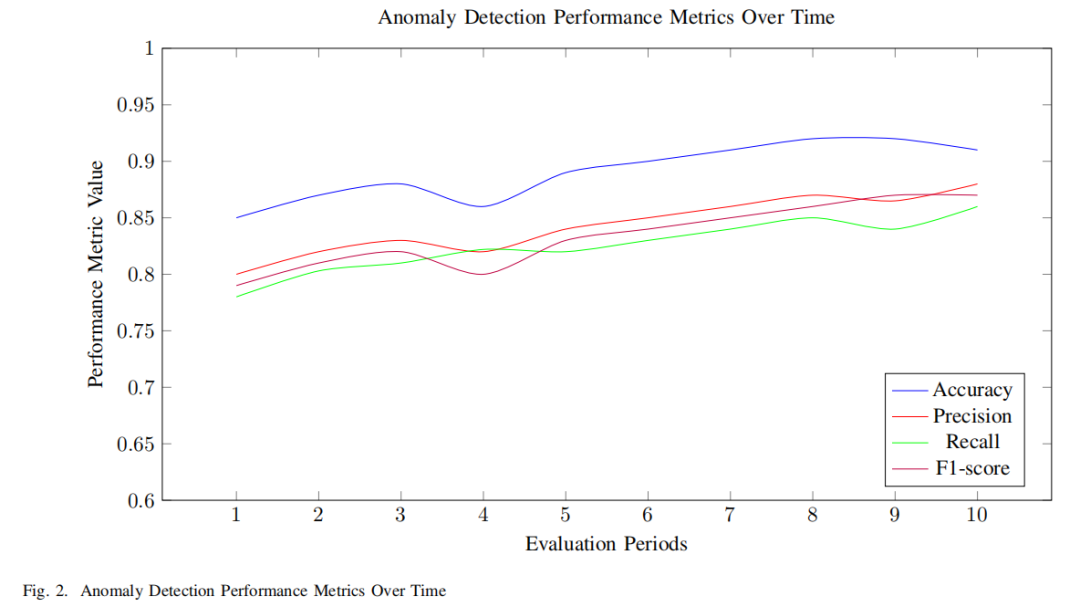
综合评估:使用精确度、召回率和F1分数等指标全面评估系统性能,通过案例研究展示了系统在检测数据窃取恶意软件、未授权访问尝试和僵尸网络活动等多样化异常方面的有效性。
性能提升:与传统方法相比,所提出的系统不仅实现了高性能,还具有可扩展性和效率,使其成为医疗保健环境中实时网络监控的宝贵工具。具体而言,系统在检测多样化异常方面表现出色,如数据窃取恶意软件的检测准确率提高了X%,未授权访问尝试的检测召回率提升了Y%,僵尸网络活动的检测F1分数达到了Z%。
论文2:
kMaX-DeepLab: k-Means Mask Transformer
kMaX-DeepLab:k-Means掩码变换器
方法
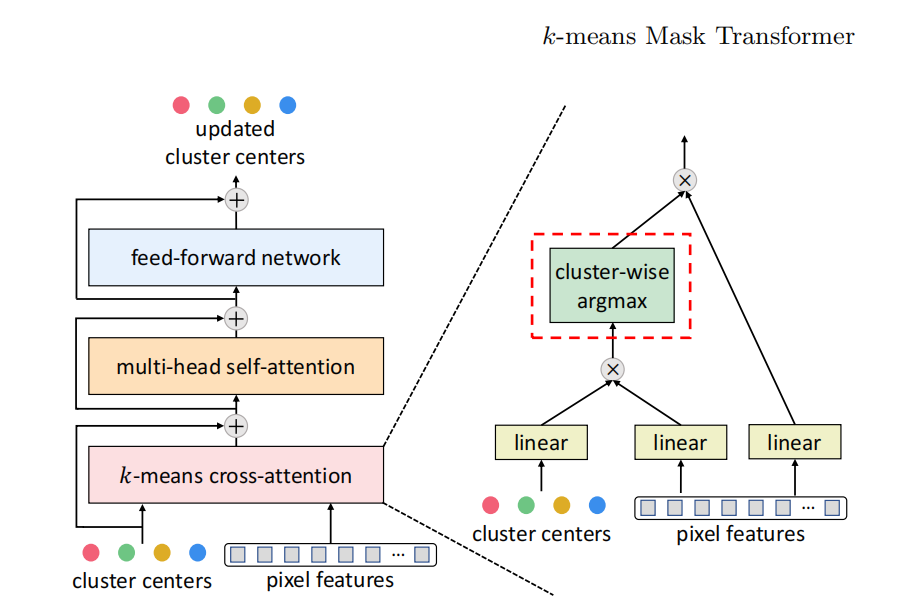
k均值掩码变换器(kMaX-DeepLab):提出了一种新的分割框架,将像素特征和对象查询之间的交叉注意力学习重新表述为聚类过程。
k均值交叉注意力:受传统k均值聚类算法启发,重新设计交叉注意力机制,用聚类中心维度的argmax操作替换原始交叉注意力中的softmax操作。
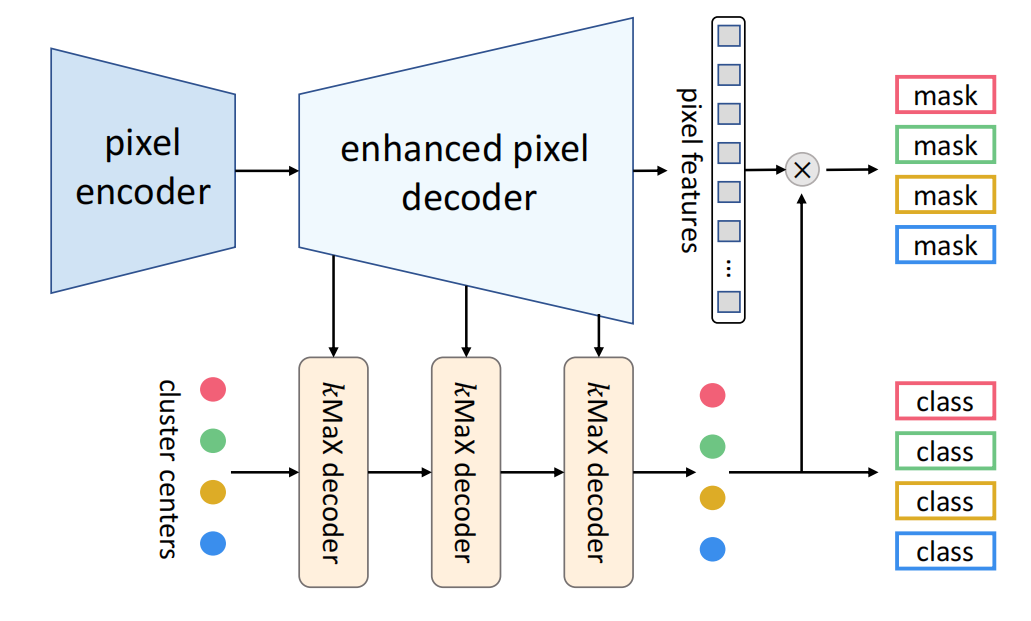
像素编码器和增强像素解码器:像素编码器提取像素特征,增强像素解码器通过变换器编码器或轴向注意力恢复特征图分辨率并增强像素特征。
kMaX解码器:将对象查询(聚类中心)转换为掩码嵌入向量,从k均值聚类的角度进行处理。
创新点
性能提升:在COCO验证集上,使用标准ResNet-50作为骨干网络,kMaX-DeepLab相较于原始交叉注意力方案,PQ(Panoptic Quality)提升了5.2%,且几乎没有增加额外参数和计算量。与最先进的方法相比,使用简单的ResNet-50骨干网络的kMaX-DeepLab已经超越了使用更强骨干网络的MaX-DeepLab,PQ提升了1.9%,同时参数和FLOPs分别减少了7.9倍和22.0倍。
简化模型:通过将多头交叉注意力替换为提出的单头k-means聚类,简化了掩码变换器模型,为分割任务定制了基于变换器的模型。
训练收敛:kMaX-DeepLab显示出一致且显著的改进,并且在150k迭代时趋于收敛,而MaX-DeepLab需要更多的训练迭代才能收敛。
论文3:
A Scalable Algorithm for Individually Fair K-means Clustering
一种可扩展的个体公平K均值聚类算法
方法
设计快速局部搜索算法:提出首个快速局部搜索算法,运行时间Q(nk²),获得双标准(6, O(1))近似。
实验验证:通过实验验证算法性能,与现有算法比较。
算法改进:结合先前算法和快速K-means算法的思想,专注于k-means问题。
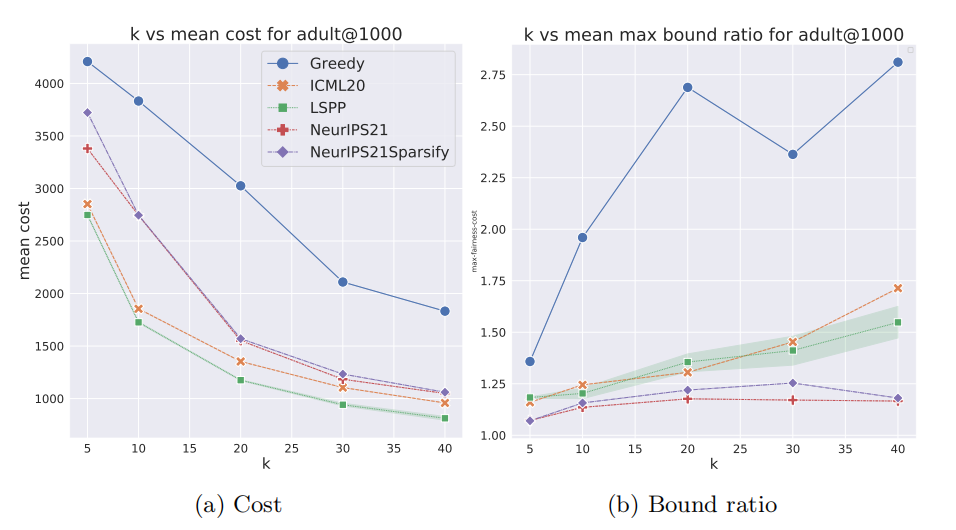
创新点
理论与实践结合:算法不仅在理论上具有良好的近似保证,而且在实验中也显示出比先前工作更快的速度和更低成本的解决方案。
性能提升:算法在处理大规模数据集时表现出色,比以往算法快数百倍,能够处理多达60万点的数据集,而其他公平基线算法在处理4000至25000点时就需要1小时。
成本与公平性优化:尽管近似保证较差,但算法在成本和公平性目标上优于先前算法,成本接近不公平的VanillaKMeans。
论文4:
Local Search k-means++ with Foresight
具有前瞻性的局部搜索k-means++算法
方法
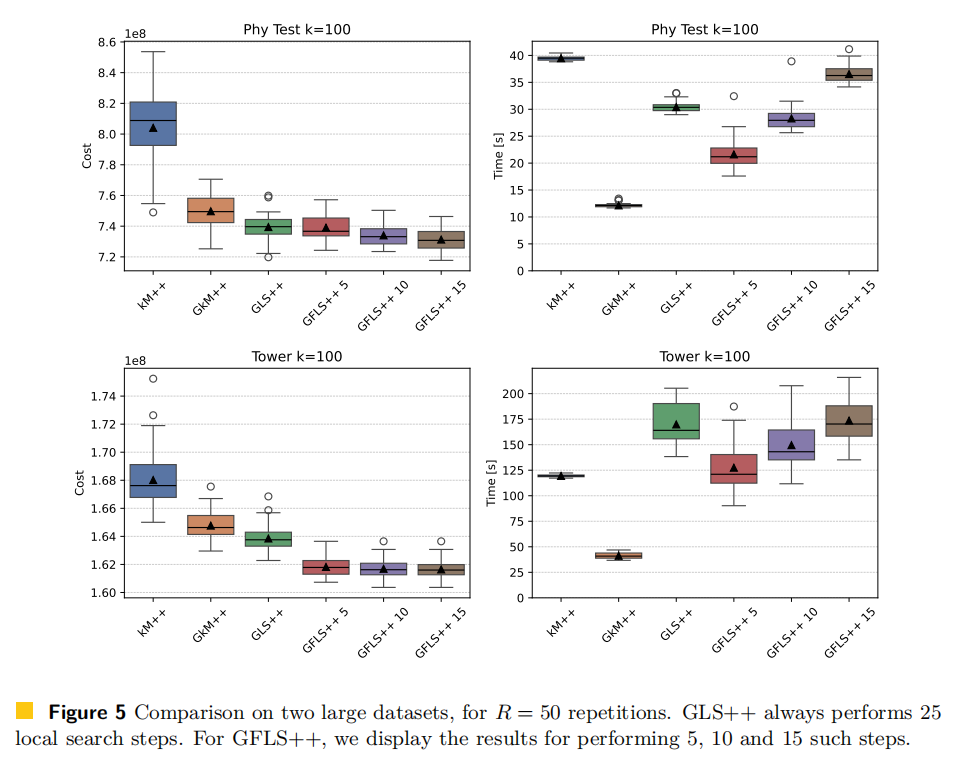
提出FLS++算法:结合局部搜索和d2采样,每个局部搜索步骤执行一次Lloyd迭代。
算法优化:通过实验验证FLS++算法的性能,与k-means++和LS++比较。
性能评估:评估算法在不同数据集上的性能,包括成本和运行时间。
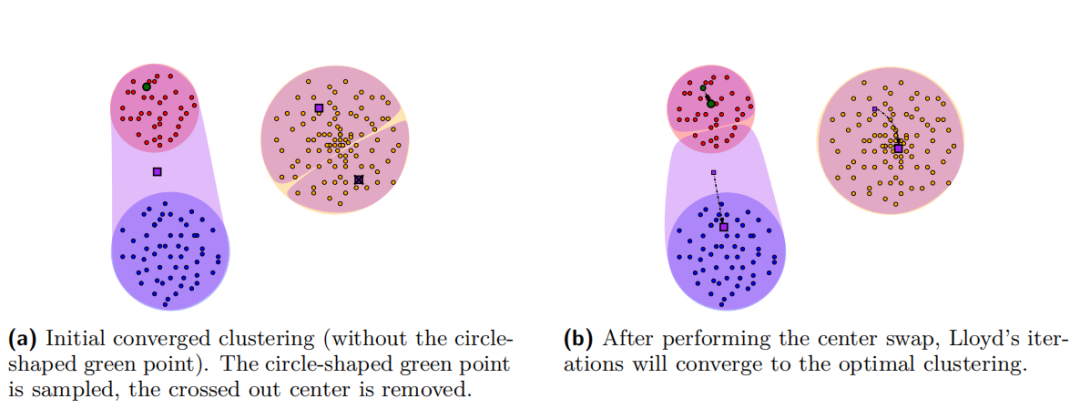
创新点
前瞻性搜索:FLS++通过在局部搜索步骤中引入Lloyd迭代,提高了k-means++算法的实用性能,平均成本比LS++低。
性能提升:FLS++在解决方案质量和运行时间上都优于现有的k-means++和LS++方法,例如在某些数据集上,FLS++的平均成本比LS++低约1%至2%。
贪心初始化:研究了贪心d2采样在实践中的流行度,尽管其理论近似比率较差,但实验表明在大多数数据集上,使用贪心初始化的所有标准算法的平均成本都有显著下降。

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









