






前言:
网页链接:最新8k鬼刀壁纸!『2015-2022』合集 - 知乎
在爬取数据之前要先做好准备工作,然后再对想要的数据进行数据爬取。
准备工作:
在爬取之前可以先把爬虫的模板代码写好,比如:
import requests
class Spider(object):
def __init__(self):
self.headers = {}
def get_main_html(self): # 定义请求第一次的函数
url = '' # 设置url
response = requests.get(url=url, headers=self.headers) # 发请求
def run(self): # 定义主函数 由主函数去统一调度类当中的方法
# 调用get_main_html()函数
self.get_main_html()
if __name__ == '__main__':
# 实例化类对象
spider = Spider()
# 调用类当中的run方法 也就是主函数
spider.run()
然后再寻找需要爬的数据,而这个数据也就是下载图片所需要的数据:
首先打开浏览器,找到需要爬取数据的网页,然后对其进行抓包:
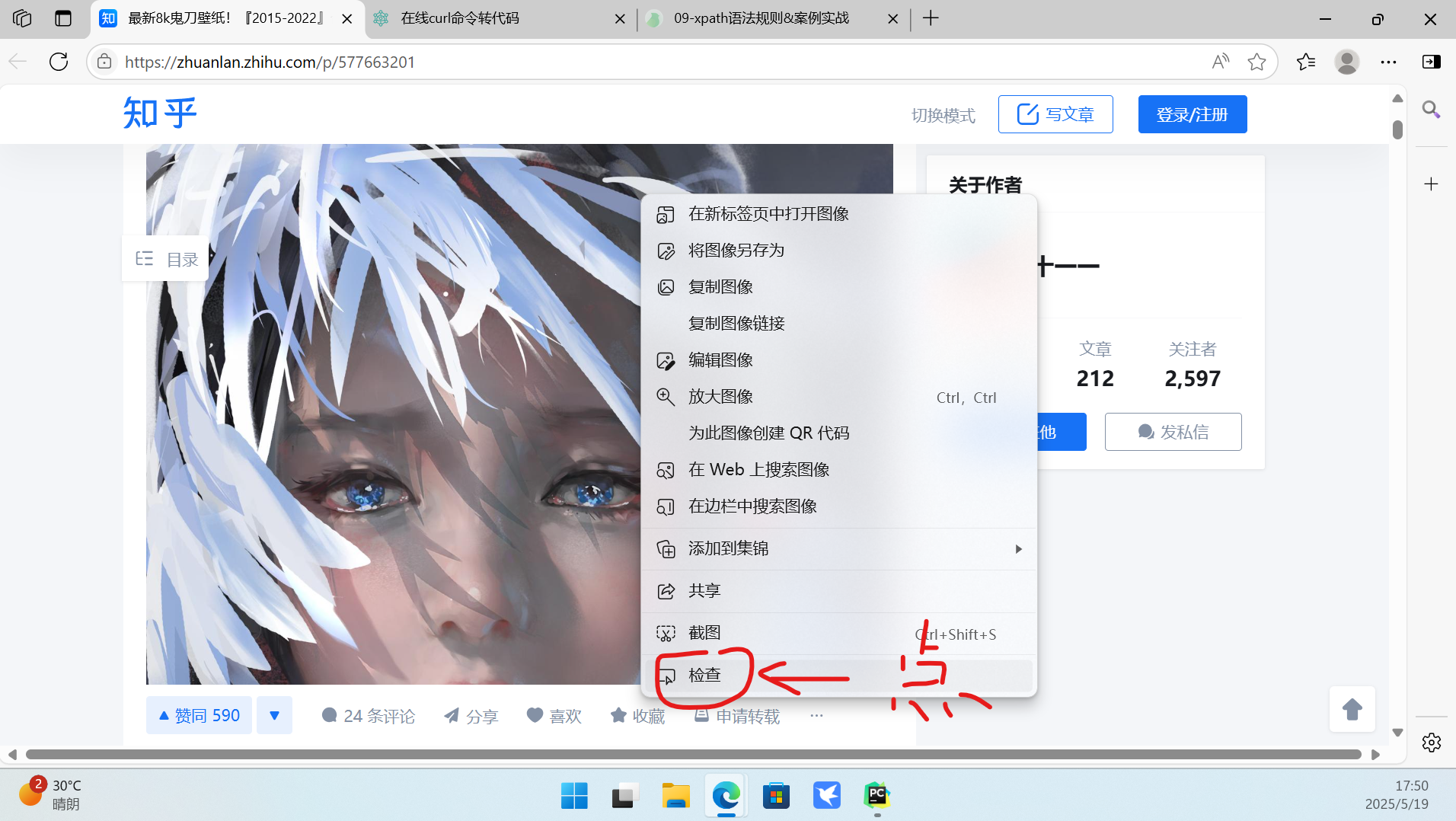
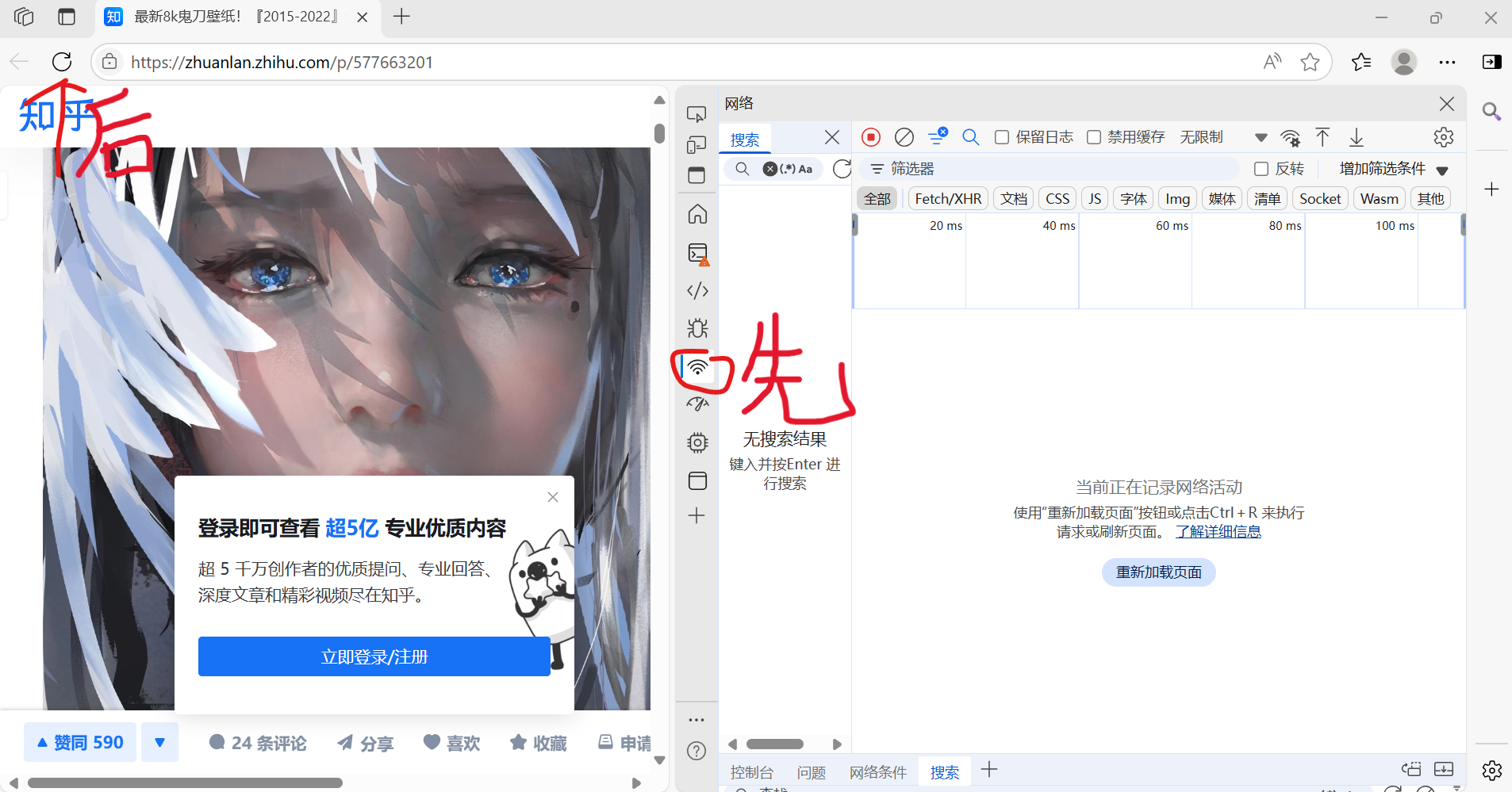
通过搜索找到图片下载连接所在的数据包:
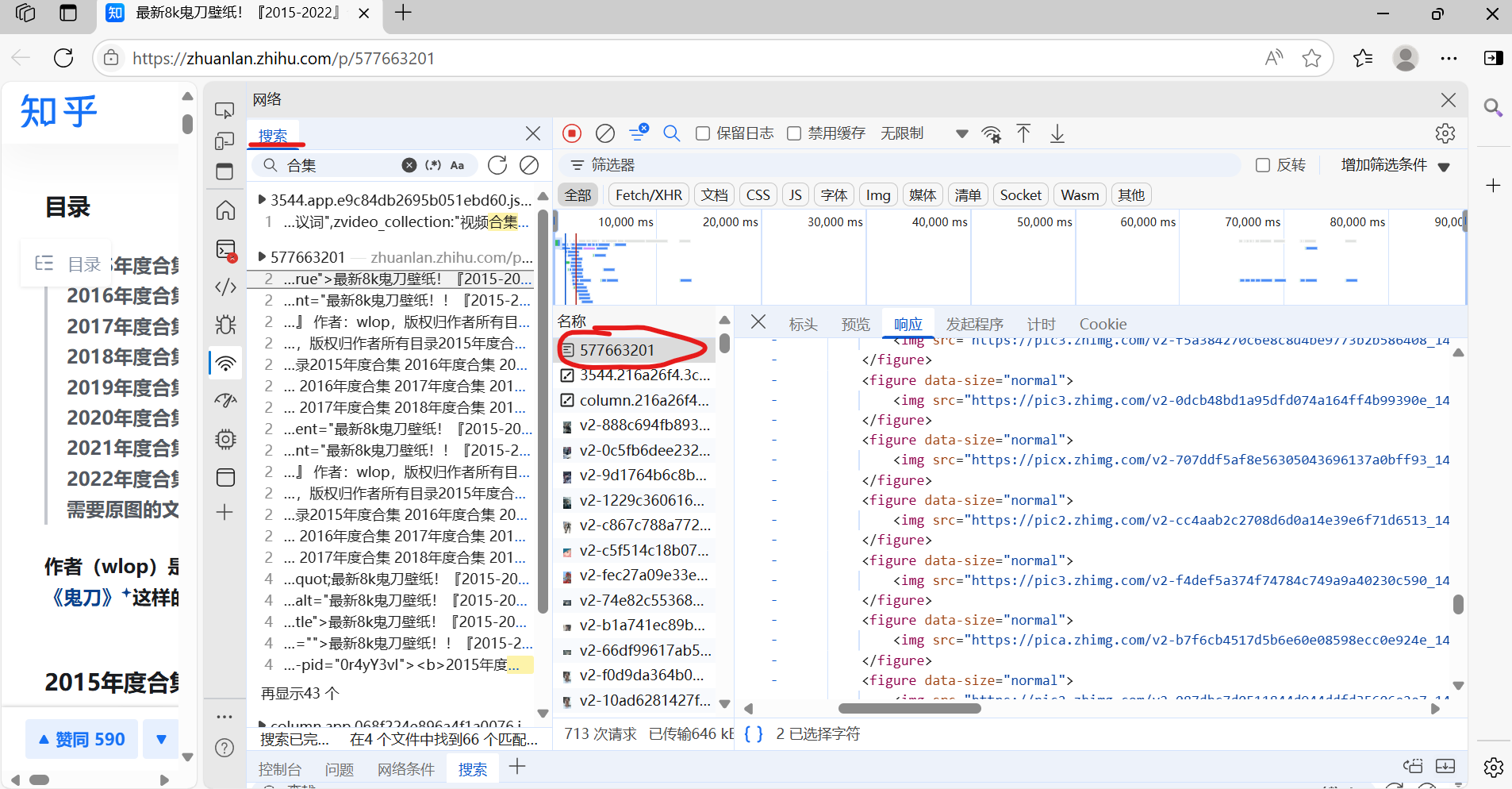
然后复制它的curl,把curl转换成所需要的数据(数据转换用curl转换器,网上搜就行):
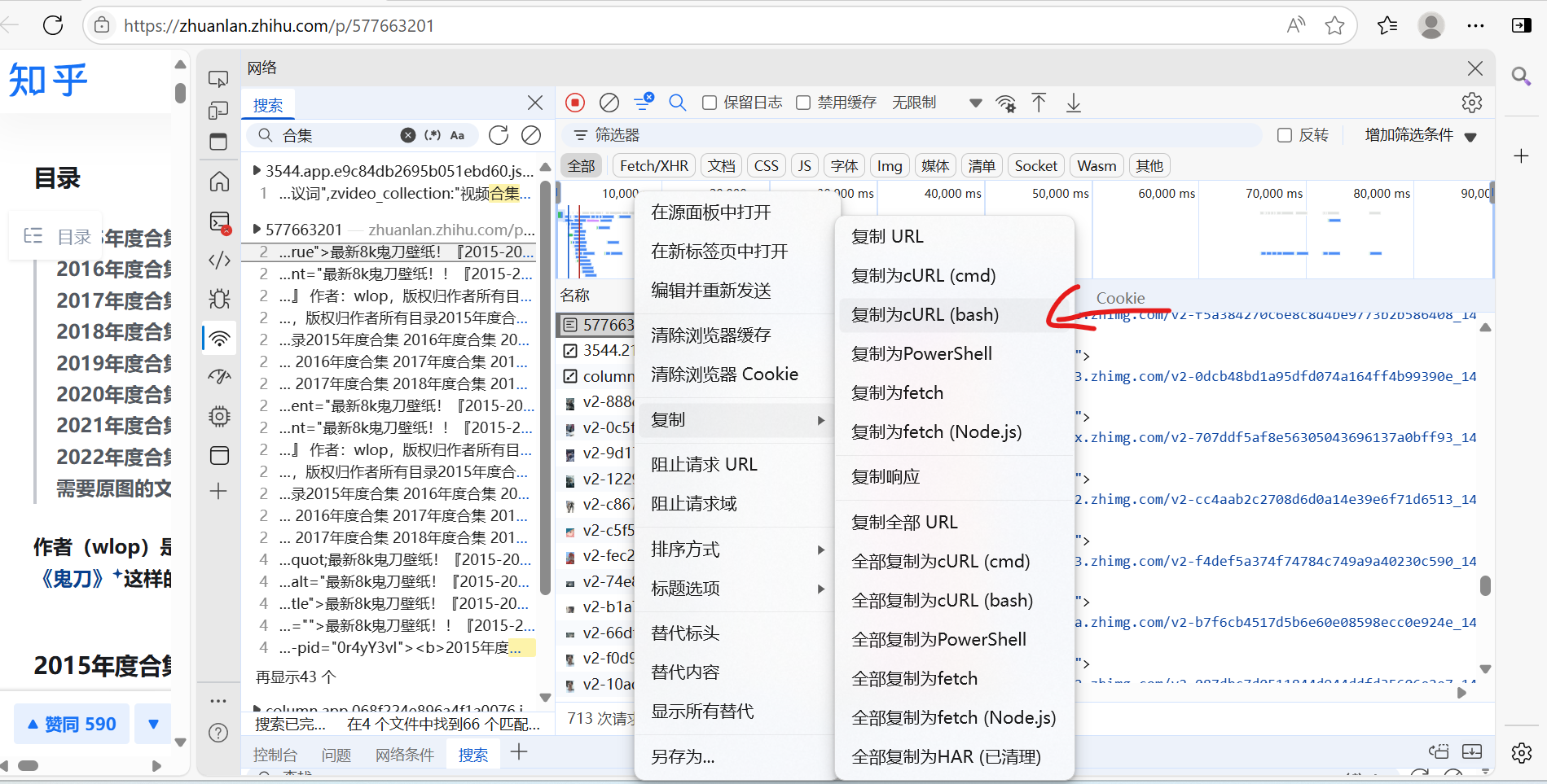
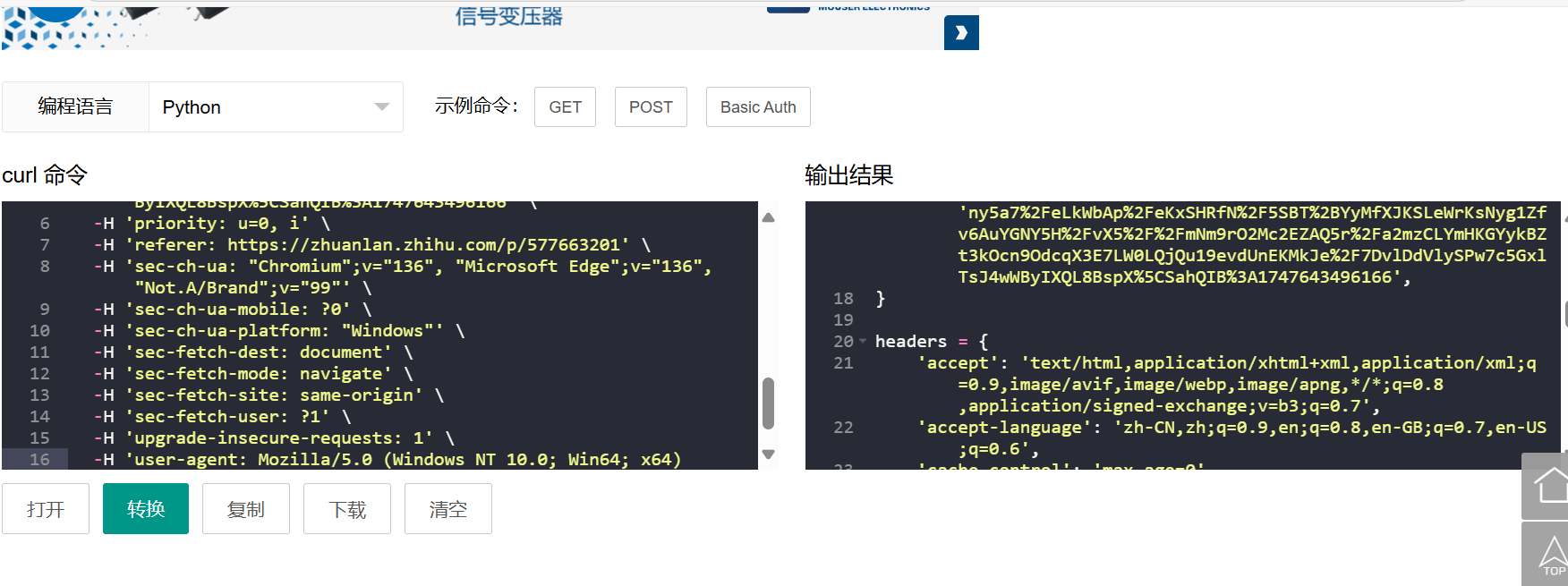
把headers 和 url 复制到代码中:
def __init__(self):
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'max-age=0',
'priority': 'u=0, i',
'referer': 'https://zhuanlan.zhihu.com/p/577663201',
'sec-ch-ua': '"Chromium";v="136", "Microsoft Edge";v="136", "Not.A/Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0',
'cookie': '__snaker__id=TUma9FgSLKdqLIr9; SESSIONID=MJnwfZLaDO5erv5q11TIuLj9Bzwt56CmwpI4qtiOokF; JOID=W1kRBUOVdTruxNGqB7eOJKZ4GM0QvlMbw-b6jCa3XhzP6fOBITEJH4nN3K0LcFLLS0VJRkshfCOk-QQ170kxtw0=; osd=V1sWA0iZdz3oz92oALGFKKR_HsYcvFQdyOr4iyC8Uh7I7_iNIzYPFIXP26sAfFDMTU5FREwndy-m_gI-40s2sQY=; _xsrf=SOwyFmGYdlbEoL6zQOMaKmId8Eecktge; _zap=1980844d-457a-4610-b93e-318d248279fd; d_c0=vecTKa3GbhqPTsSxI0WbSjUXKhk_5DUS_LM=|1746890655; __zse_ck=004_ZksXnoLcuyoa4g78HdC0bo59yLPnJ5KOVOM70fFnvd3gMfilOG6vjzKoS3Owvy=e5yi9bXoHVeHEr2GZQ24lJRWzBMsSLsPDudzEnyI0GrbUGFntm36xUX230HIjFsRT-FeFIKXa8o9eQcFCMTSAB1ot6Y0TRup/ZylESAlQ1Isvk8lRrvuDRkP8Z8lNeF1cTzfaCXGRAkONhwAoBXaiIsDJWtWbttBzsBGDHp/ujNDZvuN0xzK6YPybf4Nr1r4kf; BEC=738c6d0432e7aaf738ea36855cdce904; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1747457855,1747471426,1747485218,1747549098; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1747549098; HMACCOUNT=1917265C86B0D05D; captcha_session_v2=2|1:0|10:1747549097|18:captcha_session_v2|88:T2tTai9aU3JkSktOeTZldzF4cTJxVUIwZDcveFQ1Q0xpVFQrVVpHSzZBS25MMyt4dkZtRDYvRS9Gc2p1SEs0ag==|d726cfa0537854d91c4d0e8522582cf0589f00588edefce717e09899e7e7d1dd; DATE=1746890659366; cmci9xde=U2FsdGVkX19ixp1gWtK6e/97Y3gyDf73IETE5vs4KvSl4Pz+0S6hZDL2m/Ulu6eTBYrISJMl4dr5ssDuzTRtlA==; pmck9xge=U2FsdGVkX19DUbP6XNBU3gWxO9HaZM+8ubdr/nozums=; crystal=U2FsdGVkX19p0WoTb+uxc74SGqj/uqrhAmGNZ8zY2paLhd1XwunwPMTzaK6Lm3Zfm6tFIu9mW58m1qq4yIavJJasKJAlMBAzdE6OIpiEfClINgQPrju0FMPEEGVC/Z0QMUn/cEn+YlRluXsgIaLv+RVfcqZJBAImVqa/QHoI/QY43iwPRsJzZ3ICLq6CSoKZI96xKBbI8CHjUQTetSjBtWLlbXhNZGykTcrlO1QALX5LH2gGpD87p7506nSsw+/M; assva6=U2FsdGVkX1+4jL38wO0lIpy6uvxypu/Mo8dyRvZqgEI=; assva5=U2FsdGVkX1+Y7wW7qx0h5y2461jwizhICdGjB6FNlZfUVsMTRH4p51yjBns2GNuX/Y6B4dnA788mCPv6VkpHJA==; vmce9xdq=U2FsdGVkX1+RPVdn0ZkFu9zc83wiBDgN+6MToIwu5Pou++j51GFKWJNqqy22GNUZD547hROOlLoiZFOtp5g9H3KVdNnNONlYpuEcblD+Q+gDkHwIOmPms4cfG3zvj4Dq1vhRBCCVrxoxJRtmxtsNinlZfU0lFJIGwAFt9Pugwc8=; gdxidpyhxdE=hJ%2BX8lXrd1R08okRJd66vrxTildL%2F%2F3US6yYtlAzS2HPsfvgycRv7%2Bm5Y5Uxm5qPc320WtdxmHoL6bwYtoNwmJ6%2BV%2BvRSM08N%2B9aqN7bS3qx11cVs0L%2FkB21Er3xC6lm73NAv%2B4egG8hsjjIC%2F7k%2BbCq0%5Coqqsuz7GNrXUojJzvEwmal%3A1747549999764',
} def get_main_html(self): # 定义请求第一次的函数
url = 'https://zhuanlan.zhihu.com/p/577663201' # 设置url
response = requests.get(url=url, headers=self.headers) # 发请求准备工作做好后,开始写代码
正式写代码爬取:
识别爬取包中数据的类型:
通过爬取包发现,其数据类型为Html,所以要导入lxml库
import requests
from lxml import etree写代码:
通过etree对数据渲染成一个可以使用xpath解析的对象:
def get_main_html(self): # 定义请求第一次的函数
url = 'https://zhuanlan.zhihu.com/p/577663201' # 设置url
response = requests.get(url=url, headers=self.headers) # 发请求
tree=etree.HTML(response.text)xpath 先找到单条数据标签列表,单条数据列表包含全部内容 and 兄弟标签是其他的数据标签,循环单条数据标签,取其具体的数据。
但要注意:具体情况具体分析。
如本次数据中图片只在一个标签中(即div class="RichText ztext Post-RichText css-1yl6ec1"),所以可以直接写个列表把图片的连接放到此列表中,此外还要写个序号列表,用于图片命名。
def get_main_html(self): # 定义请求第一次的函数
url = 'https://zhuanlan.zhihu.com/p/577663201' # 设置url
response = requests.get(url=url, headers=self.headers) # 发请求
tree=etree.HTML(response.text)
img_list=tree.xpath('//div[@class="RichText ztext Post-RichText css-1yl6ec1"]/figure/img/@src')
xuihao=list(range(1,len(img_list)+1))把序号列表和图片列表准备好后,再写个方法(函数)用于写下载图片:
首先用for循环和zip函数把两个列表一一对应起来,然后取出图片链接和序号。
创建img_response来请求图片链接,然后写存储路径,最后写入文档。
def down_load(self,xuihao,img_list):
for i in zip(xuihao,img_list):
img_url=i[1]
img_name=i[0]
img_response=requests.get(url=img_url,headers=self.headers)
path=f'./图片/{img_name}.jpg'
with open(path,'wb') as f:
f.write(img_response.content)
print(f'{img_name}下载完成')调用down_load方法:
def get_main_html(self): # 定义请求第一次的函数
url = 'https://zhuanlan.zhihu.com/p/577663201' # 设置url
response = requests.get(url=url, headers=self.headers) # 发请求
tree=etree.HTML(response.text)
img_list=tree.xpath('//div[@class="RichText ztext Post-RichText css-1yl6ec1"]/figure/img/@src')
xuihao=list(range(1,len(img_list)+1))
self.down_load(xuihao,img_list)最后运行代码
成功运行:
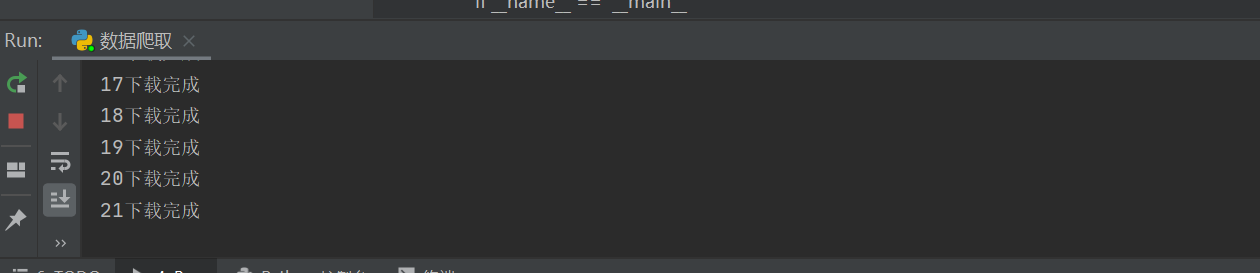
注意:
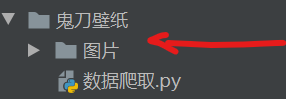
(1)在运行代码前要在此文件包下创建一个名为图片的文档,再运行代码
(2)headers可能会失效,失效时要重新写入全新的headers

全部代码:
import requests
from lxml import etree
class Spider(object):
def __init__(self):
self.headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'max-age=0',
'priority': 'u=0, i',
'referer': 'https://zhuanlan.zhihu.com/p/577663201',
'sec-ch-ua': '"Chromium";v="136", "Microsoft Edge";v="136", "Not.A/Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0',
'cookie': '__snaker__id=TUma9FgSLKdqLIr9; SESSIONID=MJnwfZLaDO5erv5q11TIuLj9Bzwt56CmwpI4qtiOokF; JOID=W1kRBUOVdTruxNGqB7eOJKZ4GM0QvlMbw-b6jCa3XhzP6fOBITEJH4nN3K0LcFLLS0VJRkshfCOk-QQ170kxtw0=; osd=V1sWA0iZdz3oz92oALGFKKR_HsYcvFQdyOr4iyC8Uh7I7_iNIzYPFIXP26sAfFDMTU5FREwndy-m_gI-40s2sQY=; _xsrf=SOwyFmGYdlbEoL6zQOMaKmId8Eecktge; _zap=1980844d-457a-4610-b93e-318d248279fd; d_c0=vecTKa3GbhqPTsSxI0WbSjUXKhk_5DUS_LM=|1746890655; __zse_ck=004_ZksXnoLcuyoa4g78HdC0bo59yLPnJ5KOVOM70fFnvd3gMfilOG6vjzKoS3Owvy=e5yi9bXoHVeHEr2GZQ24lJRWzBMsSLsPDudzEnyI0GrbUGFntm36xUX230HIjFsRT-FeFIKXa8o9eQcFCMTSAB1ot6Y0TRup/ZylESAlQ1Isvk8lRrvuDRkP8Z8lNeF1cTzfaCXGRAkONhwAoBXaiIsDJWtWbttBzsBGDHp/ujNDZvuN0xzK6YPybf4Nr1r4kf; BEC=738c6d0432e7aaf738ea36855cdce904; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1747457855,1747471426,1747485218,1747549098; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1747549098; HMACCOUNT=1917265C86B0D05D; captcha_session_v2=2|1:0|10:1747549097|18:captcha_session_v2|88:T2tTai9aU3JkSktOeTZldzF4cTJxVUIwZDcveFQ1Q0xpVFQrVVpHSzZBS25MMyt4dkZtRDYvRS9Gc2p1SEs0ag==|d726cfa0537854d91c4d0e8522582cf0589f00588edefce717e09899e7e7d1dd; DATE=1746890659366; cmci9xde=U2FsdGVkX19ixp1gWtK6e/97Y3gyDf73IETE5vs4KvSl4Pz+0S6hZDL2m/Ulu6eTBYrISJMl4dr5ssDuzTRtlA==; pmck9xge=U2FsdGVkX19DUbP6XNBU3gWxO9HaZM+8ubdr/nozums=; crystal=U2FsdGVkX19p0WoTb+uxc74SGqj/uqrhAmGNZ8zY2paLhd1XwunwPMTzaK6Lm3Zfm6tFIu9mW58m1qq4yIavJJasKJAlMBAzdE6OIpiEfClINgQPrju0FMPEEGVC/Z0QMUn/cEn+YlRluXsgIaLv+RVfcqZJBAImVqa/QHoI/QY43iwPRsJzZ3ICLq6CSoKZI96xKBbI8CHjUQTetSjBtWLlbXhNZGykTcrlO1QALX5LH2gGpD87p7506nSsw+/M; assva6=U2FsdGVkX1+4jL38wO0lIpy6uvxypu/Mo8dyRvZqgEI=; assva5=U2FsdGVkX1+Y7wW7qx0h5y2461jwizhICdGjB6FNlZfUVsMTRH4p51yjBns2GNuX/Y6B4dnA788mCPv6VkpHJA==; vmce9xdq=U2FsdGVkX1+RPVdn0ZkFu9zc83wiBDgN+6MToIwu5Pou++j51GFKWJNqqy22GNUZD547hROOlLoiZFOtp5g9H3KVdNnNONlYpuEcblD+Q+gDkHwIOmPms4cfG3zvj4Dq1vhRBCCVrxoxJRtmxtsNinlZfU0lFJIGwAFt9Pugwc8=; gdxidpyhxdE=hJ%2BX8lXrd1R08okRJd66vrxTildL%2F%2F3US6yYtlAzS2HPsfvgycRv7%2Bm5Y5Uxm5qPc320WtdxmHoL6bwYtoNwmJ6%2BV%2BvRSM08N%2B9aqN7bS3qx11cVs0L%2FkB21Er3xC6lm73NAv%2B4egG8hsjjIC%2F7k%2BbCq0%5Coqqsuz7GNrXUojJzvEwmal%3A1747549999764',
}
def get_main_html(self): # 定义请求第一次的函数
url = 'https://zhuanlan.zhihu.com/p/577663201' # 设置url
response = requests.get(url=url, headers=self.headers) # 发请求
tree=etree.HTML(response.text)
img_list=tree.xpath('//div[@class="RichText ztext Post-RichText css-1yl6ec1"]/figure/img/@src')
xuihao=list(range(1,len(img_list)+1))
self.down_load(xuihao,img_list)
def down_load(self,xuihao,img_list):
for i in zip(xuihao,img_list):
img_url=i[1]
img_name=i[0]
img_response=requests.get(url=img_url,headers=self.headers)
path=f'./图片/{img_name}.jpg'
with open(path,'wb') as f:
f.write(img_response.content)
print(f'{img_name}下载完成')
def run(self): # 定义主函数 由主函数去统一调度类当中的方法
# 调用get_main_html()函数
self.get_main_html()
if __name__ == '__main__':
# 实例化类对象
spider = Spider()
# 调用类当中的run方法 也就是主函数
spider.run()

















 9952
9952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









