






目录
一、引言
云起书院作为阅文集团旗下的网络文学平台,拥有丰富的小说资源和读者数据,非常适合0基础的新手小白去练习简单的爬虫技能。通过本教程,你将学会如何使用Python语言,结合强大的requests库和BeautifulSoup库,爬取云起书院会员榜单上200+本热门小说的网页信息、解析网页提取想要的数据(例如:书名、作者、简介、类型、是否完结、字数、详情页链接等),并使用Pyecharts库对获取的数据进行可视化分析,了解会员榜单上最受欢迎的小说种类。
二、准备工作
1、环境搭建
在开始我们的爬虫项目之前,你需要确保现你的开发环境中已安装了所有的工具和库。以下是搭建环境的步骤:
(1)开发环境:Jupyter Notebook
推荐使用Jupyter Notebook作为我们的主要开发环境。Jupyter Notebook 是一个开源的 Web 应用程序,非常适合于数据清洗和转换、数值模拟、统计建模、数据可视化以及许多其他类型的数据分析工作。(如果你还没有安装,推荐通过安装 Anaconda去启动并创建一个Jupyter Notebook)
(2)安装:库
教程中将使用以下Python库:requests、beautifulsoup4、pandas、openpyxl、pyecharts、time。你可以通过运行以下命令在Notebook完成对他们的安装。注意:需先使用“!pip”安装库,再用 from.... import从库中导入所需要的工具。
#数据爬虫和收集
import requests
!pip install beautifulsoup4
from bs4 import BeautifulSoup
!pip install openpyxl
from openpyxl import Workbook
import time
#读取excel表并做数据可视化
import pandas as pd
!pip install pyecharts
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_NOTEBOOK
from IPython.display import Image2、工具介绍
以下是针对每个库的基础介绍以及在接下来任务中的用途,相信能够让你充分了解它们的作用。
(1)requests:requests是一个简单易用的HTTP库,允许你发送HTTP/1.1请求而无需手动添加查询字符串或编码,可以轻松地处理GET和POST请求,获取网页信息。
(2)BeautifulSoup:BeautifulSoup是一个用于解析HTML和XML文档的库。它创建了一个解析树,可以方便地提取HTML中的标签、属性和文本内容,是爬虫项目中不可或缺的工具。
(3)Pandas:pandas是一个强大的数据分析库,提供了DataFrame和Series两种数据结构,使得数据操作和分析变得简单高效。我们将使用它来处理和分析爬取的数据。
(4)Openpyxl:openpyxl是一个用于读写Excel 2010 xlsx/xlsm文件的库。我们将使用它将爬取的数据保存到Excel文件中。
(5)Pyecharts:pyecharts是一个用于生成Echarts图表的库。Echarts是一个由百度开发的开源可视化库,pyecharts提供了一个Python接口,使得我们可以轻松地在Python中创建各种交互式图表。
(6)time:控制请求时间,避免请求的频繁过高被阻拦。
总而言之,通过这些工具和库,我们将能够构建一个完整的爬虫项目,从爬取数据到数据可视化。在接下来的章节中,我将详细介绍如何使用这些工具来完成任务。
三、爬取数据
1、查找网站
首先,你需要在浏览器中查找云起书院网站,点击榜单观察网页信息。确定你想要爬取的数据(eg:作者、简介等),以及你想要爬取的网页数量(eg:整个榜单是10页)后,输入如下代码:
#原网页链接是:https://yunqi.qq.com/rank/549108_1
#但1是html实体编码的一部分,可能会导致读取失败,所以请去掉
base_url = 'https://yunqi.qq.com/rank/549108_'
page_count = 102、创建Excel表格储存数据
其次,为了储存爬取的数据,我们可以利用openpyxl库中的 "workbook" 创建Excel并设置表头。
#利用openpyxl中的 "workbook" 创建Excel
workbook = Workbook()
sheet = workbook.active
#设置Excel sheet 的表头
sheet = workbook.active
sheet['A1'] = '名称'
sheet['B1'] = '作者'
sheet['C1'] = '简介'
sheet['D1'] = '类型'
sheet['E1'] = '是否完结'
sheet['F1'] = '字数'
sheet['G1'] = '链接'
#从第二行开始写入数据
row = 23、分析网站
接着,我们需要对要爬取的网页做一个全面的分析和观察:
(1)观察网址你可发现:每翻一页,网页url链接的末尾数字就会+1。(eg:第一页https://.......549108_1,第二页是:https://.......549108_2 。
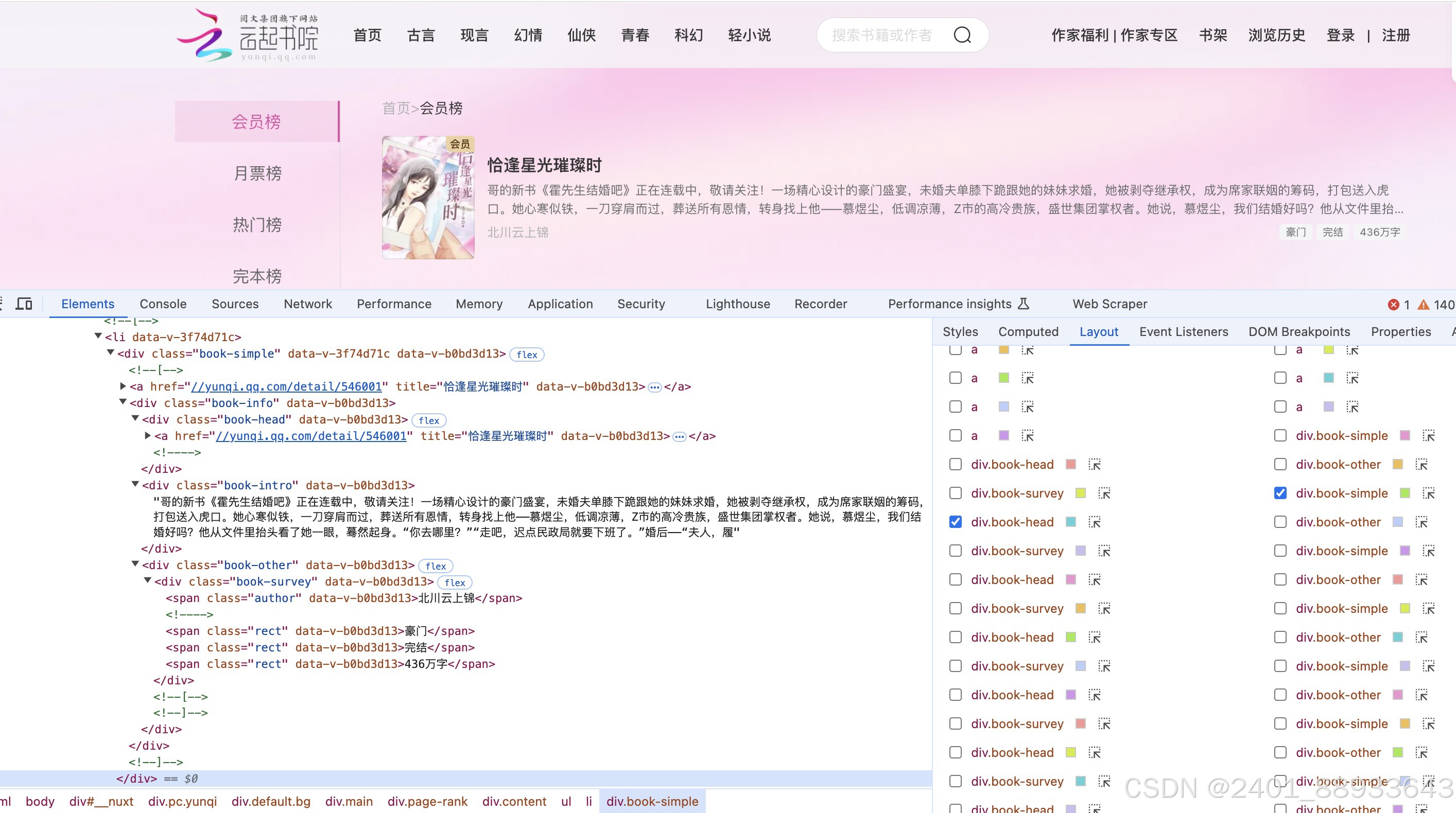
(2)打开浏览器的开发者工具可以查看云起书院榜单页面的HTML结构。以小说《恰逢星光璀璨时》这栏为例,你可以清晰地知道每一个板块的组成元素。
4、编写爬虫代码
分析完网站后就到了整个教程中最核心的部分——爬虫代码的编写。考虑到新手小白容易出错,除了解释主要代码外,还会在其中穿插一些用于检测代码是否有效的语句,新手可选择性使用。
(1)用for语句,遍历云起书院会员榜的每一页并构造每一页的URL;前面观察到翻页就是原来网页链接的末尾数字+1,所以是page_count+1。
#观察网址可发现:翻页就是原来网页链接的末尾数字+1,所以是page_count+1
#此处for语句的作用为:遍历云起书院会员榜的每一页&构造每一页的URL
for page in range(1, page_count + 1):
url = base_url + str(page)
#此处“print”语句仅用于验证是否运行成功,非必要内容
print(f"output: {url}")(2)使用requests发起向网页发起爬虫请求,为避免被限制爬虫,可以在headers中添加User-Agent,模拟浏览器的请求。在获取网页信息后用beautifulsoup解析网页html。
#同上,此处"try...except"语句仅用于检查代码是否有运行问题,非必要内容
try:
#requests发起爬虫请求;headers添加User-Agent,模拟浏览器的请求
response = requests.get(url,headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
})
#检查响应码
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
(3)观察前面的html你能发现,每一栏小说信息都被<li>这个大标签所包含,我们可以用beautifulsoup中的find_all功能解析html,找到小说所在的html元素板块,去目标信息所在标签内提取信息。

值得一提的是,在html中“类型”“完结状态”“字数”三个<span>标签都在同一个父元素下,且拥有相同的类名class=“rect”。那么解决这个问题呢?可以看到它们的位置顺序是固定的:类型-状态-字数,所以可以根据它们在父元素中的位置来区分它们。
#找到所有小说所在的html元素板块
novel_list = soup.find_all('li', {'data-v-3f74d71c': True})
for novel in novel_list:
#提取小说名
title = novel.find('h4', class_='book-title').text.strip()
#提取作者名称
author = novel.find('span', class_='author').text.strip()
#提取小说介绍
intro = novel.find('div', class_='book-intro').text.strip()
#观察到类型”、“状态”、“字数”三个<span>标签都在同一个父元素下且拥有相同的类名rect
#但它们的位置顺序是固定的:类型-状态-字数 可以根据它们在父元素中的位置来区分它们
#提取小说类型
category = novel.find_all('span', class_='rect')[0].text.strip()
#提取完结状态
statue = novel.find_all('span', class_='rect')[1].text.strip()
#提取小说字数
word_count = novel.find_all('span', class_='rect')[2].text.strip()
#提取小说详情链接
href = novel.find('a')['href']五、保存数据
可以使用time来控制你请求的速度,以避免请求频率过高被阻拦。爬取之后,你就可以将数据写入Excel中的对应列中,并保存到你想要的位置中,到这一步我们爬虫的任务已全部完成了!PS:如果你对数据可视化感兴趣,可以继续浏览第四部分的内容。
#将爬取数据写入Excel sheet的相应列中
sheet[f'A{row}'] = title
sheet[f'B{row}'] = author
sheet[f'C{row}'] = intro
sheet[f'D{row}'] = category
sheet[f'E{row}'] = statue
sheet[f'F{row}'] = word_count
sheet[f'G{row}'] = href
row += 1
## 每请求一次,暂停1秒,以避免请求频率过高被阻拦
time.sleep(1)
#以下内容仅用于检查代码是否运行成功,非必要内容
print(f" {page} success ")
except requests.RequestException as e:
print(f"request error: {e}")
except Exception as e:
print(f"Parsing error:: {e}")# 保存Excel到指定位置,file_path = '路径/想取的文件名.xlsx';
file_path = '/Users/goexxx/Css_computational thinking/Final project/Blog-01/vip-rank-list.xlsx'
workbook.save(file_path)
#仅用于检查文件是否成功保存到指定位置,非必要内容
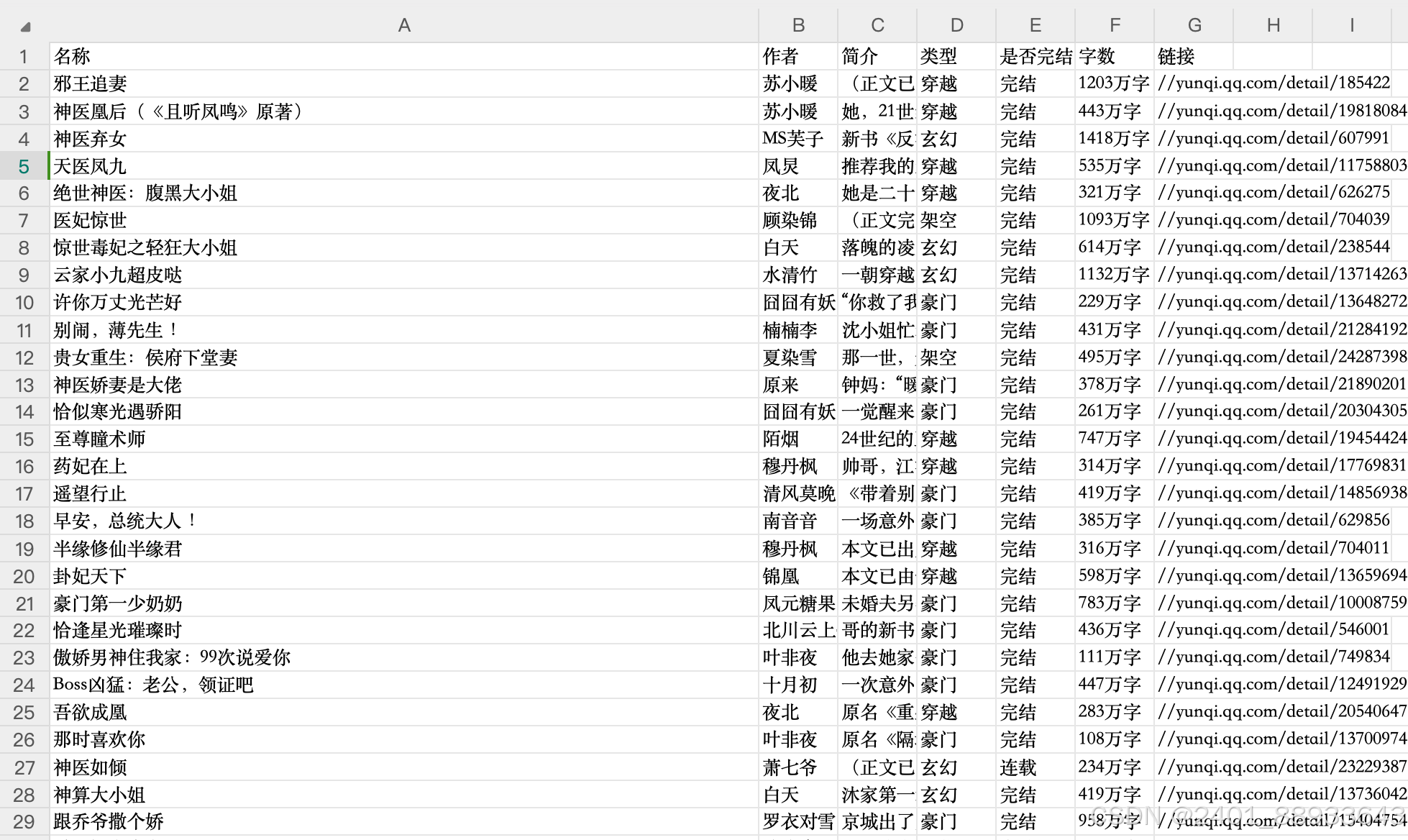
print(f"The data has been saved to {file_path}")以下是爬取后的Excel结果示例图:
四、数据可视化
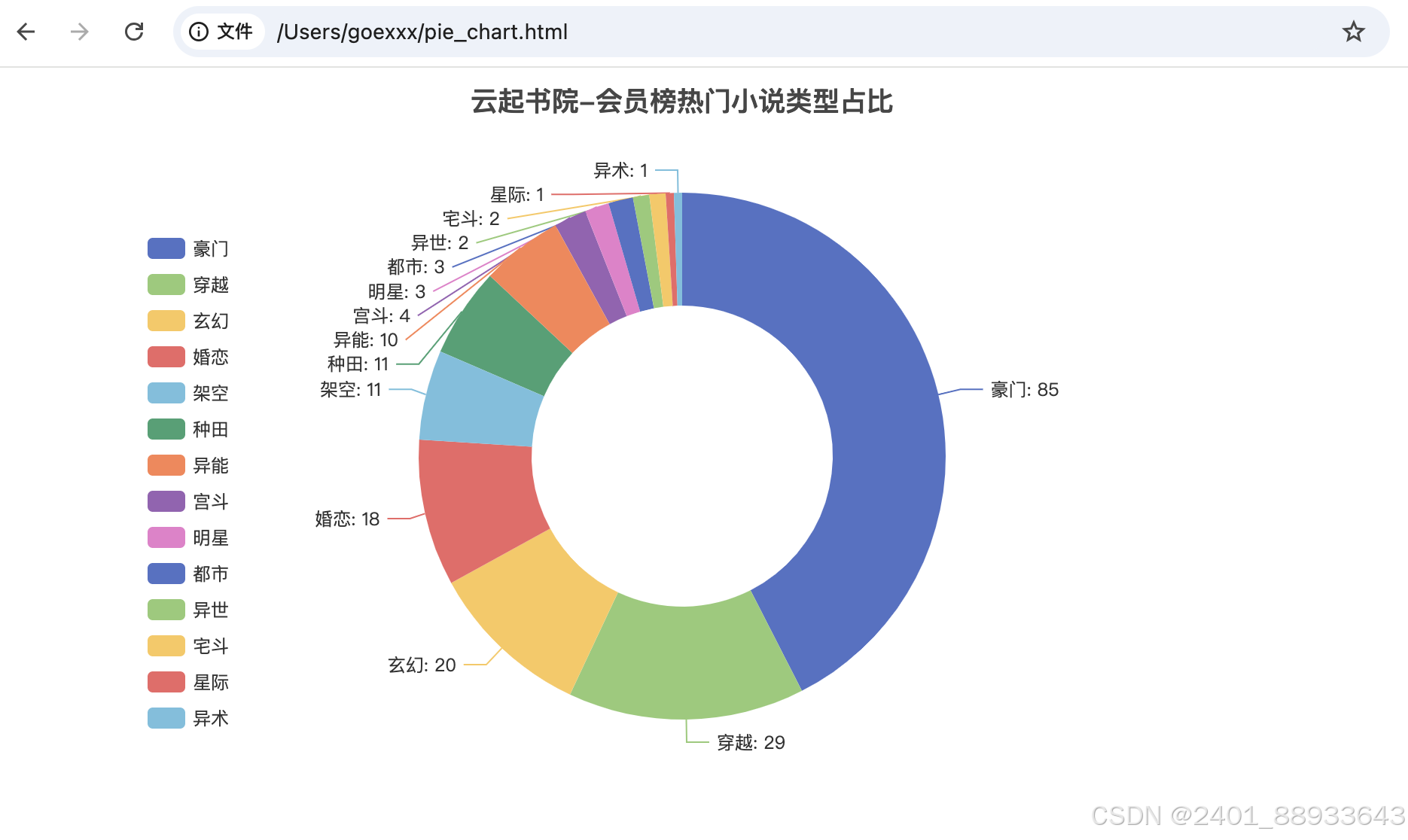
那么在一部分,我们将对爬取到的数据进行分析,并将其制作成可视化饼图,目标是了解会员榜单中收录的两百多本小说的类别占别情况。
1、读取Excel文件&统计每个类型小说数量
你可以用pandas 库的 read_excel 函数从指定的路径 file_path 读取 Excel 文件,并将其内容加载到一个名为 df 的DataFrame中。从 df 中选择名为 '类型' 的列,并使用 value_counts 方法来统计每个唯一值出现的次数,最后将结果存储在变量 category_counts 中。
# 读取Excel文件
df = pd.read_excel(file_path)
# 统计不同类型小说的数量
category_counts = df['类型'].value_counts()2、用Pyecharts创建饼图
# 用Pyecharts的Pie对象创建饼图
pie = (Pie().add(
'',
[list(z) for z in zip(category_counts.index.to_list(), [int(value) for value in category_counts.values])],
radius=['40%', '70%'],center=["50%", "50%"]
).set_global_opts(
title_opts=opts.TitleOpts(title="云起书院-会员榜热门小说类型占比",pos_left="center"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="20%", pos_left="10%")
).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)以下是每个设定的具体说明:
1、add( '', [...],用于添加数据到饼图。
2、radius=[,]定义了饼图的内外半径,以百分比表示;center=[,]定义了图片的位置。
3、set_global_opts 方法用于设置全局配置项,如标题和图例。
4、title_opts=opts.TitleOpts()设置饼图的标题为“小说类型占比”。TitleOpts 是 Pyecharts 中用于配置标题选项的类,pos_left用于设置标题的位置为“中心”。
5、legend_opts=opts.LegendOpts()设置图例的选项。LegendOpts 是 Pyecharts 中用于配置图例选项的类。orient="vertical" 使图例垂直排列,pos_top 和 pos_left 分别设置图例的位置。
6、set_series_opts 方法用于设置系列的配置项,如标签的格式。LabelOpts 是 Pyecharts 中用于配置标签选项的类。formatter="{b}: {c}" 设置标签的显示格式,其中 {b} 是标签名称(类型),{c} 是对应的值(计数)。
3、可视化图片获取
输入代码:pie.render_notebook() 图片可以在jupyter notebooks中直接显示。如果发现无法显示,建议保存成 HTML文件。
pie.render_notebook()
#如果无法显示,建议保存成 HTML文件
pie.render('pie_chart.html')
查看方法为:点开浏览器——输入:file://+ 输出的html文件。以下为效果图
五、结语
恭喜你完成了从环境搭建开始,逐步深入到代码编写、数据提取、数据清洗,直至最终的数据可视化的全流程学习。本篇教程参考了CSDN网站中的《python+requests+BeautifulSoup使用教程及爬虫实战》这篇文章,在其他网站进行实践并做了相关的内容补充。希望我的内容能够对你有所启发,并为你未来探索其他网站和数据集提供帮助。但在使用网络爬虫时,请你遵守相关法律法规和网站的robots.txt规则,尊重数据所有权和隐私权,合理、适度地使用爬虫技术。
六、附录
以下是完整的代码示例:
import requests
!pip install beautifulsoup4
from bs4 import BeautifulSoup
!pip install openpyxl
from openpyxl import Workbook
import time
import pandas as pd
!pip install pyecharts
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_NOTEBOOK
from IPython.display import Image
base_url = 'https://yunqi.qq.com/rank/549108_'
page_count = 10
#创建excel
workbook = Workbook()
sheet = workbook.active
#设计excel表头
sheet['A1'] = '名称'
sheet['B1'] = '作者'
sheet['C1'] = '简介'
sheet['D1'] = '类型'
sheet['E1'] = '是否完结'
sheet['F1'] = '字数'
sheet['G1'] = '链接'
row = 2
for page in range(1, page_count + 1):
url = base_url + str(page)
response = requests.get(url,headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
})
soup = BeautifulSoup(response.text, 'html.parser')
#找到小说所在的HTML元素
novel_list = soup.find_all('li', {'data-v-3f74d71c': True})
for novel in novel_list:
#提取小说名
title = novel.find('h4', class_='book-title').text.strip()
#提取作者名称
author = novel.find('span', class_='author').text.strip()
#提取简洁
intro = novel.find('div', class_='book-intro').text.strip()
#提取类型
category = novel.find_all('span', class_='rect')[0].text.strip()
#提取状态
statue = novel.find_all('span', class_='rect')[1].text.strip()
#提取字数
word_count = novel.find_all('span', class_='rect')[2].text.strip()
#提取链接
href = novel.find('a')['href']
#爬取数据写入Excel
sheet[f'A{row}'] = title
sheet[f'B{row}'] = author
sheet[f'C{row}'] = intro
sheet[f'D{row}'] = category
sheet[f'E{row}'] = statue
sheet[f'F{row}'] = word_count
sheet[f'G{row}'] = href
row += 1
#每请求一次,暂停1秒,以避免请求频率过高被阻拦
time.sleep(1)
# 保存Excel到指定位置,file_path = '电脑路径/想取的文件名.xlsx';
file_path = 'user file path/file_name.xlsx'
workbook.save(file_path)
# 读取Excel文件
df = pd.read_excel(file_path)
# 统计不同类型小说的数量
category_counts = df['类型'].value_counts()
# 用Pyecharts的Pie对象创建饼图
pie = (Pie().add(
'',
[list(z) for z in zip(category_counts.index.to_list(), [int(value) for value in category_counts.values])],
radius=['40%', '70%'],center=["50%", "50%"]
).set_global_opts(
title_opts=opts.TitleOpts(title="云起书院-会员榜热门小说类型占比",pos_left="center"),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="20%", pos_left="10%")
).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render_notebook()
# 如果无法显示,建议保存成 HTML文件
pie.render('pie_chart.html')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









