






大规模运营你的资源舰队比你想象的更容易!
关键字: [Amazon Web Services re:Invent 2024, 亚马逊云科技, Operating Fleet Resources, Managed Nodes, Automation Runbooks, Cloud Operations, Node Management]
导读
过去,在整个组织范围内大规模运营亚马逊云科技、多云和本地资源的机群通常需要许多工具和手动流程。通过自动化提高效率并降低成本。在本次讨论中,您将了解如何在计算机群中使用Amazon Systems Manager、Amazon CloudWatch和其他亚马逊云科技服务,轻松实现资源的自动化和管理。数以千计的亚马逊云科技客户已经使用这些服务来管理其亚马逊云科技、多云、本地甚至物联网(IoT)机群中数百万的资源,用于修补、应用部署、问题解决等多方面。现在亚马逊云科技让这一切变得更加简单!
演讲精华
以下是小编为您整理的本次演讲的精华。
2024年亚马逊云科技 re:Invent大会上的“大规模运营你的资源舰队比你想象的更容易!”(Operating Your Fleet of Resources at Scale is Easier Than You Think)环节由Oren和Eric向与会者致以热烈欢迎。Oren介绍自己是亚马逊云科技智能运维团队的成员,该团队的目标是开发产品、服务和工具,使运维工作变得更加愉快。另一方面,Eric则是一名高级解决方案架构师,负责协助客户在其环境中采用Oren团队开发的服务。
Eric继续概述了本次会议的议程,他表示他们首先将讨论通往良好运维的旅程,包括潜在的陷阱和改进策略。随后,他们将深入探讨一个涉及Banalux的客户场景示例,Banalux是一家虚构的公司。之后,他们将探讨如何纠正运维中的失误并提高整体运维水平。最后,他们将总结本次会议的重点。
在一种无评判的氛围中,Eric邀请与会者举手回答一系列问题,并向他们保证身份将保持匿名。第一个问题是关于使用多个系统来修补托管节点,很多与会者举手表示确实如此。Eric承认这种做法可能会导致运维开销增加,因为需要确定资源的位置,无论是在内部部署、在亚马逊云科技还是在其他云环境中,并适应不同的工具。
第二个问题是关于手动修补节点,有几位与会者举手表示确实如此。第三个问题是关于直接连接到托管节点进行故障排除或日常运维任务,相当多的与会者举手表示确实如此。Eric承认,虽然这种做法不一定会受到评判,因为可能存在合理的使用场景,但在可行的情况下,采用不可变基础设施是更好的选择。
第四个问题是探讨与会者是否缺乏全面的节点清单,导致不确定节点的位置。令人惊讶的是,大多数与会者表示他们对实例部署有全面的了解。最后一个问题是关于手动跟踪软件许可证,这种做法可能会在审计时带来不愉快的惊喜。Eric承认,确实有一些客户在试图确定许可证使用情况时经历了艰难的过程。
在了解与会者的反馈后,Eric向Oren提出了这个问题:“我们如何开始朝着良好的运维之路迈进?”
Oren感谢Eric营造了一种无评判的环境,并表示他们自己也曾犯过上述每一个错误。他强调,追求完美运维是一个持续的旅程,虽然他们从错误中吸取了教训,但能够从他人的经验和战争故事中学习,可以避免重蹈覆辙。Oren承认,即使他们偶尔也会使用远程桌面协议(RDP)或安全外壳(SSH)连接,尽管他们承认这种做法应该避免。他还承认曾经失去对许可证的跟踪,并犯过其他运维疏忽,所有这些都促成了他们目前提供的服务。
Oren随后向与会者介绍了一个虚构的客户Banalux,这是一家以香蕉为主题的照明公司,在混合环境中运营,拥有云端和内部部署的基础设施。为了增加场景的真实性,Oren透露他们已经将Banalux的一些物理服务器带到了舞台上。
Eric阐述了Banalux架构演进的过程,解释说该公司最初在内部环境中运行服务器。随着业务扩展,他们在内部基础设施中添加了更多虚拟机(VM)。为了提高对终端客户的可用性,Banalux随后开始在单个亚马逊云科技账户和区域中配置EC2实例。虽然最初管理这两个环境中的节点并不太麻烦,但随着业务进一步增长,他们不得不添加更多内部服务器,并扩展到多个亚马逊云科技区域,以提高连接性和可用性。
随着Banalux不断发展,他们采用了更多产品并开发了更多应用程序,导致在多个区域中使用了多个亚马逊云科技账户。这种扩展导致运维状态变得更大,拥有数百个亚马逊云科技账户,使得维护托管资源的准确清单并对它们启动远程操作变得越来越具有挑战性。
Oren随后分享了他作为Banalux的DevOps工程师、系统工程师、站点可靠性工程师(SRE)或负责运维自己基础设施的开发人员的个人经历。最初,他会编写代码,SSH进入每台机器,并手动将代码部署到每台服务器上,因为服务器数量相对较少。Banalux将他们的代码打包并发布到自定义yum存储库中,并遵循文档化的流程以确保存储库配置为访问最新的软件包版本。当时,他们认为自己非常精通。
然而,随着主机数量的增加,即使使用并行脚本,SSH进入每台主机并部署代码所需的时间也变得越来越繁重,因为偶尔会出现错误和问题。为了解决这一挑战,Banalux决定将职能分为开发团队和DevOps团队。DevOps团队将负责并行手动SSH进入机器,因为他们的人数与服务器数量的增加成正比。
不幸的是,这种方法也无法有效扩展,因为人力资源无法线性扩展,招聘人员的数量也是有限的。因此,Banalux的DevOps团队接近开发人员,表示他们对于尽管被聘为熟练专业人员却仍需执行手动任务感到不满,并建议采用持续集成和持续部署(CI/CD)方法。
最初,Oren认为实施CI/CD已经解决了他们的运维挑战。该过程涉及构建代码、将其集成到管道中进行自动化测试,然后将其部署到所有不同的机器上。如果出现任何问题,该过程将自动回滚更改。在这一点上,Oren认为他们已经实现了目标。
虽然CI/CD管道解决了他们基础设施的开发和DevOps方面的问题,但运维挑战仍然存在。Oren意识到他仍然需要出于各种原因访问生产主机,例如修补、调试故障、监控服务和提取日志。访问生产系统的原因变得太多,无法一一列举,导致了一种面条式的情况。
为了解决这些运维挑战,Banalux决定利用亚马逊云科技提供的构建块,旨在消除绝大多数直接访问生产系统的原因。
Oren强调了本次会议将探讨的四个主要亚马逊云科技构建块:
- Amazon CloudWatch:提供日志、指标、警报和仪表板。
- Amazon Systems Manager:无论节点是EC2实例还是内部系统,都能够实现大规模节点管理。
- Amazon Config:促进合规性。
- Amazon CloudTrail:虽然常被忽视作为运维工具,但CloudTrail可以提供有关更改和事件的宝贵见解,是调查的良好起点。
Oren强调,虽然这种设置非常强大,但仍需要一些手动监督,因为运维是一个持续改进的旅程。
Banalux采用交通信号灯系统来监控服务健康状况,绿色表示健康状态,黄色表示服务问题(服务仍在运行但出现异常),红色表示服务器宕机,客户无法访问他们的灯光。
在演示过程中,出现了问题,触发了黄色和红色警报,促使Oren进一步调查。
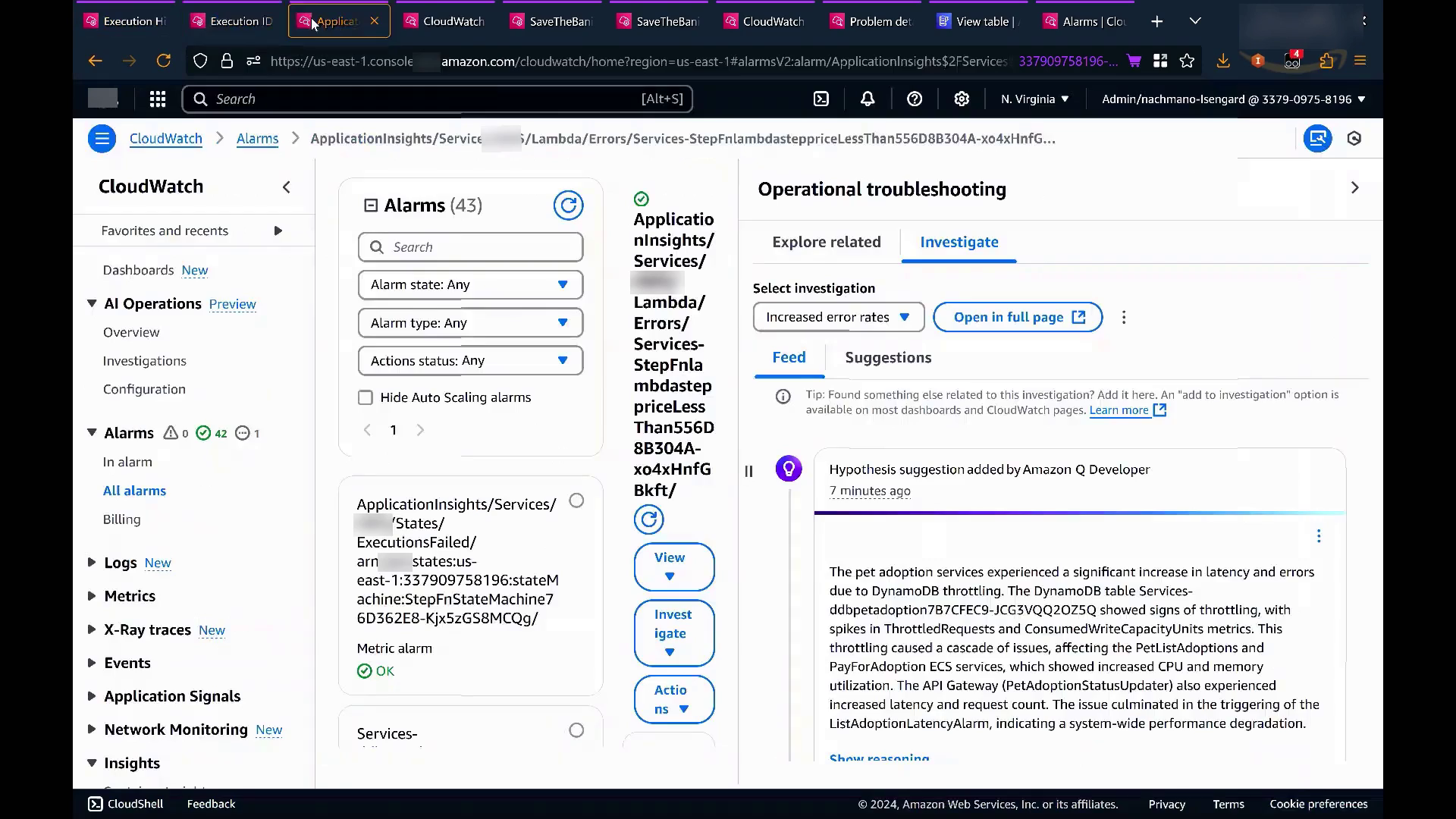
Oren调查问题的第一步是查看CloudWatch,因为这是生成警报的地方。他透露,他们勇敢地在us-east-1区域运行这部分演示,该区域在两天前刚刚推出了一项名为CloudWatch Observability的新功能。该功能基本上允许调试各种应用程序。
尽管CloudWatch仪表板显示一切正常运行,但Oren承认情况并非如此。他继续在CloudWatch Observability中创建一个调查,该功能允许将警报、指标和日志合并到一个位置,类似于其他亚马逊云科技产品中的动态仪表板或笔记本。
该调查笔记本可以在整个组织中共享,允许多个人同时与之交互。Oren演示了他如何拉取任何相关警报,例如检查当前在环境中处于活动状态的警报。他将其中一个警报添加到现有调查中,一个侧边栏出现,提供了从亚马逊云科技控制台的不同部分向调查添加各种组件的功能。
Oren随后在全屏模式下打开了调查,显示了他刚刚添加的指标,以及之前包含的其他元素。CloudWatch还自动识别并添加了来自日志的相关问题,并实时显示在调查中。
Oren可以选择接受或丢弃CloudWatch建议的添加内容。他还可以向调查添加自己的笔记和观察结果,促进多个人员就同一问题进行协作。笔记本会自动刷新,其内容可以使用Amazon Chatbot与Slack或Microsoft Teams等通信平台同步,从而可以直接从这些平台与调查进行交互。
Oren强调,即使没有活动警报,也可以基于直觉启动调查。这与传统流程形成对比,传统流程通常是在触发警报时才开始。调查功能允许主动探索潜在问题,而无需特定的警报条件。
如果最终调查没有发现重大问题,可以简单地关闭调查,从而放心。
在调查问题时,Oren注意到其中一个问题似乎与迁移有关,而另一个问题导致服务器离线,如红色交通灯所示。他承认需要及时调查和解决后一个问题。
Eric随后借此机会解决了黄色交通灯问题,该问题似乎与他之前所做的工作有关。他兴奋地分享了Banalux业务进一步扩展的消息,需要在他们的环境中添加更多节点。然而,这些新节点的状态不太适合由Amazon Systems Manager进行管理,从而阻碍了对操作系统进行补丁或收集信息的能力。
Eric导航到Systems Manager控制台的“Review New Insights”页面,该页面显示当前有153个实例处于未管理状态。为了解决这个问题,他启动了“Diagnose and Remediate”流程,该流程有助于识别EC2实例未注册到Systems Manager的原因,并将它们置于受管理状态。
“Diagnose and Remediate”功能可以帮助解决两种类型的问题:新Systems Manager体验的一般部署,以及未注册EC2实例的具体问题。Eric之前已经运行过诊断,因此他可以查看或下载诊断报告,该报告提供了一个CSV文件,列出了账户、区域和有关未管理EC2实例的基本信息。
除了识别未管理实例外,“Diagnose and Remediate”功能还可以帮助修复潜在问题。在这种情况下,报告显示所有153个实例都缺少VPC端点,这可能意味着它们缺少到公共互联网的路由或缺少代理。
为了解决这个问题,Eric可以启动一个运书,在相关账户和区域中部署所需的VPC端点,这些区域中存在未管理的实例。他可以选择先对特定账户或区域进行筛选和执行运书,然后再扩展到整个环境。
Eric导航到亚马逊云科技 Systems Manager Automation控制台,在那里他可以观察工作流在账户和区域中启动,评估托管未管理EC2实例的VPC,并为Systems Manager配置新的VPC端点。此过程旨在重新建立与受管理实例的连接,并将它们恢复到完全受管理状态。
在自动化工作流运行时,Eric解释说他本可以手动启动“Diagnose and Remediate”流程,但安排一个定期诊断会更加实际。这将确保持续监控未管理的EC2实例,并提供有关它们未受管理状态原因的见解。Eric演示了如何安排诊断每天或每周运行,指定开始时间并保存配置。
通过查看以前的诊断执行情况,Eric可以识别重复或不同的问题,并努力改进整体基础设施,从而最小化未管理实例的存在。
在解决了问题并且交通灯变为绿色后,Oren为最初舞台灯没有对与会者可见而造成的混乱表示歉意。他感谢Eric解决了黄色灯问题,使他们能够继续进行而不存在任何其他问题。
Oren随后强调了CloudWatch Observability中的两个额外功能。首先,他演示了调查笔记本如何在亚马逊云科技控制台中跟随他,提供调查详细信息的持久性侧边视图,包括假设和推理,无论他导航到哪个仪表板或服务。这一功能旨在减少多个选项卡或窗口的需求,提高生产力和便利性。
其次,Oren展示了在执行自动化之前预览其潜在影响的能力。此功能提供风险评估和自动化范围的摘要,详细说明它将影响的账户、区域和资源。它还分析了所涉及的步骤,将它们分类为变更(写操作)或非变更(读操作)。此预览允许用户验证自动化将按预期运行,避免意外后果或过度范围。
Oren强调,即使在凌晨2点,当操作问题经常出现时,了解自动化的潜在影响也是至关重要的,然后再执行它。此功能有助于确保自动化在预期范围内安全运行,而无需每次都进行耗时的代码审查。
随着会议接近尾声,Oren和Eric总结了三个关键要点:
- 认识规模并简化操作,使用诸如Amazon Systems Manager之类的服务,该服务能够跨账户和跨区域管理节点和资源池,无论它们是无服务器、基于服务器还是混合环境。
- 将人工智能、AI/ML或自定义智能引入调查,缩短解决时间,并利用数据和分析的力量。
- 尽可能自动化流程和操作,认识到自动化对于有效扩展和减少人工工作至关重要。
Oren重申,虽然这些服务和概念对于可能熟悉自动化重要性的与会者来说可能看起来很明显,但实现完全自动化实际上是一个持续的旅程,即使对于致力于构建自动化平台的团队也是如此。
会议最后提供了二维码,供与会者访问与所介绍的亚马逊云科技服务和体验相关的公告博客、视觉演示和动手实验。Oren和Eric感谢与会者的时间和参与,并表示会后可以继续讨论。
总之,亚马逊云科技 re:Invent 2024会议“Operating Your Fleet of Resources at Scale is Easier Than You Think”提供了有关利用亚马逊云科技服务简化和自动化大规模操作的宝贵见解和实际演示。会议强调了认识操作挑战、拥抱智能和自动化以及持续改进流程以实现跨混合云和本地环境的高效和可扩展资源管理的重要性。
下面是一些演讲现场的精彩瞬间:
Eric Webber是一位高级解决方案架构师专家,他介绍了自己的角色,即帮助客户在其环境中采用亚马逊云科技服务。

随着公司在多个亚马逊云科技账户和区域扩展业务,管理和运营资源变得更加困难,因此需要更好的解决方案。

演讲者以幽默的方式介绍了“Stikfiger先生”,回忆起早期为他们的初创公司Vannalux手动部署代码和管理服务器的日子。

他强调了随着应用程序跨本地和云基础设施扩展,管理生产环境的挑战。

亚马逊云科技传播者强调了CloudTrail作为审计工具的重要性,尽管常被忽视,但对于运营洞察和故障排除至关重要。

亚马逊云科技云专家演示了如何在亚马逊云科技云中跨不同仪表板进行调查,从而实现无需多个选项卡的无缝故障排除。
总结
在这场生动有趣的演讲中,来自亚马逊云科技的Oren和Eric带领观众探索了大规模运营和管理资源的挑战。他们引入了一家假想的香蕉主题照明公司Bandalux,用以说明随着企业的发展和跨本地与云环境的扩张,运营复杂性是如何演变的。
通过Bandalux的故事,他们强调了自动化在简化运营和高效扩展方面的重要性。他们强调,在基础设施增长之初就应该自动化重复性任务,因为随着基础设施的增长,自动化的成本会越来越高。CloudWatch、Systems Manager、Amazon Config和CloudTrail等亚马逊云科技服务被展示为强大的工具,可以简化运营,提供洞察力、节点管理、合规性跟踪和审计功能。
演讲者展示了全新的Systems Manager体验,演示了如何跨账户和区域汇总托管和非托管实例的信息,从而实现高效诊断和修复。他们还介绍了CloudWatch Investigations功能,该功能允许协作故障排查,利用人工智能驱动的洞察力、假设和建议的运行手册,以加快解决问题的速度。
贯穿整个演讲,Oren和Eric强调了认识规模、简化运营、融入智能(人工或人工智能驱动)以及自动化流程对于实现运营卓越的重要性。他们鼓励与会者探索提供的资源,包括博客、演示和动手实践研讨会,体验亚马逊云科技服务在大规模管理资源方面的强大功能。
关键要点是在大规模运营中简化流程、利用智能缩短调查时间,以及自动化流程以实现运营效率,无论基础设施的规模或复杂程度如何。演讲者生动的讲述和现场演示使这些概念对与会者来说更加贴近实际、可操作。
亚马逊云科技(Amazon Web Services)是全球云计算的开创者和引领者。提供200多类广泛而深入的云服务,服务全球245个国家和地区的数百万客户。做为全球生成式AI前行者,亚马逊云科技正在携手广泛的客户和合作伙伴,缔造可见的商业价值 – 汇集全球40余款大模型,亚马逊云科技为10万家全球企业提供AI及机器学习服务,守护3/4中国企业出海。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









