







观看教程
ytb 视频:https://youtu.be/AbB33AxrcZo
快速开始Quick Start
- 下载一个 checkpoint 文件。可能是 Stable Diffusion v1.5。将文件放在
ComfyUI/models/checkpoints之下。 - 刷新 ComfyUI。
- 点击
Load Default按钮 使用默认工作流程。 - 在
Load Checkpoint节点中,选择你刚刚下载的检查点文件。 - 点击
Queue Prompt并观看你的图像生成。通过调整提示来生成不同的图像。
概述
什么是自定义节点?
Comfy 的一个强大之处在于其基于节点的架构允许你通过以不同的方式连接提供的节点来开发新的工作流程。内置的节点提供了一系列的功能,但你可能会发现你需要一个核心节点没有提供的功能。
自定义节点允许你实现新功能,并与更广泛的社区分享。
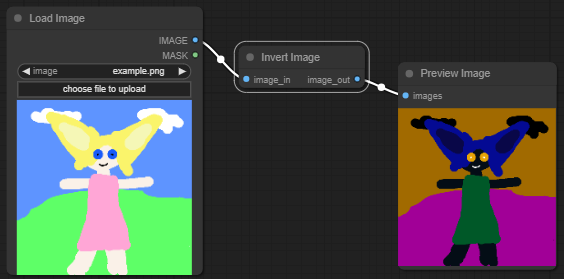
自定义节点,就像任何 Comfy 节点一样,本质上接收输入,对其进行一些操作,然后产生输出。虽然一些自定义节点执行高度复杂的任务,但许多只是做一件事情。这里有一个简单节点的例子,它接收一个图像并将其反转。
客户端-服务器模型
Comfy采用客户端-服务器模型运行。服务器由Python编写,处理所有实际工作:数据处理、模型、图像扩散等。客户端由JavaScript编写,处理用户界面。
Comfy还可以以API模式使用,此时非Comfy客户端(例如另一个UI或命令行脚本)将工作流程发送到服务器。
自定义节点可以放入四个类别之一:
仅服务器端
大多数自定义节点仅运行在服务器端,通过定义一个Python类来指定输入和输出类型,并提供一个可以被调用来处理输入并生成输出的函数。
仅客户端
一些自定义节点提供对客户端UI的修改,但不会添加核心功能。尽管名称如此,
它们甚至可能不会向系统中添加新节点。
独立客户端和服务器
自定义节点可能提供额外的服务器功能以及额外的(相关)UI功能(例如处理新数据类型的新小部件)。在大多数情况下,客户端和服务器之间的通信可以通过Comfy数据流控制来处理。
连接客户端和服务器
在少数情况下,UI功能和服务需要直接相互交互。
任何需要客户端-服务器通信的节点都将无法通过使用API兼容。


















 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









