







文章目录
在人工智能领域,强化学习(RL)与大语言模型(LLM)的结合正成为一个热门话题。本文将深入探讨如何在o1模型中将RL与LLM融合,并构建一个复杂的逻辑推理系统。我们将从RL的关键要素入手,分析其在Hidden COT场景下的应用,并探讨AlphaGo/AlphaZero的工作原理如何为此提供借鉴。
一、RL与LLM融合的背景与意义
1.1 时代的呼唤:AI技术的深度融合
随着人工智能技术的不断发展,单一的AI技术已无法满足复杂应用场景的需求。RL与LLM的结合,旨在通过强化学习的决策能力与大语言模型的语言理解能力,构建一个更为智能的系统,能够在复杂环境中进行逻辑推理和决策。
1.2 独特的视角:从AlphaGo到o1
AlphaGo的成功为AI技术的融合提供了一个经典案例。其采用的蒙特卡洛树搜索(MCST)方法,结合深度学习,展示了AI在复杂决策中的潜力。o1模型的研发团队也在尝试将这种成功经验应用于LLM的开发中,以期实现更高效的逻辑推理。
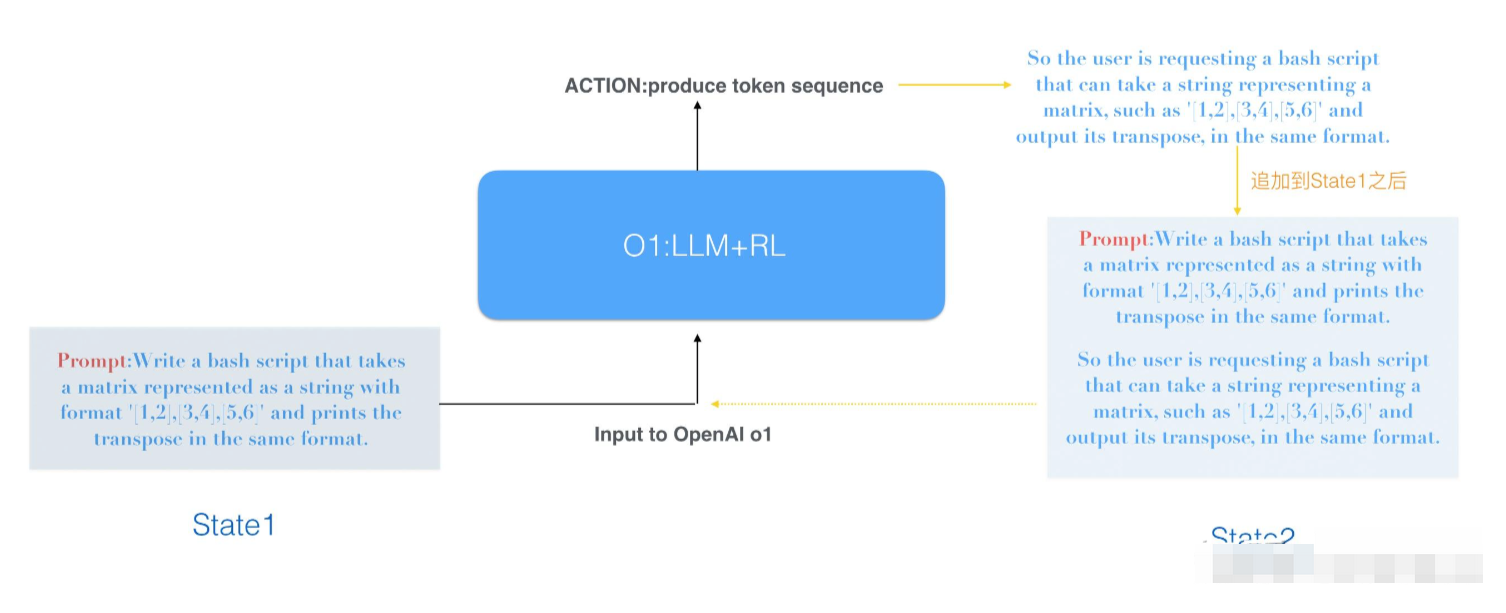
二、RL的关键要素在Hidden COT场景下的应用
2.1 状态空间(State Space)
在o1模型中,状态空间由Token序列组成的连续状态空间构成。每当用户输入问题时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









