







【机器学习|学习笔记】核极限学习机(Kernel extreme learning machine ,KELM )详解,附代码。
【机器学习|学习笔记】核极限学习机(Kernel extreme learning machine ,KELM )详解,附代码。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/147567533
前言
- KELM 是将核方法引入极限学习机(ELM)的一种变体,通过在隐藏层输出空间上构造核 Gram 矩阵,避免随机映射导致的不稳定性,从而提升模型的泛化能力与稳定性;
- 它自 2010 年左右提出后,迅速在分类、回归、工程预测及域适应等领域得到推广,并衍生出多种优化算法(如 CG‑KELM、KELM‑GWO、KELM‑DTF‑IS 等),当前常用于小样本、高维及跨域场景。
- KELM 的核心在于用核函数替代随机隐藏节点映射,输出权重可通过闭式解(正则化最小二乘)快速获得;
- 其计算复杂度主要来自于对 N × N N×N N×N 核矩阵的求逆或分解,因此适合中小规模数据。
下面将逐层展开。
起源
- 极限学习机(ELM)由黄广斌等人于 2004 年左右提出,作为单隐层前馈网络(SLFN)的快速训练算法,其随机生成隐藏层参数,仅学习输出权重,并以最小二乘闭式解显著加速训练过程 。
- 为提升 ELM 在小样本或高噪声场景下的稳定性和泛化性能,研究者于 2010 年左右将核方法引入 ELM,提出 Kernel ELM(KELM),即用核函数 K ( x i , x j ) K(x_i,x_j) K(xi,xj) 构造隐藏层输出的 Gram 矩阵,避免显式随机映射的波动影响 。
- 此后,KELM 被视为结合了 ELM 随机映射优势与核方法非线性建模能力的统一框架,为后续改进和变体研究奠定了基础。
发展
- CG‑KELM:针对 KELM 中惩罚参数随机设置的问题,引入共轭梯度迭代法计算输出权重,避免对核矩阵求逆并消除惩罚超参对性能的敏感性 。
- KELM‑GWO:将灰狼优化算法(Grey Wolf Optimizer)与 KELM 结合,用进化算法自动寻找最优核参数和正则化系数,在岩石抗压强度预测等工程领域取得领先效果。
- 深度核 ELM:通过分层或多核结构(如多层余弦核、arc‑cosine 核)构建深度 KELM,提高对复杂模式的表达能力 。
- 域适应 KELM(KELM‑DTF‑IS 等):在无监督/半监督跨域场景中,结合判别特征提取与实例选择策略,增强模型在目标域的迁移能力
原理
核化 SLFN
- 给定训练集 ( x i , t i ) N i = 1 {(x_i,t_i)}^{i=1}_N (xi,ti)Ni=1,ELM 隐藏层映射记为 h ( x ) h(x) h(x);KELM 用核函数直接计算隐藏层输出 Gram 矩阵 Ω ∈ R N × N Ω∈R^{N×N} Ω∈RN×N。
- KELM 的正则化最小二乘目标可写为

预测
- 对新样本
x
x
x 的预测为
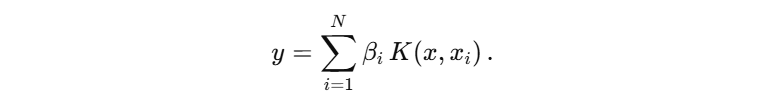
核函数选择
- 常用 Gaussian RBF、Polynomial、Sigmoid 等核;核宽、阶数等超参影响模型非线性表达及过拟合程度。
应用
- 气象预测:用 KELM 估计日均露点温度,表现优于传统回归模型
- 岩石力学:KELM‑GWO 用于预测岩石单轴抗压强度,自动优化核与正则化参数
- 环境工程:KELM 与 Kriging 联合预测重金属吸附效率,提升了预测精度
- 生物信息:基因表达数据分类与特征选择,KELM 在小样本高维下稳定性优于 SVM
- 域适应:KELM‑DTF‑IS 用于无监督域自适应任务,实现跨域特征提取与分类
- 医学诊断:基于 KELM 的心力衰竭预测模型,利用核映射提高对异常样本的识别能力
Python 代码实现
下面给出一个基于 NumPy 的简易 KELM 实现,并在 Iris 数据集上演示分类流程。
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from scipy.linalg import pinv
# ———— 核函数定义 ————
def rbf_kernel(X1, X2, gamma):
# Gaussian RBF 核
sqd = np.sum(X1**2, axis=1)[:,None] + np.sum(X2**2, axis=1)[None,:] - 2*X1.dot(X2.T)
return np.exp(-gamma * sqd)
# ———— KELM 类 ————
class KELM:
def __init__(self, C=1.0, kernel='rbf', gamma=1.0):
self.C = C
self.kernel = kernel
self.gamma = gamma
def fit(self, X, T):
# X: (N, d), T: (N, n_classes) one-hot
self.X_train = X
# 计算核矩阵 Ω
Ω = rbf_kernel(X, X, self.gamma)
# 求解 β = (Ω + I/C)^(-1) T
N = Ω.shape[0]
self.beta = np.linalg.solve(Ω + np.eye(N)/self.C, T)
def predict(self, X):
# 预测, 返回 class index
Ω_test = rbf_kernel(X, self.X_train, self.gamma)
Y = Ω_test.dot(self.beta)
return np.argmax(Y, axis=1)
# ———— 演示 ————
iris = datasets.load_iris()
X = iris.data; y = iris.target.reshape(-1,1)
# one-hot 编码
enc = OneHotEncoder(sparse=False).fit(y)
T = enc.transform(y)
X_train, X_test, T_train, y_test = train_test_split(X, T, test_size=0.3, random_state=42)
model = KELM(C=10.0, gamma=0.5)
model.fit(X_train, T_train)
y_pred = model.predict(X_test)
acc = np.mean(y_pred == y_test.flatten())
print(f"Iris 测试集分类准确率: {acc:.4f}")
- 以上代码中,核心在于用 RBF 核构造训练样本间的 Gram 矩阵,并通过正则化最小二乘闭式解获得输出权重,预测时再计算测试样本与训练样本间的核值并加权输出;可灵活替换核函数及超参数。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











