







【机器学习|评价指标1】真正例(True Positive)、假正例(False Positive)、真负例(True Negative)、假负例(False Negative)详解,附代码。
【机器学习|评价指标1】真正例(True Positive)、假正例(False Positive)、真负例(True Negative)、假负例(False Negative)详解,附代码。
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可关注VX “
学术会议小灵通”或参考学术信息专栏:https://blog.csdn.net/2401_89898861/article/details/147776758
前言
在机器学习的分类任务中,混淆矩阵(Confusion Matrix) 是一种用于评估模型性能的工具,特别适用于二分类问题。混淆矩阵通过比较模型的预测结果与实际标签,统计出以下四种情况:
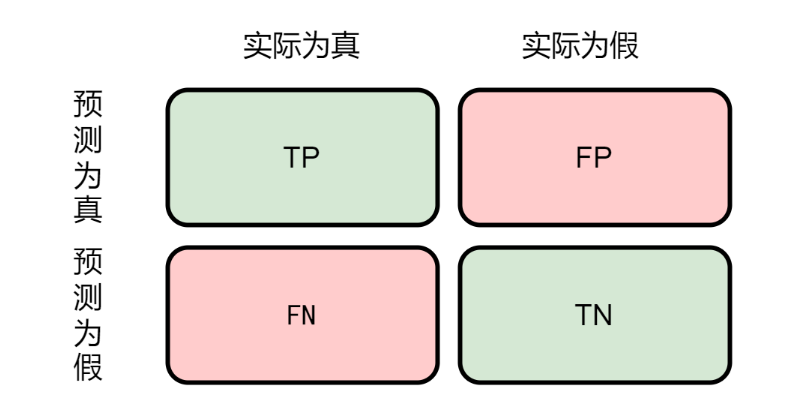
- 真正例(True Positive, TP):模型正确地将正类样本预测为正类。
- 假正例(False Positive, FP):模型错误地将负类样本预测为正类。
- 真负例(True Negative, TN):模型正确地将负类样本预测为负类。
- 假负例(False Negative, FN):模型错误地将正类样本预测为负类。
这些统计量可以帮助我们计算多种性能指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)等。
以下是一个使用 Python 计算混淆矩阵及其各项指标的示例代码:
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
# 假设的真实标签和预测标签
y_true = [0, 1, 1, 0, 1, 0, 1, 0]
y_pred = [0, 1, 0, 0, 1, 1, 1, 0]
# 计算混淆矩阵
tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
# 输出各项指标
print(f"真正例 (TP): {tp}")
print(f"假正例 (FP): {fp}")
print(f"真负例 (TN): {tn}")
print(f"假负例 (FN): {fn}")
# 计算性能指标
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"准确率 (Accuracy): {accuracy:.2f}")
print(f"精确率 (Precision): {precision:.2f}")
print(f"召回率 (Recall): {recall:.2f}")
print(f"F1 分数 (F1 Score): {f1:.2f}")
- 运行上述代码将输出混淆矩阵的各项值以及模型的性能指标,帮助我们全面评估分类模型的表现。
- 需要注意的是,准确率在类别不平衡的数据集上可能会产生误导,因此在这种情况下,更应关注精确率、召回率和F1分数等指标。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











