






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、栈的定义:
堆栈又名栈(stack),它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
栈的存储
由于栈其实是一种特殊的线性表,于是栈也有顺序存储和链式存储两种实现方式。
二、顺序栈
存储方式:同一般线性表的顺序存储结构完全相同,利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素。栈底一般在低地址段。
设top指针,指示栈顶元素在顺序栈中的位置
设base指针,指示栈底元素在顺序栈中的位置
用stack size表示栈可用的最大容量
//但是,为了方便操作,通常指针指向真正栈顶元素之上的下标地址。
2.顺序栈的表示
1.空栈
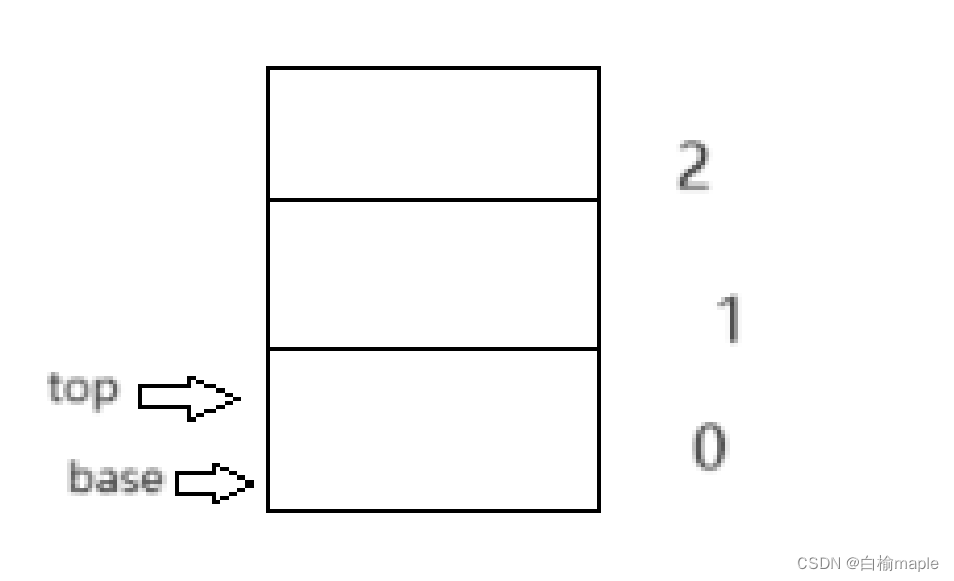
//base==top 是空栈表示
2.进栈
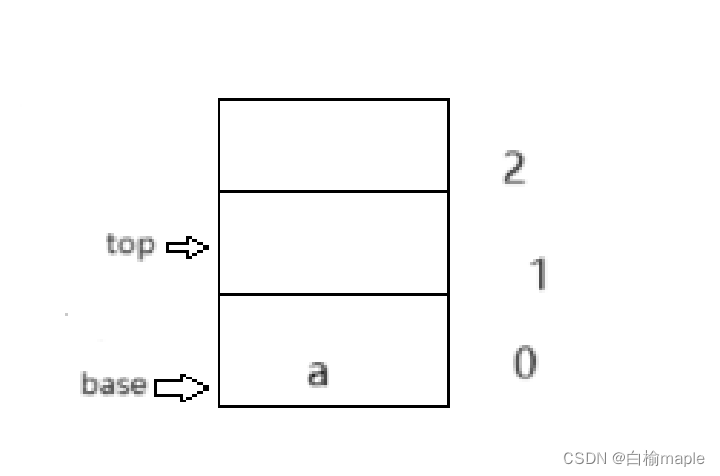
3.栈满
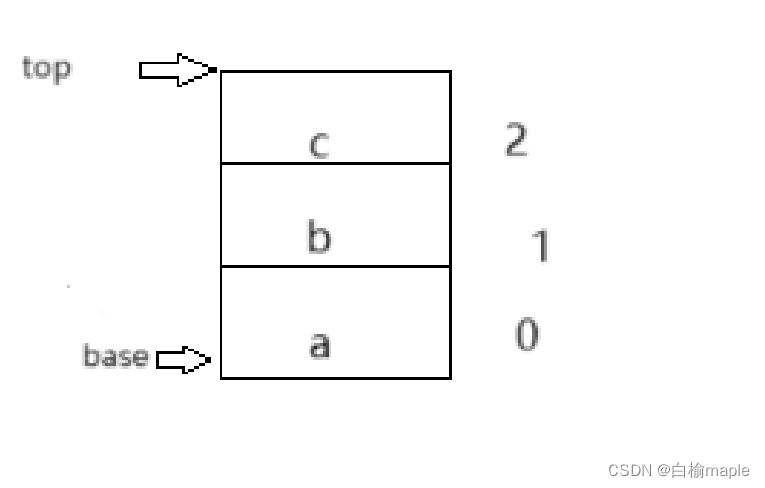
//top-base == stack size 是栈满表示
4.栈满的处理方法
1。报错,返回操作系统
2.分配更大空间,作为栈的存储空间,将原栈的内容移入新栈.
三、链栈
//链栈是运算受限的单链表,只能在链表头部进行操作。
1.链栈的表现
1.链表的头指针就是栈顶。
2.不需要头结点。
3.基本不存在栈满的情况
4.空栈相当于头指针向空
5.插入和删除仅在栈顶处执行
2.链栈的初始化
void initStack(LinkStack &S ) //构造一个空栈,栈顶指针置为空
{
S=NULL;
return OK;
}
3.判断链栈是否为空
Status StackEmpty(LinkStack S)
if (S==NULL) return TRUE;
else return FALSE;
}
4.链栈的入栈
Status Push(LinkStack &S ,SElemType e)
{
p=new StackNode; //生成新结点
p->data=e; //将新结点数据域置为
p->next=S;//将新结点插入栈顶
S=p;//修改栈顶指针
return OK;
}
5.链栈的出栈
Status Pop (LinkStack &S,SElemType &e)
{
if (S==NULL) return ERROR;
e= S-> data;
p=S;
S= S->next;
delete p;
return OK;
}
总结
感谢各位的认真阅读,如果感觉以上内容对大家的学习有所帮助的话,希望大家可以点赞支持一下,谢谢大家!















 2081
2081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









