






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
目录
前言
要理解一个C程序,仅仅理解组成该程序的符号是不够的。程序员还必须理解这些符号是如何组合成声明、表达式、语句和程序的。本章将讨论一些用法和意义与我们想当然的认识不一致的语法结构
一、理解函数声明
我们可以通过语句来理解函数声明,我们得到的语句如下:
1.(*(void(*)( ))0)( );
任何C变量的声明都由两部分组成:类型以及一组类似表达式的声明符。声明符和表达式有些类似,最简单的声明符就是单个变量。
float f, g;
这个声明的含义是:当对其求值时,表达式f和g的类型为浮点数类型(float )。因为声明符与表达式的相似,所以我们也可以在声明符中任意使用括号:
float ((f));
这个声明的含义是:当对其求值时,((f))的类型为浮点类型,由此可以推知,f也是浮点类型。
float ff();
这个声明的含义是:表达式ff()求值结果是一个浮点数,也就是说,ff是一个返回值为浮点类型的函数。
float * pf;
这个声明的含义是*pf是一个浮点数,也就是说,pf是一个指向浮点数的指针。
以上这些形式在声明中还可以组合起来:
float * g(),(*h)();
表示*g()与(*h)()是浮点表达式。因为()结合优先级高于*,*g()也就是*(g()): g是一个函数,该函数的返回值类型为指向浮点数的指针。
fIoat (*h)()
表示h是一个指向返回值为浮点类型的函数的指针,
(float ( *)())
表示一个“指向返回值为浮点类型的函数的指针”的类型转换符。
2.signal 函数接受两个参数:
一个整型的信号编号,以及一个指向用户定义的信号处理函数的指针
3.使用typedef 简化函数声明:
void (*sfp)(int):
使用typedef 可以简化上面的函数声明:
typedef void * HANDLER)(int):
HANDLER signal( int, hANDLER);
二、运算符的优先级问题
假设存在一个已定义的常量FLAG,FLAG是一个整数,且该整数值的二进制表示中只有某一位是1,其余各位均为0,亦即该整数是2的某次幂。如果对于整型变量flags ,我们需要判断它在常量FLAG为1的那一位上是否同样也为1,
1.if (flags FLAG)
if语句判断括号内表达式的值是否为0。考虑到可读性,如果对表达式的值是否为0的判断能够显式地加以说明,使得代码起到了注释该段代码的作用。其写法如下,
if (flags & FLAG != 0)
这个语句现在虽然更好懂了,但却是一个错误的语句。因为!=运算符的优先级要高于&运算符,所以上式实际上被解释为:
if (flags (FLAG != 0))
因此,除了FLAG恰好为1的情形,FLAG为其他数时这个式子都是错误的。
又假设hi和low是两个整数,它们的值介于0到15之间,如果r是一个8位整数,且r的低4位与low各位上的数一致,而r的高4位与hi各位上的数一致。很自然会想到要这样写:
2.r= his << 4 + low:
但是很不幸,这样写是错误的。加法运算的优先级要比移位运算的优先级高,实际上相当于:
r= hi<< ( 4+ 1ow)
对于这种情况,有两种更正方法:
第一种方法是加括号;
第二种方法意识到问题出在程序员混淆了算术运算与逻辑运算,但这种方法牵涉到的移位运算与逻辑运算的相对优先级就更加不是那么明显。两种方法如下:
r=(hi<<4)+low; //法1:加括号
r= hi<< 4 | low; //法2:将原来的加号改为按位逻辑或
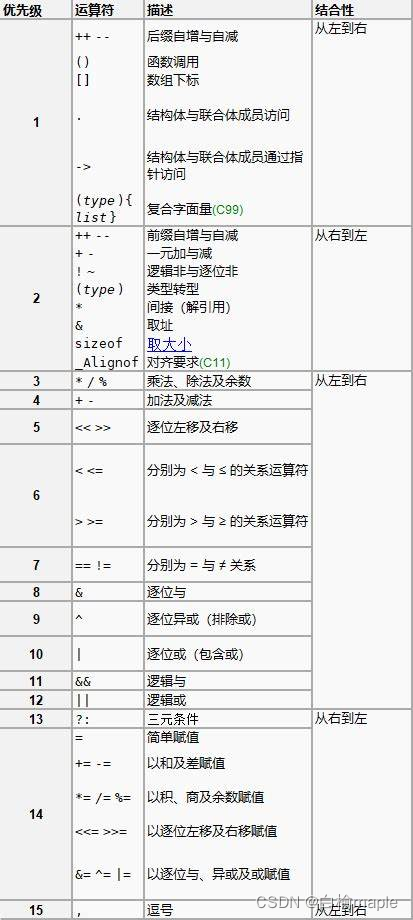
用添加括号的方法虽然可以完全避免这类问题,但是表达式中有了太多的括号反而不容易理解。因此,记住C语言中运算符的优先级是有益的。
C语言运算符优先表
三、注意作为语句结束标志的分号
1.多写分号的影响
在C程序中如果不小心多写了一个分号可能不会造成什么不良后果:
1.这个分号也许会被视作一个不会产生任何实际效果的空语句;
2.编译器会因为这个多余的分号而产生一条警告信息,根据警告信息的提示能够很容易去掉这个分号。
在if或者while 子句之后的语句就是一条单独的语句,与条件判断部分没有了任何关系。例如:
if (x[i]>big);
big= x[i];
编译器会正常地接受第一行代码中的分号而不会提示任何警告信息
面这段代码的处理就大不相同:
if (x[i]>big)
big=x[i];
前面第一个例子(即在if后多加了一个分号的例子)实际上相当于
if (x[i]>big){}
big= x[i];
当然,也就等同于(除非x、I或者big是有副作用的宏)
big=x[i];
2.少写分号的影响
如果不是多写了一个分号,而是遗漏了一个分号,同样会招致麻烦。例如:
if(n<3)
return
logrec. date = x[o];
logrec. time = x[1];
logrec. code = x[2]:
此处的return 语句后面遗漏了一个分号;然而这段程序代码仍然会顺利通过
编译而不会报错,只是将语句
logrec. date x[o]
当作了return 语句的操作数。上面这段程序代码实际上相当于:
if(n<3)
return logrec. date = x[o];
logrec. time = x[1];
logrec. code = x[2];
如果这段代码所在的函数声明其返回值为void,编译器会因为实际返回值的类型与声明返回值的类型不一致而报错。
3.分号被省略
声明的结尾紧跟一个函数定义如果声明结尾的分号被省略,编译器可能会把声明的类型视作函数的返回值类型。
struct logreci {
int date;
int time:
int code;
}
main(
{
}
上面代码段实际的效果是声明函数main的返回值是结构logrec 类型。
struct logreci {
int date:
int time;
int code;
}
main()
{
}
如果分号没有被省略,函数main的返回值类型会缺省定义为int类型。
四、悬挂”else引发的问题
if(x==0)
if (y == 0) error();
else{
z=x + y:
f(&z);
}
原因在于C语言中有这样的规则,对于x不等于0的情形,程序首先将x与y之和赋值给z,然后以z的地址为参数来调用函数f。
else始终与同一对括号内最近的未匹配的if结合。程序实际上是这个样子的。
f(x==0){
if(y==0)
error();
else{
z = x + y;
f(&z);
}
}
现在,else与第一个if结合,即使它离第二个if更近也是如此,因为此时第二个if已经被括号“封装”起来了。
也就是说,如果x不等于0,程序将不会做任何处理。所以正确的应该这样写:
if x = 0
then if y = 0
then error
fi
else
e: = x + y;
f(z)
fi
像上面这样强制使用收尾定界符完全避免了“悬挂”else的问题,付出的代价则是程序稍稍变长了一点。
有些C程序员通过使用宏定义也能达到类似的效果:
# define IF { if {
# define THEN ) {
# define ELSE ) else {
# define FI }}
上例C语言可以写成:
IF x == 0
THEN IF y == 0
THEN error ();
FI
else
z = x + y;
f(&z);
FI















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









