







摘 要
近年来,随着人工智能技术的发展,为垃圾分类的智能化分拣提供了技术路径,其中深度学习的卷积神经网络尤为突出。卷积神经网络模型首次凭借较快的训练速度、更高的模型准确率获得了2012年ImageNet竞赛冠军;之后于2019年阿里云成功训练出垃圾分类的神经网络模型在手机淘宝上线,为垃圾图像分类的智能化发展提供了良好的环境。
本课题主要对深度残差网络(Deep Residual Network)、卷积神经网络(Convolutional Neural Networks)进行对比研究,选择适合的深度学习算法并进行改进,同时使用Python语言实现系统,然后对垃圾图片数据集进行训练,并对数据集进行测试,提高垃圾分类准确率。
改进后的基于空间注意力的ResNet50网络模型在进行垃圾图像分类的实验中成本低、效率高以及更加智能化,为垃圾图像分类研究奠定基础、为垃圾分类系统提供图像分类识别的支持。
关键词:垃圾图像分类;空间注意力;深度学习;深度残差网络
ABSTRACT
For the past few years, with the rapid development of artificial intelligence technology, a technical path has been provided for the intelligent sorting of garbage, among which the convolutional neural network of deep learning is particularly prominent. The convolutional neural network model won the 2012 ImageNet competition championship for the first time with a faster training speed and higher model accuracy; afterwards, in 2019, Alibaba Cloud successfully trained a neural network model for garbage classification and launched it on Taobao on mobile, which is garbage The intelligent development of image classification provides a good environment.
This topic mainly compares deep residual networks (Deep Residual Network) and convolutional neural networks (Convolutional Neural Networks), selects suitable deep learning algorithms and makes improvements, and uses Python language to implement the system, and then analyzes the garbage image data set Train and test the data set to greatly improve the accuracy of garbage classification.
The improved ResNet50 network model based on spatial attention is low-cost, high-efficiency and more intelligent in the experiments of garbage image classification, laying a foundation for garbage image classification research and providing support for image classification and recognition for garbage classification systems.
Key Words: Garbage image classification; Spatial attention mechanism; Deep learning; ResNet
目 录
1 绪论
1.1研究背景及意义
1.2国内外研究现状与发展趋势
2 垃圾图像分类相关技术与理论基础
2.1卷积神经网络模型
2.2 VGG网络模型
2.3 ResNet网络模型
2.4注意力模型
3 基于注意力模型的垃圾图像分类算法
3.1模型总体架构
3.2空间注意力模型
4 算法仿真和结果分析
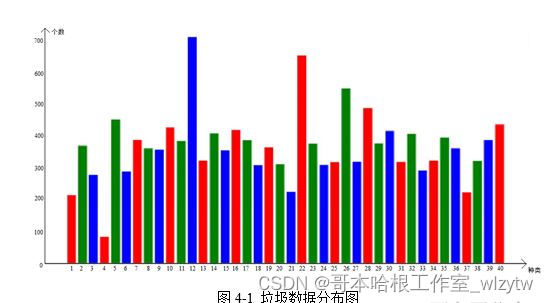
4.1数据预处理
4.1.1垃圾分类图像数据集
4.1.2数据增强
4.1.3仿真设置
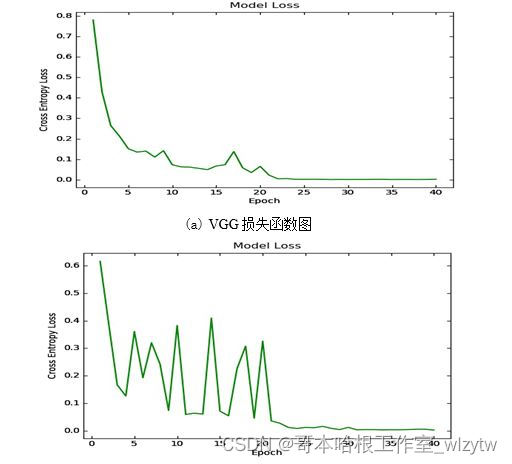
4.2对比仿真
4.3仿真结果可视化
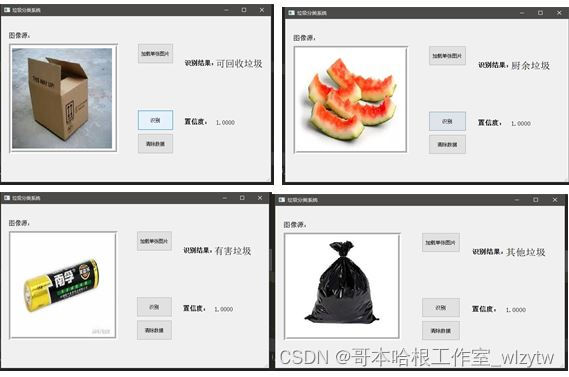
5 垃圾图像分类系统的设计与实现
5.1系统概述
5.2垃圾图像分类系统实现
6 结论
参考文献
附录1 ResNet50-att网络模型搭建核心代码
附录2 ResNet50-att网络模型训练核心代码
附录3 注意力机制核心代码
附录4 系统主界面核心代码
附录4.1main.py代码
附录4.2myUI.py代码
致 谢
1 绪 论
1.1研究背景及意义
随着我国生产力水平的稳步上升,人民的生活水准也越来越高,人们在生产与生活中会产生大量的垃圾[1],垃圾的随意堆积会对环境造成污染,最终影响人类的日常生活,这使得垃圾处理变得尤为重要。解决该问题的一个有效的处理方法是利用人工智能技术和计算机视觉技术对垃圾进行自动化分拣,实现垃圾的智能分类和自动回收。实现垃圾的智能分拣首先需要一双能够识别垃圾种类的“眼睛”—即应用计算机视觉技术[2]。目前针对垃圾分类也出现了语音、文字识别,特别是随着深度学习技术在视觉领域的应用和发展,利用AI来自动判断垃圾图像分类成为可能,在深度学习算法下进行垃圾图像识别便成为了计算视觉未来的一种应用趋势。同时,我校一项国家大创项目需要完成对垃圾图像分类的功能,拟采用比较成熟的API,比如聚合数据、天行数据、京东AI等成熟API,因其垃圾分类算法研究和应用已取得成效,但使用其API开发系统需要缴纳高额费用。
基于此,为实现对垃圾的智能分拣、自动分类,提出基于深度学习的垃圾图像分类识别系统设计与实现。具体而言,本文首先通过摄像头获取垃圾图像,然后通过设计基于注意力模型的ResNet50网络对垃圾图像执行分类。最后,通过在实验中与VGG16[3]、ResNet50[4]的对比进一步证明本文方法在垃圾分拣分类上的有效性。
1.2国内外研究现状与发展趋势
图像分类是计算机视觉中的一个基本研究领域,它可以将图像分类定义为若干个类别[5]。在图像的分类任务中,首先对图像使用特征提取器进行特征提取,然后对提取到的特征进行分类。传统的特征提取的方式又分为基于全局特征的方法(如纹理特征、形状特征、颜色特征等)和基于局部特征的方法(如LBP特征、SIFT特征、SURT特征等)[6]。
传统的特征分类方法则更多的是使用机器学习[7-8]的方式,主要执行二分类或者多分类。1964年Vapnik等人提出支持向量机(Support Vector Machine,SVM)方法[9],该算法基于优化理论处理机器学习任务。SVM为线性可分离问题和非线性可分离问题提供了不同的处理方法,之后1992年Vapnik等人使用核方法求解非线性SVM,增加了SVM的求解速度;另一种常用的分类方法是K最近邻算法[10](K-Nearest Neighbors, KNN),其要分割的样本的类别是根据最接近的一个或几个样本的类别而确定,KNN由于其高效和简单的实现而被广泛用于图像分类和预测。而基于逻辑回归函数的Softmax分类函数[11]常常应用于多分类任务中。
然而,传统的图像识别技术一般是针对某一特定的识别任务,且数据量不大,泛化能力较差,在实际应用中很难达到准确的识别效果。而深度学习其自身复杂的网络结构与强大的特征学习和表达能力,在计算机视觉领域的许多大规模识别任务中都取得了令人瞩目的成就。在2012年的ImageNet图像分类竞赛中,Alex Krizhevsky等人[12]首次提出AlexNet卷积神经网络,将深度学习应用于大规模图像分类。
现有的大部分垃圾图像分类算法由国外科研工作者提出,以垃圾分类数据集TrashNet[13]为例,2018年Kennedy Tom等人提出了OscarNet网络(由vgg19进行微调),实现了88.42%的分类精度。2018年Bernardo S.Costa等人提出了精度为91%的微调AlexNet网络和精度为93%的微调VGG16网络。2018年Rahmi Arda Aral等人[14]在垃圾网数据集上测试了多个经典网络,他们使用Inception Resnet V2实现了89%的准确率,使用DenseNet121实现了89%的准确率。2019年Victoria Ruiz等人使用ResNet网络的准确率达到了88.66%。这些方法基于经典网络,在大规模垃圾图像分类中表现突出,为垃圾图像识别提供了可行的算法。
在垃圾图像分类算法研究上,国内也取得了很多的进展,刘雅璇等人[15]提出一种基于自我训练的长效生活垃圾分类方法,该方法将 K 近邻分类器和支持向量机进行有机组合为集成分类器,通过用户使用意见反馈实现了对生活垃圾分类;且随着近年来人工智能技术的发展为垃圾分类的智能化分拣提供了技术路径,尤以卷积神经网络最受关注,黄国维[16]一种基于卷积神经网络的垃圾智能分类算法,对卷积神经网络模型中的后三层结构进行了调整,采用迁移学习方式,实现了速度更快、准确度更高的垃圾自动分类,在2019年阿里云成功训练出垃圾分类的神经网络模型(测试版)并在手机淘宝上线;同年,阿里云天池平台数据竞赛上线了垃圾分类检测项目,该项目吸引了全球多支团队报名进行比赛,为垃圾分类的智能化发展提供了良好的环境。
2 垃圾图像分类相关技术与理论基础
近年来,随着人工智能技术的发展,卷积神经网络模型凭借其较快的训练速度、更高的模型准确率成为当前深度学习主流研究方向之一,在计算机视觉领域被广泛应用。卷积神经网络结构上主要包括卷积层、池化层和全连接层等结构的前馈神经网络,能使网络结构学习并提取相关特征,此功能为研究提供了便利,优化了对复杂建模过程的需要。本章主要介绍卷积神经网络模型、VGG16模型、ResNet50模型以及注意力模型[17]的相关概念。
2.1卷积神经网络模型
深度学习[18-19]作为机器学习的一个分支,使用算法来处理信息和模拟思维过程,与传统的特征提取算法相比,深度学习技术提取的深度特征具有更强的表达能力与辨别力。
图2-1 算法流程
卷积神经网络(Convolutional Neural Networks,CNN)是一类包含卷积计算的深度学习算法,其算法流程如图2-1所示,其主要由卷积层、池化层、全连接层、激活层和归一化层组成。卷积层通常作为特征提取器,用于学习输入图像的特征表示,通过卷积操作,可以获取图像的深层特征映射;池化层用于降低特征图的空间分辨率,具有旋转不变性和平移不变性,提高网络的表达能力,能够有效的抑制模型的退化。在卷积层和池化层之后,通常使用全连接层加Softmax激活函数或者Sigmoid激活函数来对这些特征表示进行分类。激活层通常使用ReLu函数,将输入压缩到一个范围,用于避免梯度弥散或梯度消失现象。
卷积神经网络通常将上述多个层进行叠加,提取特征的同时对目标进行分类,得到输出的垃圾图像的分类概率,其训练过程如图2-2所示。对于给定的输入图像,首先累加多个层组成CNN网络,初始化该网络的权重,然后将图像输入至CNN网络中,计算其损失值,最后使用梯度下降算法,将损失值反向传播,更新CNN的参数。迭代执行以上步骤,则能够获取最终的网络模型,达到对垃圾图像分类的目的。
图2-2 CNN的训练过程
2.2 VGG网络模型
VGG模型由牛津大学计算机视觉组(Visual Geometry Group)于2014年提出,该网络在2014年ImageNet图像分类定位挑战赛中获得分类任务的第二名和定位任务的第一名,以优异的性能而闻名。VGG网络根据卷积核的大小可分为六种结构。其中,广泛使用的是VGG16和VGG19。VGG16 网络模型是基于大量真实图像的 ImageNet 图像库预训练的网络,VGG16网络模型简化了神经网络结构,随着网络层数的加深可以提升网络的性能,但随着网络层数的加深,巨量的参数会造成训练时间过长,模型的准确率可能会出现退化的现象。该网络的主要工作证明,网络深度的增加会在一定程度上影响网络的最终性能。其被广泛应用在垃圾图像分类任务中。
VGG16网络结构如图2-3所示,包括13个卷积层、3个全连接层和5个池化层。该网络具有以下优点:
1.结构简单,整个网络使用相同大小的卷积核(3*3),步幅为1和最大池大小(2*2),步幅为2;
2.通过将多个小卷积层(3*3)的组合来替代大的卷积层(5*5或7*7),降低了模型的训练难度和参数量,使得网络更容易拟合,具有更强的泛化能力;
3.验证了不断加深网络的结构可以提高性能。
然而,VGG仍具有一些不足:VGG的训练会消耗更多的计算资源和使用更多的参数,导致占用更多的内存,其中大部分来自第一个完全连接的层。其次,VGG有3个全连接层,导致训练时间过长,参数调整困难,以及所需存储容量大,不利于部署。
图2-3 VGG16模型结构
2.3 ResNet网络模型
在深度学习中,随着网络层数的增加,网络的拟合能力也会逐渐提升。但是简单地将卷积层与全连接层堆叠在一起并不能有效的增加网络的准确率,反而引发梯度弥散或梯度爆炸,造成网络的退化,使得网络性能饱和,准确率迅速下降,变得难以训练。而残差网络模型(ResNet)的残差学习引入快捷连接结构,解决了深层网络中梯度弥散和精度下降的问题,将网络延伸至19层,既保证了精度,又控制了速度。
深度残差网络(ResNet)由何凯明等人于2016年提出,该模型针对网络随着层数加深引发的退化和难以训练问题,提出了快捷连接(Shortcut Connections),如图2-4所示。残差块(residual block)通过快捷连接实现,通过shortcut(identity mapping)将block的输入输出进行一个简单的叠加,这个操作不会给网络增加额外的参数和计算量,却可以大大增加模型的训练速度,提高训练效果,当模型的深度增加时,该结构能够很好的解决退化问题。此外,ResNet网络中,为减少计算成本,将常规残差模块的两个3*3的卷积层由1*1+3*3+1*1卷积层来替代,在不减少精度的情况下大幅减小了计算量,如图2-5,2-6所示。
图2-4 残差模型结构
图2-5 常规残差模型(residual block)
图2-6 瓶颈残差模型(bottleneck block)
2.4注意力模型
注意机制起源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类只能注意到所见信息的一部分。受这种视觉注意机制的启发,人们试图找到视觉选择性注意模型来模拟人类的视觉感知过程,从而模拟人类在观察图像和视频时的注意分布,并扩展其应用。近年来,注意机制在图像和自然语言处理领域取得了重要突破。研究表明,注意机制可以提高模型的性能,通过学习一个注意力权重,对图像数据中的关键数据增加权重,并减少不重要数据的权重,使模型更加关注某些重要的细节部分。注意力机制分为以下两类:自下而上模型和自上而下模型。
自下而上的注意力模型主要由视觉场景的底层特征驱动。自下而上的注意目的是找到图像中重要的目标。传统的自下而上的注意力模型大多依赖于手工制作的低层次图像特征,如颜色和强度来生成显著图。基于直方图的对比度(HC)算法和基于区域的对比度(RC)算法是典型的自底向上注意方法,该方法通过评估全局对比度差异和空间加权一致性得分来生成显著性图。
而近年来,在垃圾图像分类领域应用最广、最有效的视觉注意机制大多属于自上向下的注意力模型。其中自上而下的视觉注意可以进一步分为两类:硬注意和软注意。软注意模型通常是对不同的图像区域或位置“软”地分配不同的权重,可以直接用反向传播算法训练;然而,硬注意模型可以看作是一个离散的单元,它对要使用的图像特征的那一部分进行硬决策。
本文使用的自注意力模型属于软注意力模型,如图2-7所示,该模型通过将图像上的不同位置联系起来,以增强同一显著目标的表达,在图像分类等方面有着广泛的应用。



















 2583
2583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











