






前言:本文将介绍栈和队列的特点,主要讲如何现栈和队列,栈和队列的详细知识大家可以参考相应的教材,主要是水平有限。
目录
栈
定义:
堆栈又名栈(stack),它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
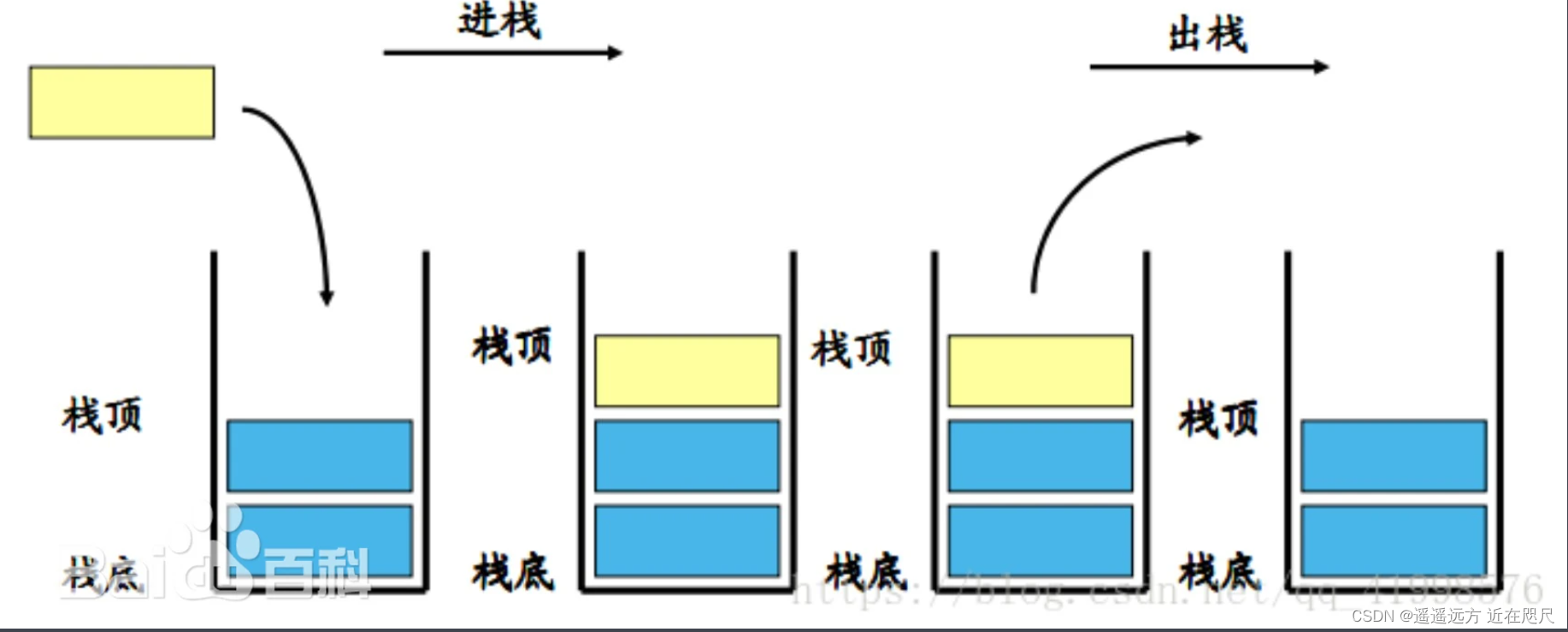
这部分需要了解栈顶,栈底,进栈和出栈的概念。
如果想了解更能多:栈(计算机术语)_百度百科 (baidu.com)
特点:
就是后进先出(先进后出),每次出的数据都是栈顶的元素
实现的结构的选择:
顺序表和链表的区别
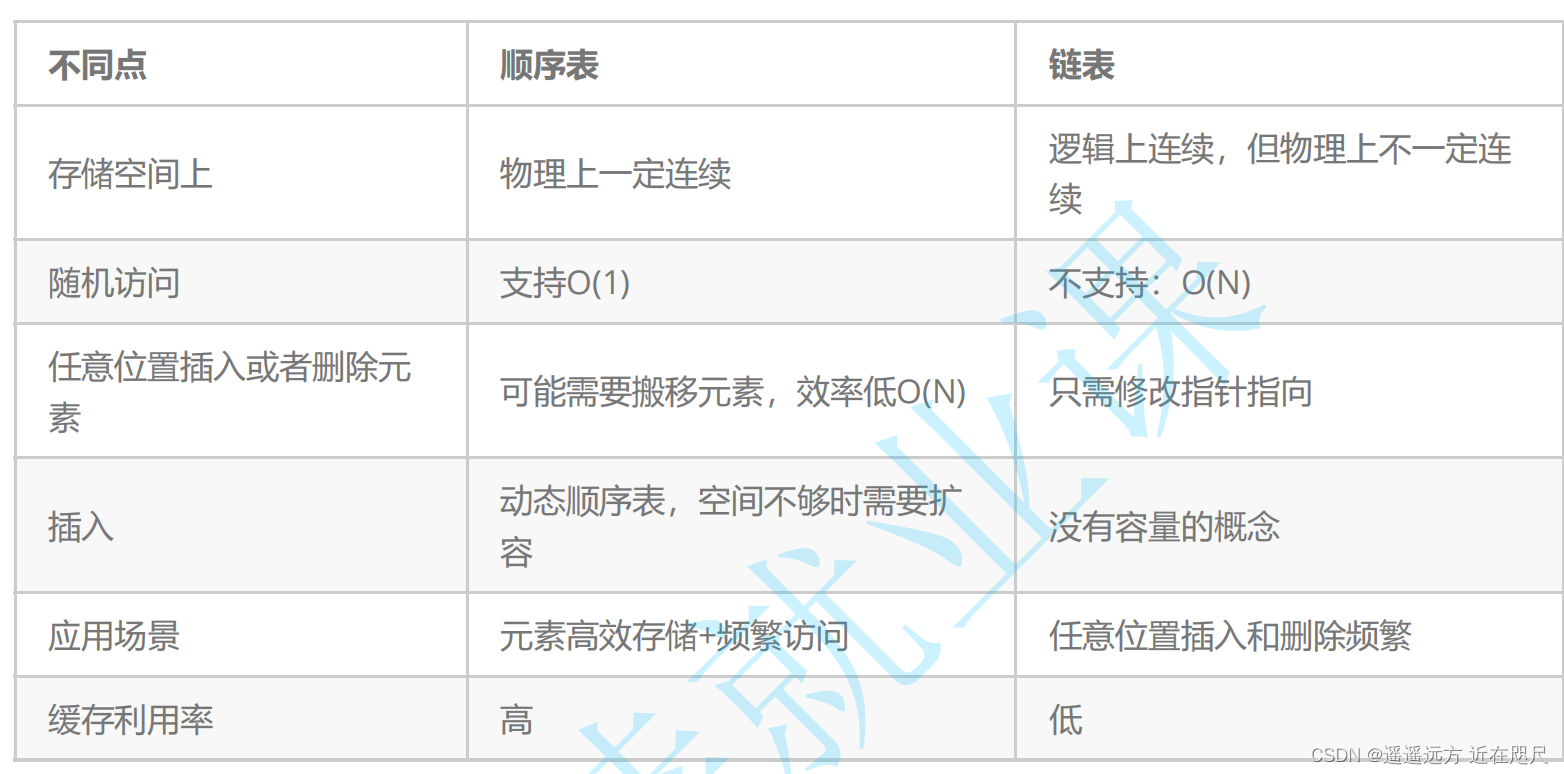
数组:
单向链表:
双向链表:
这三个结构都能实现栈,但可以首先排除,双向链表,因为其相较于单链表更占空间,
单链表相较于数组的优点:单链表开辟空间是没有浪费能随用随开,而数组扩容会有空间浪费和时间浪费(realloc时的异地开辟,需要拷贝数据)
数组相较于链表的优点:就是缓存利用率高,这里涉及到计算机的局部性原理。
所以这里用单链表实现和数组实现都可以,这里用的是数组实现的。
局部性原理:局部性原理_百度百科 (baidu.com)
栈的实现:
栈的结构:
typedef struct Stack
{
STDataType* arr;
int top; // 栈顶
int capacity; // 容量
}Stack;注意:因为采用的是数组实现需要考虑增容的问题,所以有个capacity,top既可以指向栈顶,同时也可以当做顺序表中的size,表示现在栈中有几个元素。
图示:
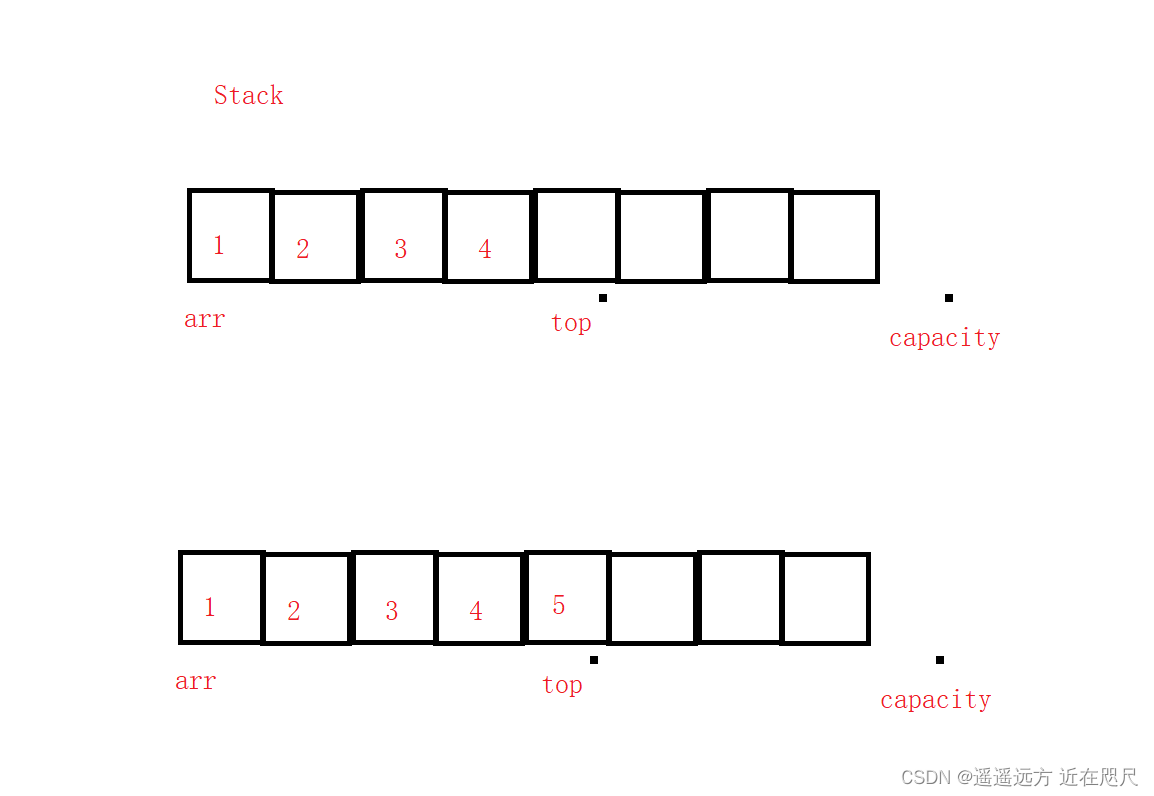
上面的两个的区别就是,第一个top指向栈顶的下一个元素,第二个top指向栈顶。
需要实现的接口:
// 初始化栈
void StackInit(Stack* pst);
// 入栈
void StackPush(Stack* pst, STDataType data);
// 出栈
void StackPop(Stack* pst);
// 获取栈顶元素
STDataType StackTop(Stack* pst);
// 获取栈中有效元素个数
int StackSize(Stack* pst);
// 检测栈是否为空
bool StackEmpty(Stack* pst);
// 销毁栈
void StackDestroy(Stack* pst);各个接口的实现:
注意:这里只是提供一种实现思路
初始化:
// 初始化栈
void StackInit(Stack* pst)
{
assert(pst);
pst->arr = NULL;
pst->top = 0;
pst->capacity = 0;
}注意:初始化时,这里你也可以为arr数组动态开辟一块空间
这里将top为0,就说明我这里的top指向栈顶的下一个元素。
如果top为-1,就说明top指向栈顶
入栈:
// 入栈
void StackPush(Stack* pst, STDataType data)
{
//扩容
if (pst->top == pst->capacity)
{
int newcapacity = pst->capacity == 0 ? 4 : 2 * pst->capacity;
STDataType* tmp = (STDataType*)realloc(pst->arr, newcapacity*sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
pst->capacity = newcapacity;
pst->arr = tmp;
}
pst->arr[pst->top++] = data;
}扩容问题这里就不讲了,如果有兴趣可以看我顺序表的博客中的增容问题。
注意:如果你的top的初始化为-1那么扩容的条件就应该为 pst->top+1 == pst->capacity
插入完元素后别忘了top要加一。
出栈:
//出栈
void StackPop(Stack* pst)
{
assert(pst);
assert(pst->top > 0);//队列中至少得有一个元素
pst->top--;
}出栈:不需要删除数据,只需要top--就可以了。
获取栈顶元素:
// 获取栈顶元素
STDataType StackTop(Stack* pst)
{
assert(pst);
return pst->arr[pst->top-1];
}获取栈中的元素个数:
// 获取栈中有效元素个数
int StackSize(Stack* pst)
{
assert(pst);
return pst->top;
}判断栈是否为空:
// 检测栈是否为空
bool StackEmpty(Stack* pst)
{
return pst->top == 0;//如果栈中的元素个数为0,那么就是空,返回true;反之,栈中元素个数不为0,返回false
}销毁栈:
void StackDestroy(Stack* pst)
{
free(pst->arr);
pst->arr = NULL;
pst->top = 0;
pst->capacity = 0;
}队列:
简介:
队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
如果想了解更多:队列(常用数据结构之一)_百度百科 (baidu.com)
图片:
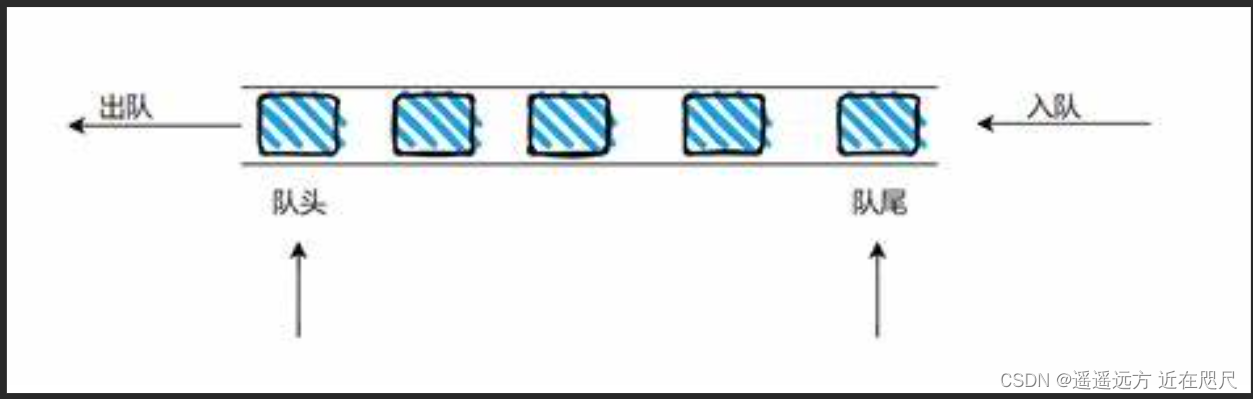
特点:
先进先出,这里可以对比一下栈,也可以联想一下生活中的排队买饭,排在队前的先买到饭,新来的只能排在队尾。
实现结构的选择:
数组:出数据时,数据在对头出去,如果时数组的话,就需要挪动数据,时间O(N);
单链表(不带头双向不循环链表):如果在链表中有个指向尾的指针,那么链表的插入和删除的时间复杂度只有O(1);
双向链表(带头循环双向链表):相较于单链表,双向链表的空间大。
所以最终的比较好的结构是单链表。
队列的实现:
队列结构体的定义:
typedef int QDataType;
typedef struct QNode
{
struct QNode* next;
QDataType val;
}QNode;
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;//记录队列中的元素个数
}Queue;为什么要定义一个Queue结构体呢?
如果没有这个结构体,那么接口对比如下:
void QueuePush(QNode** pphead, QNode** pptail, QDataType data);//因为入队和出队要改变头指针和尾指针的指向,所以需要传二级指针,参数多且麻烦
void QueuePush(Queue* pq, QDataType data);为什么要定义一个size呢?
为了方便实现实现一些接口,减少时间复杂度。比如计算队列的元素个数,如果有size直接返回就可以了,如果没有size那么,就需要遍历到队尾,那么时间复杂度就高了。
需要实现的接口:
// 初始化队列
void QueueInit(Queue* pq);
// 队尾入队列
void QueuePush(Queue* pq, QDataType data);
// 队头出队列
void QueuePop(Queue* pq);
// 获取队列头部元素
QDataType QueueFront(Queue* pq);
// 获取队列队尾元素
QDataType QueueBack(Queue* pq);
// 获取队列中有效元素个数
int QueueSize(Queue* pq);
// 检测队列是否为空
bool QueueEmpty(Queue* pq);
// 销毁队列
void QueueDestroy(Queue* pq);
各个接口的实现:
初始化:
// 初始化队列
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}入队:
// 队尾入队列
void QueuePush(Queue* pq, QDataType data)
{
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->next = NULL;
newnode->val = data;
//队列中没有元素
if (pq->phead == NULL)
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
pq->size++;
}注意:因为这里是不带头的单链表,所以插入数据是要考虑队列中是否为空
提醒一下,别玩了插入完数据后,size要加1
出队:
// 队头出队列
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->phead);
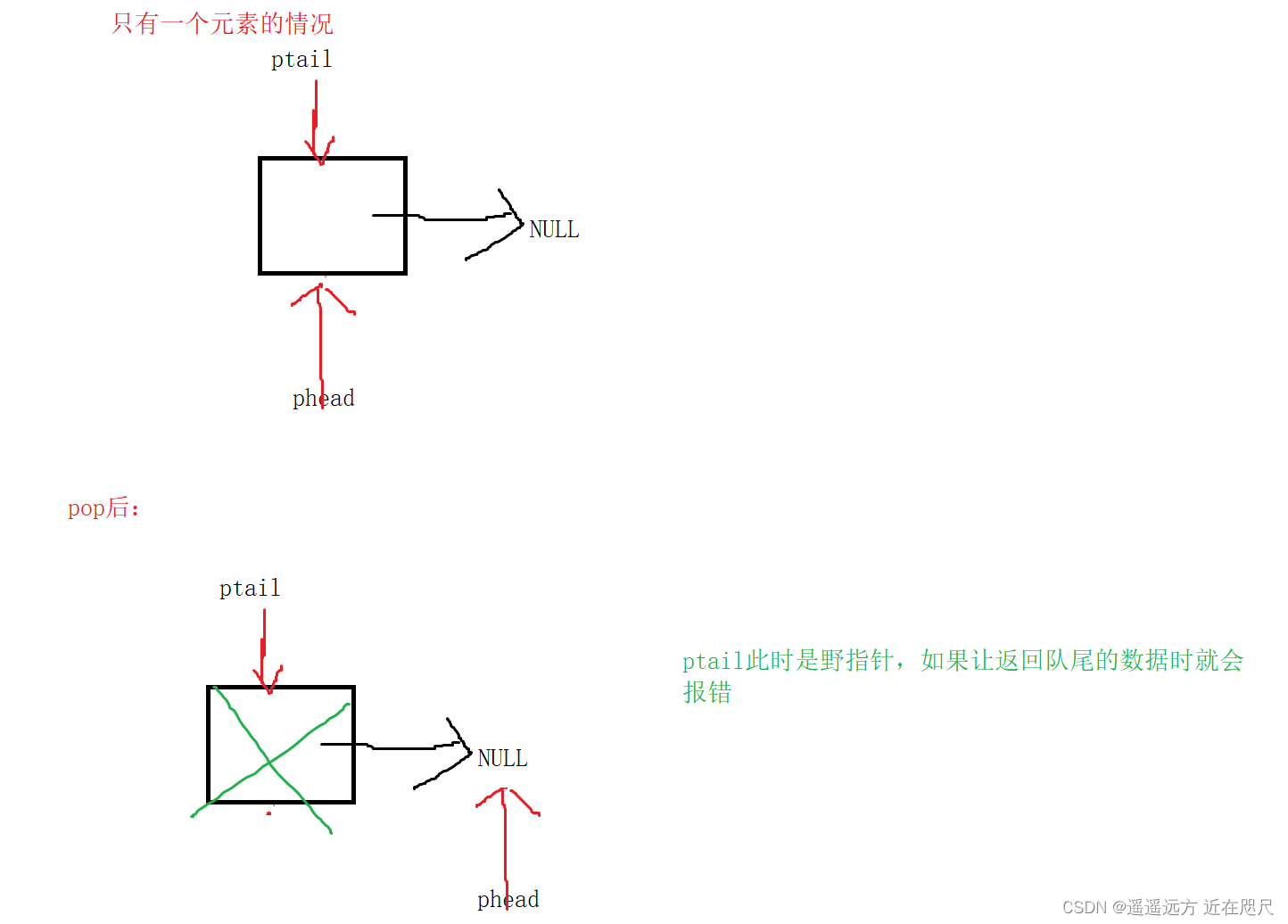
//只有一个元素
if (pq->phead->next == NULL)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else
{
QNode* del = pq->phead;
pq->phead = pq->phead->next;
free(del);
}
pq->size--;
}注意:如果想出队列,那么队列中一定是要有元素的,这里的情况队列中只有一个元素或多个元素,为什么要分这两种情况呢?
一系列简单简单接口:
// 获取队列头部元素
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->phead);
return pq->phead->val;
}
// 获取队列队尾元素
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(pq->ptail);
return pq->ptail->val;
}
// 获取队列中有效元素个数
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
// 检测队列是否为空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}队列的销毁:
// 销毁队列
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}注意:销毁当前节点时,用next记录下一个节点的地址,否则等销毁完当前节点后,找不到下一个节点。
完整代码链接:
又是充实而美好的一天。















 515
515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









