







StepTool: A Step-grained Reinforcement Learning Framework for Tool Learning in LLMs
为了增强 LLM 的工具学习能力,大多数方法都依赖于监督微调(SFT)。尽管 SFT 的实现很简单,但在训练 LLM 进行工具学习时遇到了两个关键限制。首先,模仿静态的预定义工具序列限制了模型适应新任务或环境的能力。其次,专家轨迹虽然可以成功完成任务,但可能不是工具调用的最佳顺序。盲目模仿这些轨迹会导致任务解决性能欠佳。
微调模型的方法还有RLHF,在强化学习视角下,工具调用的每个步骤都被视为导致状态转换的操作,并且模型是从操作-状态转换中训练的。然而,由于几个关键挑战,这些方法并不适合工具学习:1) 工具学习涉及多个决策步骤和来自外部工具和环境的实时反馈。相比之下,RLHF 是基于单步的,数学推理任务中的步骤由 LLM 本身生成,没有来自环境的反馈。2) 工具学习中每个步骤的奖励更为复杂,因为它不仅要考虑工具调用的成功,还要考虑它对任务完成的贡献。
本文是从RLHF出发,提出 StepTool,这种方法确保了对动态、多步骤交互的适应性,解决了 RLHF 等单步方法的局限性。
下面看这个模型的架构,图一左侧展示了一个toollearning的实际场景,右侧展示了监督微调和steptool:
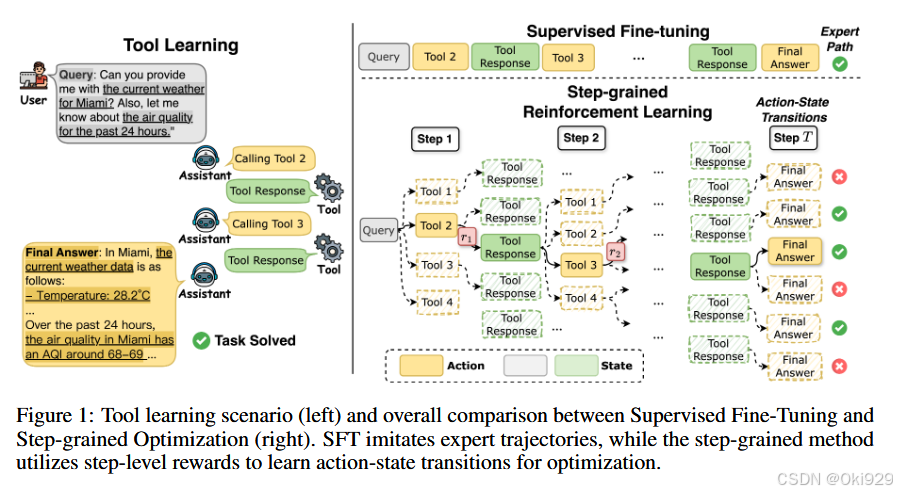
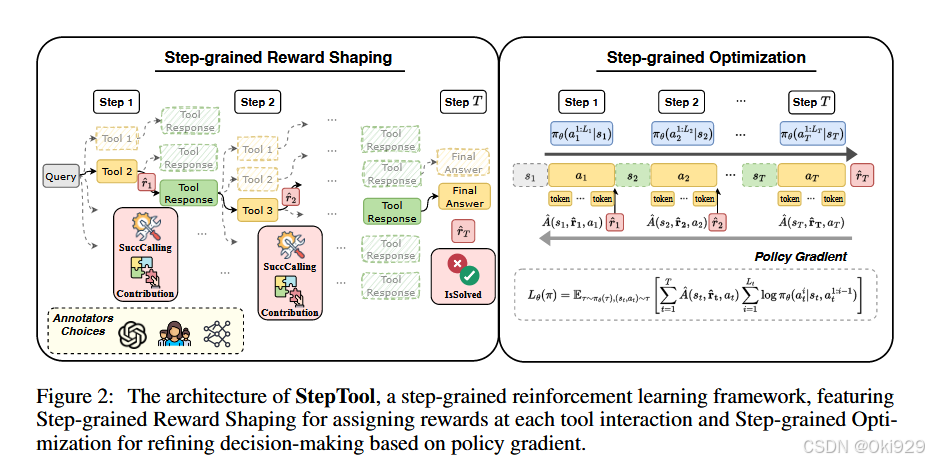
StepTool 的核心思想是通过多步骤的优化和奖励设计,使得模型能够更好地处理需要与外部工具交互的任务。StepTool的架构包括两个主要组件:步骤级奖励塑造(Step-grained Reward Shaping)和步骤级优化(Step-grained Optimization),如下图。
建模
首先,公式化tool Learning的流程:本文将tool Learning建模为一个多步骤决策问题,它可以表述为马尔可夫决策过程,由一个元组组成
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









