






数据查找方法有很多种,各有特点。最简单的一种区分方式:以时间和空间复杂度为区分。在具体了解各大数据查找算法前,先了解一下:什么是时间复杂度?什么是空间复杂度?
1.时间复杂度
算法:解决问题的思想办法,有穷的有序指令集合。算法并不唯一。
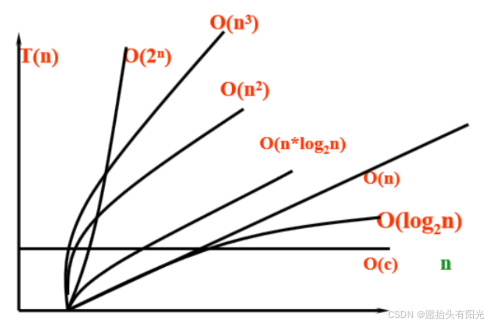
时间复杂度是对算法运行十几件和处理问题规模的一个估算描述。一个算法的时间复杂度越高,那么也就说明这个算法在处理问题时要消耗的时间也就越长。
- O(1):常数时间复杂度,表示不论输入规模如何,算法运行时间是常量。
- O(n):线性时间复杂度,表示算法的运行时间与输入规模成正比。
- O(n^2):平方时间复杂度,通常出现在嵌套循环中,表示运行时间与输入规模的平方成正比。
常见的几种时间复杂:
2.空间复杂度
空间复杂度是指算法在运行过程中所需内存空间的量度,同样使用大O符号表示。它衡量随着输入规模的增加,算法所需的额外空间如何变化。
例如:
- O(1):如果算法所需空间是常数,与输入规模无关。
- O(n):如果算法需要的空间与输入规模成正比,例如存储输入数组。
1.顺序查找
从第一个元素开始,依次比较数组中的每个元素,直到找到目标元素,或者比较到数组尾依旧没有找到目标元素则表明该数组中就没有这个元素。
优点:
对于要查找的数据表没有任何要求
缺点:
数据量大的时候查找速度慢
具体代码如下:
#include <stdio.h>
#include <stdlib.h>
int findByOrder(int* p, int n, int x)
{
int i;
for(i = 0; i < n; i++)
{
if(p[i] == x)
return i;
}
return -1;
}
int main(int argc, const char *argv[])
{
int a[8] = {12,34,2,11,32,123,1,2};
int ret = findByOrder(a, 8, 11);
if(ret == -1)
{
printf("没有找到!!\n");
}
else
{
printf("%d的下标是%d\n",a[ret],ret);
}
return 0;
}
2二分查找(折半查找、二分搜索)
2.1.使用前提:
对象必须是一组有序的数据(无论是升序还是降序)
2.2.算法原理
假设待查数据是x ---》升序为例 求出一个中间位置,让x与中间位置上的数据做比较。 如果x 与中间位置上元素相等,说明找到了 返回中间位置即可。 如果x 大于中间位置上元素,说明可能在右边,去掉区间左侧。 如果x 小于中间位置上元素,说明可能在左边,去掉区间右侧。 重复上面操作直到找到为止。
low低位 high高位 middle中间
2.3.时间复杂度
二分查找时间复杂度: O(log2 n)
二分查找时间复杂度: O(log n)
循环的次数 与 问题规模n的关系式子
问题规模 n
查找数据长度为n,每次查找后减半,
第一次 n/2 n/2^1
第二次 n/2/2 n/2^2
第三次 n/2/2/2 n/2^3
...
第k次 n/2^k
最坏的情况下第k次才找到,此时只剩一个数据,长度为1。
即 n/2^k = 1 // 2^k = n; 求k = log2 n
查找次数 k=logn2.4.非递归实现二分查找
#include <stdio.h>
#include <stdlib.h>
int findByHalf(int* p, int n, int x)
{
int low = 0;
int high =n-1;
int middle;//用来保存中间位置下标
while(low <= high)//low > high循环结束
{
//1.得到中间位置的下标
middle = (low + high) / 2;
//2.x与中间位置的元素做比较,判断在middle位置的左边还是右边,来缩小范围
if(x == p[middle])
return middle; //找到了
else if(x > p[middle])//说明在右侧,需要移动low
low = middle + 1;
else //x < p[middle] //说明在左侧,需要移动high
high = middle - 1;
}
//上面的循环结束后,如果都没有执行return middle,说明没有找到
return -1;
}
int main(int argc, const char *argv[])
{
int a[8] = {11,22,33,40,55,60,70,89};
int num;
scanf("%d",&num);
int ret = findByHalf(a, 8, num);
if(ret == -1)
{
printf("没有找到!!\n");
}
else
{
printf("%d的下标是%d\n",a[ret],ret);
}
return 0;
}2.5.递归实现二分查找
#include <stdio.h>
int findByHalf(int *p, int low, int high, int x)
{
if(low > high)//递归的结束条件
return -1;
//1.得到中间位置元素下标
int middle = (low + high) / 2;
//2.用x与中间位置的元素做比较
if(x == p[middle])
return middle;
else if(x < p[middle])//在左边,移动high
return findByHalf(p, low, middle-1, x);
else if(x > p[middle])//在右边,移动low
return findByHalf(p, middle+1, high, x);
}
int main(int argc, const char *argv[])
{
int a[6] = {11,22,33,44,55,66};
//将数组中的每个元素都查找一遍,测试程序
int i;
for(i = 0; i < 6; i++)
{
printf("%d的位置下标是%d\n",a[i], findByHalf(a,0,5,a[i]) );
}
int ret = findByHalf(a, 0, 5, 100);
if(ret == -1)
{
printf("not find!!!\n");
}
return 0;
}3.分块查找
分块查找适用于索引存储。
索引存储:存数据的时候 源数据表+索引表,查找是先去索引表锁定范围,再到源数据表顺序查找(二分查找)
3.1.使用前提
块内无序,块间有序
3.2.算法原理
将源数据表按照分块原则分成若干个块,查找数据时先锁定在哪一块,再到块内进行查找。
3.3.时间复杂度
顺序查找的时间复杂度是:O(n)
二分查找的时间复杂度是: O(log2 n)
分块查找的时间复杂度是:O(log2 n) ~~O(n)
分块查找的时间复杂度不是一个确定的值,是因为根据你分几块每一个有几个元素都是有关系的。
3.4示例
#include <stdio.h>
typedef struct
{
int max;//每一块的最大值
int post;//每一块的起始下标
}index_t;
int findByBlock(int* a, int n1, index_t* b, int n2, int x)
{
int start,end;//用来保存块的起始和终止下标
//1.先确定x可能在哪一块中
int i;
for(i = 0; i < n2; i++)
{
if(x <= b[i].max)//说明可能在b[i]块中
break;
}
if(i == n2)//说明没有执行过break,说明x,比最后一块的最大值还要大
return -1;//没找到
//2.锁定这一块的起始和终止下标,去源数据表中进行顺序查找
start = b[i].post;
if(i == n2-1)//说明在最后一块,最后一块没有后一块
end = n1-1;//数组长度-1,就是最后一个有效元素下标
else
end = b[i+1].post - 1; //后一块的起始下标-1 得到前一块的终止下标
//取源数据表 在start --- end之间取查找
for(i = start; i <= end; i++)
{
if(x == a[i])
return i;
}
return -1;//没有找到
}
int main(int argc, const char *argv[])
{
//源数据表 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
int a[19] = { 18, 10, 9, 8, 21, 20, 38,42, 19, 50, 51, 72, 56, 55, 76,100, 90, 88, 108};
//索引表
index_t b[4] = {{18, 0},{42, 4},{72, 9},{108, 14}};
//将数组中的每个元素都查找一遍
int i;
for(i = 0; i < 19; i++)
{
printf("%d的位置下标%d\n",a[i], findByBlock(a, 19, b, 4, a[i]));
}
printf("%d的位置下标%d\n",66,findByBlock(a, 19, b, 4, 66));
return 0;
}4.哈希表查找
存储结构:顺序存储 链式存储 索引存储(分块查找) 散列存储(哈希查找) 散列存储:存数据的时候按照某种对应关系存 取数据的时候也得按照对应关系取
Hash表,又称散列表。 理想的查找方法是:对给定的k,不经任何比较便能获取所需的记录,其查找的时间复杂度为常数级O(C)。这就要求在建立记录表的时候,确定记录的key与其存储地址之间的关系f,即使key与记录的存放地址H相对应:
有一张表,保存了数据中关键字与对应的存储位置的关系 在选择key(关键字)的时候,要选择数据中不重复的关键字作为key 哈希查找时间复杂度是:
构建哈希函数的方法: 1.直接地址法 2.叠加法 3.数字分析法 4.平方取中法 5.保留余数法
41.直接地址法
直接地址法适用于唯一标识不重复的数据,比如每个年龄的人口数,每个国家的GDP之类的。他们的数值可能相同,但是根据唯一标识计算而来的存储位置不会发生冲突。
4.2.叠加法
例如商品的条形码序列。如果按照条形码序列开辟散列表,会造成巨大的空间让费,因为它只是数值大,并不是数量多。这个时候就可以使用叠加法。
例如:
#include <stdio.h>
typedef struct
{
int number;//用来保存图书条形码
char book_name[20];
}book_t;
int hashFun(int key)
{
int post = (key / 1000000 + key / 1000 % 1000 + key % 1000) % 1000;
return post;
}
//保存图书信息
//book_t* p //保存哈希表的首地址
//book_t* q //保存一本图书的首地址
void saveBookInfo(book_t* p, book_t* q)
{
//存的时候按照对应关系存
//1.调用哈希函数,得到存储位置
int post = hashFun(q->number);
p[post] = *q;//q里面保存的是main函数中结构体变量b的地址,所以*q代表的就是main函数中的b
}
//通过条形码,查找图书信息
//book_t* p //用来保存哈希表的首地址
book_t* getBookInfo(book_t* p ,int number)
{
//取的时候按照对应关系取
//1.调用哈希函数,得到存储位置
int post = hashFun(number);
//2.将图书信息返回
return &p[post];// return p+post;
}
int main(int argc, const char *argv[])
{
book_t b;
book_t* p = NULL;
int number;
book_t hash_list[1000];//元素类型是book_t因为保存的是图书信息
//图书条形码
//输入3本图书信息,将图书信息保存到哈希表中
int i;
for(i = 0; i < 3; i++)
{
printf("请输入条形码 和 图书编号:\n");
scanf("%d%s",&b.number, b.book_name);
saveBookInfo(hash_list, &b);
}
//输入3个条形码,查找图书的信息
for(i = 0; i < 3; i++)
{
printf("请输入条形码:\n");
scanf("%d",&number);
p = getBookInfo(hash_list, number);
printf("条形码:%d 书名:%s\n",p->number, p->book_name);
}
return 0;
}4.3.数字分析法
通过数字分析,找到某几位重复概率最小的作为关键字进行存储。
//k1 k2 k3 k4 k5 k6
//2 3 1 5 8 6
//2 4 2 3 4 6
//2 3 3 7 9 6
//2 3 9 8 8 6
//2 4 5 7 8 6
//2 3 4 2 9 6
4.4.平方取中法
当key中的某些值不是均匀分布的时,根据数学原理,对key进行key的2次幂(取平方)
取key平方中的某些位可能会比较理想
key key的平方 H(key)
0100 00 100 00 100
0110 00 121 00 121
1010 10 201 00 201
1001 10 020 01 020
0111 00 123 21 123
//对key平方后,发现中间的三位重复次数最少
4.5.保留余数法
int a[11] = {12,23,4,24,2,4,23,1,24,45,23}
源数据表长n
哈希表m=n/α;//α--》装填因子取0.7---0.8之间最为合理
m=11/0.75 = 15;
int hashlist[15]= {0};
H(key) = key % p;//不超过哈希表长的最大质数
H(key) = key % 13;
hashlist[0]---》23
hashlist[1]---》1
hashlist[2]---》2
hashlist[3]
hashlist[4]---》4
hashlist[5]---》4
hashlist[6]---》45
hashlist[7]
hashlist[8]
hashlist[9]
hashlist[10]---》23
hashlist[11]---》24
hashlist[12]---》12
hashlist[13]---》23
hashlist[14]---》24
5哈希冲突解决
51.线性探测法
如果通过哈希函数计算的得出的地址上已经有了数据,那就在该地址的基础上后移一个,直到找到空位为止(或者又回到了原地,此时表明表已经放满了)。
5.2.链地址法
通过哈希函数计算得地址后,通过链表链接的方式连接到散列表对应位置,如果已经有了数据,则采用尾插法链接到该数据后面。

















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









