






目录
一. 栈的概念
栈(Stack)是一种重要的抽象数据类型(ADT),也是一种特殊的顺序表,用于存储有序的元素集合。它的最大特点是后进先出(Last In First Out, LIFO)。这意味着在这个数据结构中,最后添加的元素将是第一个被移除的。
栈的原型:其中进行数据插入的和删除操作的一端称为栈顶,另一端称为栈底。
栈的原则:栈中的数据元素遵守 后进先出(LIFO)的原则
栈的两个典型操作:
压栈:栈的插入操作叫做 进栈 / 压栈 / 入栈 (入数据在栈顶)
出栈:栈的删除操作叫做出栈。(出数据也在栈顶)
二. 栈的结构


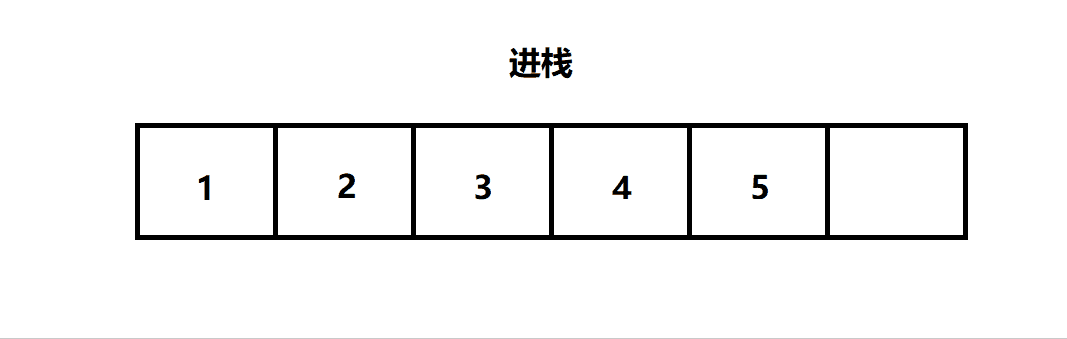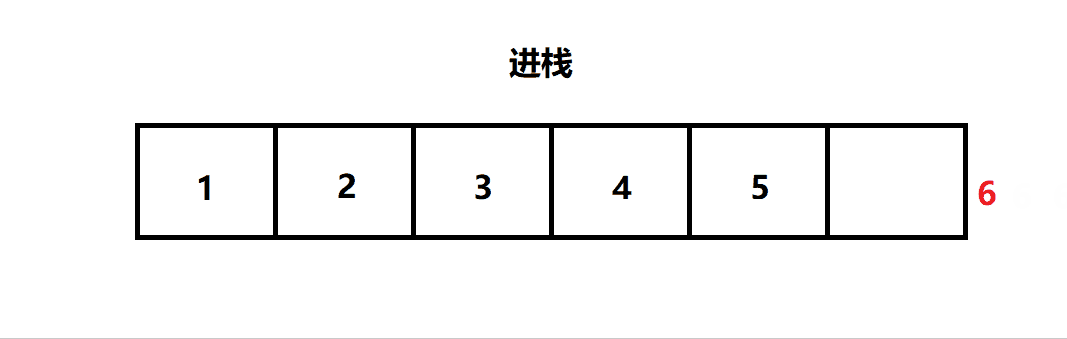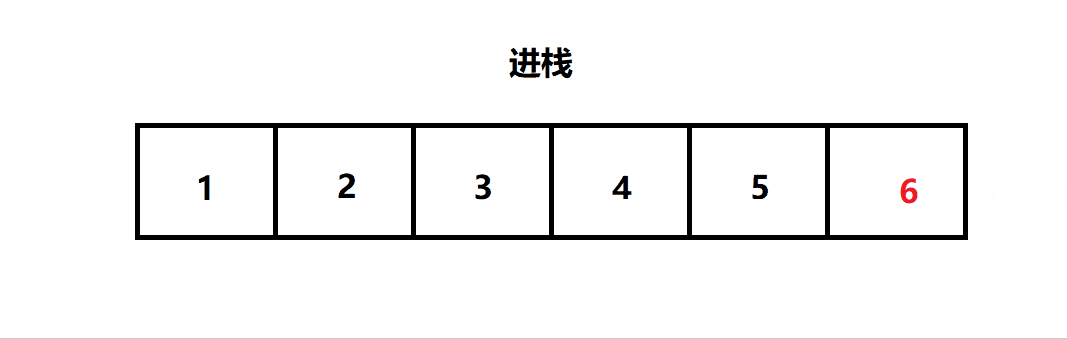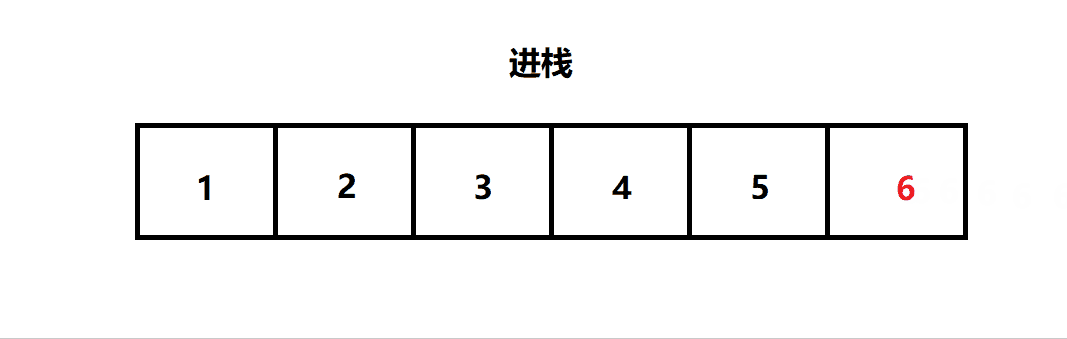
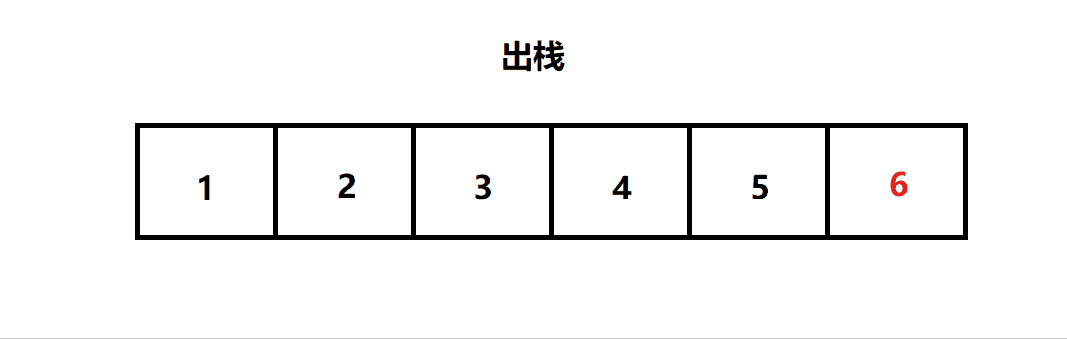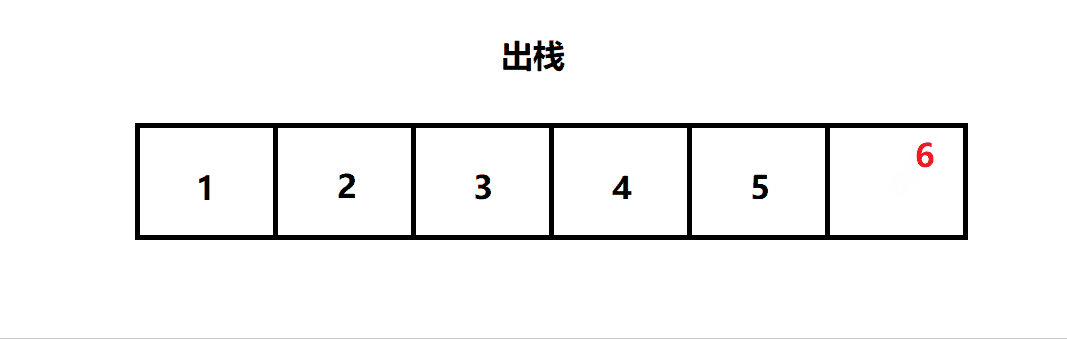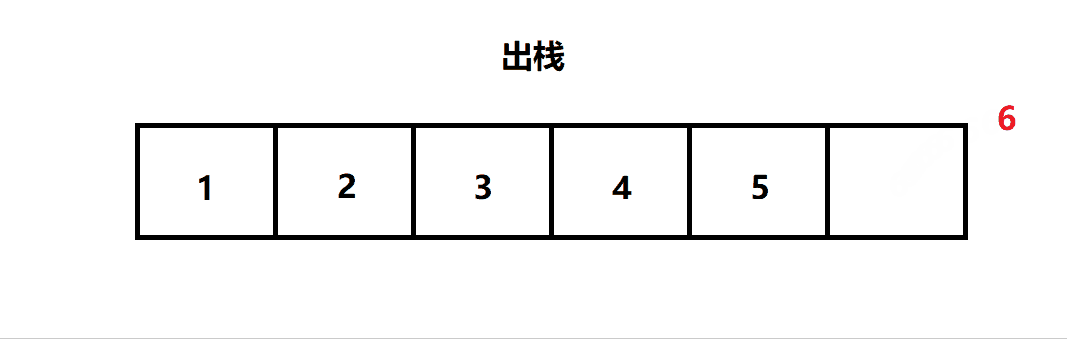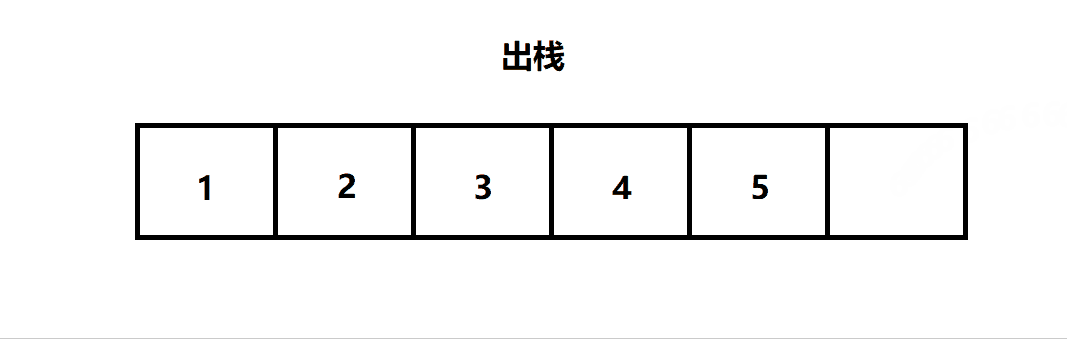
三. 栈的实现
1. 实现栈的两种方式
针对栈的实现,我们可以使用之前学习过的链表 、顺序表都可以实现栈,但是我们需要考虑的什到底要用哪种方式实现栈呢?
链表实现栈
优点:
- 动态大小:链表基于指针链接,因此可以根据需要动态增长和缩小,不需要事先定义容量。
- 内存利用:链表不需要连续的内存空间,因此在内存分配上比较灵活,适合元素数量不确定的情况。
缺点:
- 内存开销:每个元素都需要额外的空间来存储指针,这增加了内存消耗。
- 性能问题:相较于顺序表,链表在内存中可能不连续,可能会影响缓存的利用效率,从而影响性能。
顺序表实现栈
优点:
- 快速访问:顺序表基于数组实现,可以实现快速的随机访问。
- 内存效率:不像链表,顺序表不需要额外的空间来存储指针,内存使用更加高效。
- 缓存友好:由于数据连续存储,顺序表更好地利用了CPU缓存机制,提高了访问效率。
缺点:
- 固定大小:传统的数组大小是固定的,需要提前分配内存,虽然可以通过动态数组(如 C++ 的
std::vector或 Java 的ArrayList)来解决这个问题,但这可能导致复杂的扩容操作和潜在的性能损耗。 - 可能的扩容成本:当数组达到容量极限时,需要进行扩容,这涉及到分配新的更大的内存块,并复制旧数据到新位置,这个过程可能相对耗时。
选择依据
- 性能需求:如果需要最大化性能,特别是访问速度,顺序表(数组)通常是更好的选择。对于频繁的插入和删除操作,链表可能更优。
- 内存考量:如果内存使用更为关键,或者元素大小变化不可预测,链表提供了更灵活的内存管理。
- 实现复杂性:数组的实现通常更简单直接。链表虽然提供更大的灵活性,但需要额外的指针操作和错误处理。
总的来说,没有绝对的“更好”,只有更适合特定需求的实现。例如,如果你预期栈会频繁变化大小,且不太关心随机访问性能,链表可能是一个好的选择。相反,如果你需要高性能和最优的空间利用,且栈的大小相对稳定,使用数组实现的顺序表可能更合适。
栈的创建
需要用结构体创建一个栈,这个结构体需要包括栈的基本内容(栈,栈顶,栈的容量)。

typedef int STDataType;
typedef struct Stack
{
STDataType* a; // 指向动态数组的指针,用于存储栈中的元素
int top; // 栈顶的索引,指向栈顶元素
int capacity; // 栈的容量,表示栈数组可以容纳的最大元素数量
} Stack;栈的初始化
主要是给 栈 一个地址空间,将栈中的数据数据全部清空,与便于后续的操作方便。
void StackInit(Stack* ps)
{
assert(ps);
ps->a = NULL;
ps->capacity = 0;
// 这里需要注意的是当 top=0 时指向的是栈顶元素的下一个位置
// top=-1 时指向的是栈顶元素
// 这里也可以理解为顺序表中 size 有效数据的意思
ps->top = 0;
}栈的销毁
栈的销毁,需要将动态数组的头指针 free 掉,结构体其他元素置0.
void StackDestroy(Stack* ps)
{
assert(ps); // 确保传入的栈指针不为空,防止未定义行为
free(ps->a); // 释放栈使用的动态数组内存
ps->a = NULL; // 将指向动态数组的指针设为NULL,避免悬挂指针(dangling pointer)
ps->top = 0; // 将栈顶索引重置为0
ps->capacity = 0; // 将栈的容量设置为0
// 注意:此处没有释放栈结构本身的内存,仅释放了其内部的动态数组
}入栈
需要判断 栈的容量是否已满,满了就取扩容,没满,则向栈顶插入数据即可
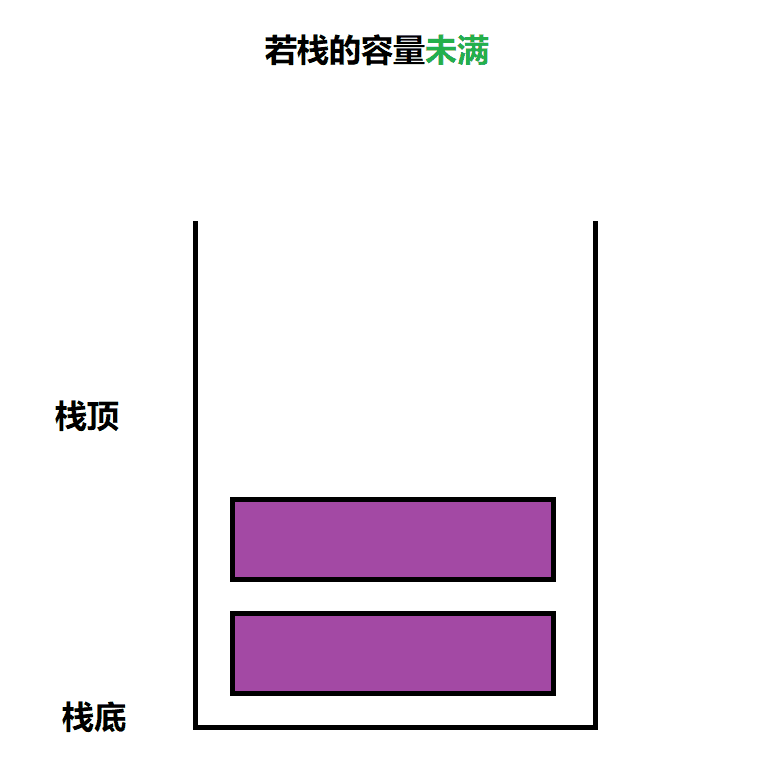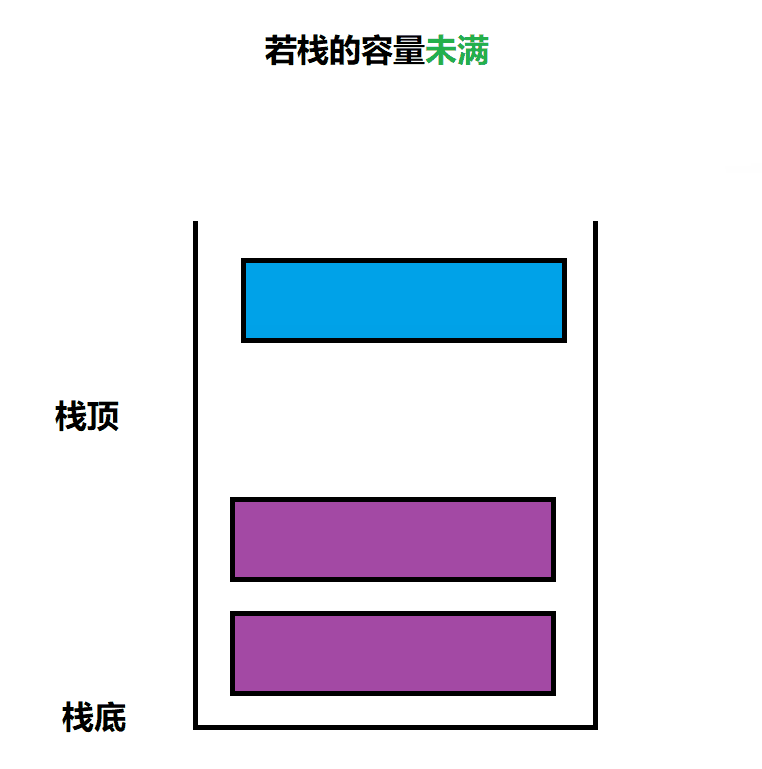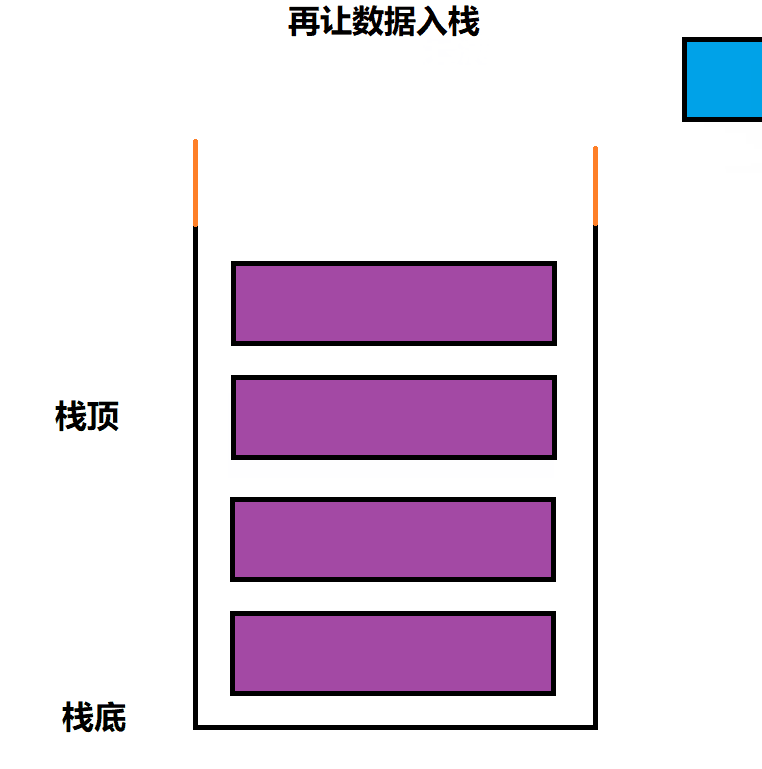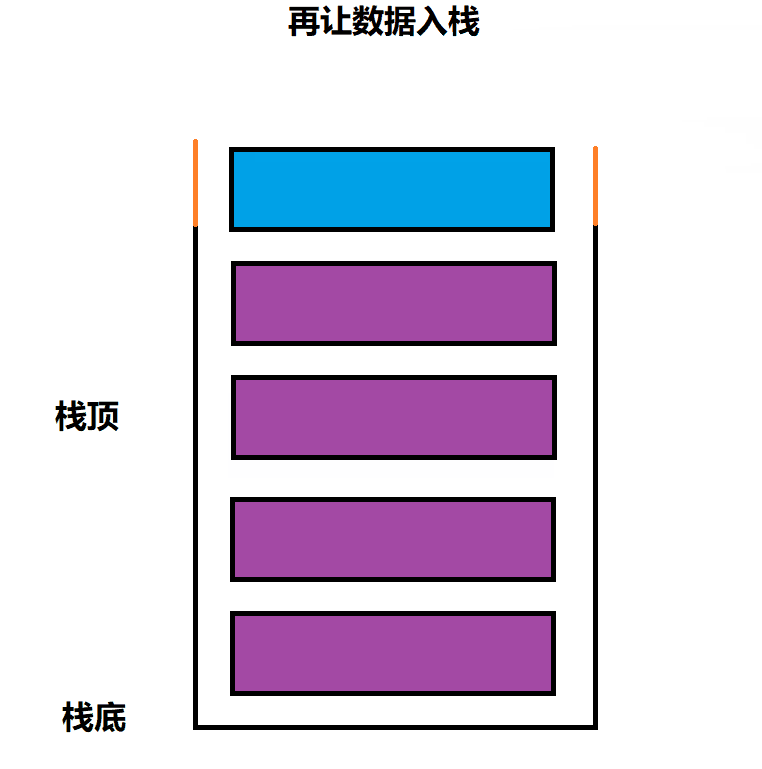
void STPush(Stack* ps, STDataType x)
{
// 此时需要保证传入的栈,不是空
assert(ps);
// 扩容
// 判断是否需要扩容
if (ps->top == ps->capacity)
{
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* temp = (STDataType*)realloc(ps->a, sizeof(STDataType) * newcapacity);
// 防止返回的是空指针
if (temp == NULL)
{
perror("realloc fail!");
exit(-1);
}
ps->a = temp;
ps->capacity = newcapacity;
}
// 进行尾插数据
ps->a[ps->top] = x;
ps->top++;
}
出栈
只需要将栈顶的数据移除即可。
注意:一定要保证栈顶有数据
void StackPop(Stack* ps)
{
assert(ps);
assert(!StackEmpty(ps));//检测栈是否为空
ps->top--;//栈顶下移
}
获取栈顶元素
获取栈顶元素,即获取栈的最上方的元素。若栈为空,则不能获取。
STDataType StackTop(Stack* ps)
{
assert(ps); // 确保传入的栈指针非空
assert(!StackEmpty(ps)); // 确保栈不为空,防止访问空栈
return ps->a[ps->top - 1]; // 返回栈顶元素
//ps->a[ps->top - 1]:这部分代码访问栈中的数组 a,并获取栈顶元素。
//这里使用 ps->top - 1 是因为 top 通常表示下一个可插入元素的位置,
//所以栈顶的实际元素位于 top - 1 的位置。
}
判断栈是否为空
判断栈是否为空的函数通常检查栈顶指针top的值。如果top为0,则表示栈中没有元素,即栈为空
bool StackEmpty(Stack* ps)
{
assert(ps); // 断言检查,确保传入的栈指针非空
return ps->top == 0; // 返回栈是否为空的判断结果
}
获取栈中有效数据的个数
因为top记录的是栈顶,使用top的值便代表栈中有效元素的个数。
int StackSize(Stack* ps)
{
assert(ps);
return ps->top;//top的值便是栈中有效元素的个数
}















 2104
2104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









