






目录
5.2 两台调度器安装keepalived和ipvsadm及配置
6.Nginx+KeepAlived高可用负载均衡集群的部署
1.高可用群集的相关知识
1.1 单台服务器
企业应用中,单台服务器承担应用存在单点故障的危险;单点故障一旦发生,企业服务将发生中断,造成极大的危害。
1.2 keepalived

一个合格的群集应该具备的特点:
- 负载均衡:用于提高群集的性能(LVS Nqinx HAProxy SLB F5)
- 健康检查(探针):针对于调度器和节点服务器(KeepalivedHeartbeat)
- 故障转移:通过VIP漂移实现主备切换
健康检查(探针)常用的工作方式::
- 发送心跳消息:vrrp报文、ping/pong
- TCP端口检查:向目标主机的 IP:PORT 发起TCP连接请求,如果TCP连接三次握手成功则认为健康检査正常,否则认为健康检査异常
- HTTP URL检查:向目标主机的URL路径(比如http://IP:PORT/URL路径)发起 HTTP GET 请求方法,如果响应消息的状态码为 2xx 或 3xx 则认为健康检查正常;如果响应消息的状态码为 4xx 或 5xx 则认为健康检查异常。
1.3 Keepalived实现原理


2.部署keepalived
Keepalived体系主要模块及其作用:
keepalived体系架构中主要有三个模块,分别是core、check和vrrp。
- core模块:为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析。
- vrrp模块:是来实现VRRP协议的。(调度器之间的健康检查和主备切换)
- check模块:负责健康检查,常见的方式有端口检查及URL检查。(节点服务器的健康检查)
2.1 准备虚拟机
192.168.9.210用作主调度器
192.168.9.120用作备调度器
2.2 初始化操作
2.3 更新在线源仓库并安装keepalived

2.4 配置主调度器
2.5 配置备调度器

2.6 启动主备keepalived
systemctl start keepalived
systemctl enable keepalived2.7 验证
主服务器: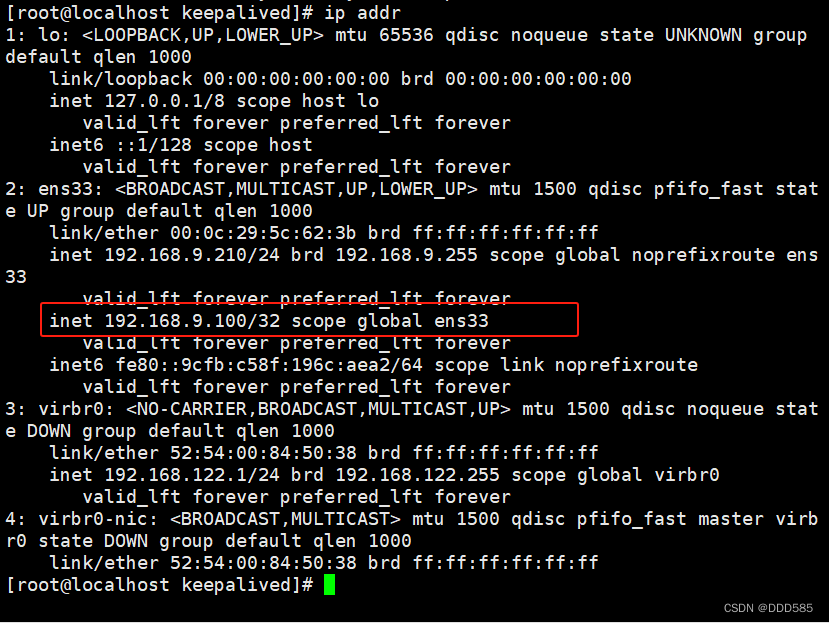
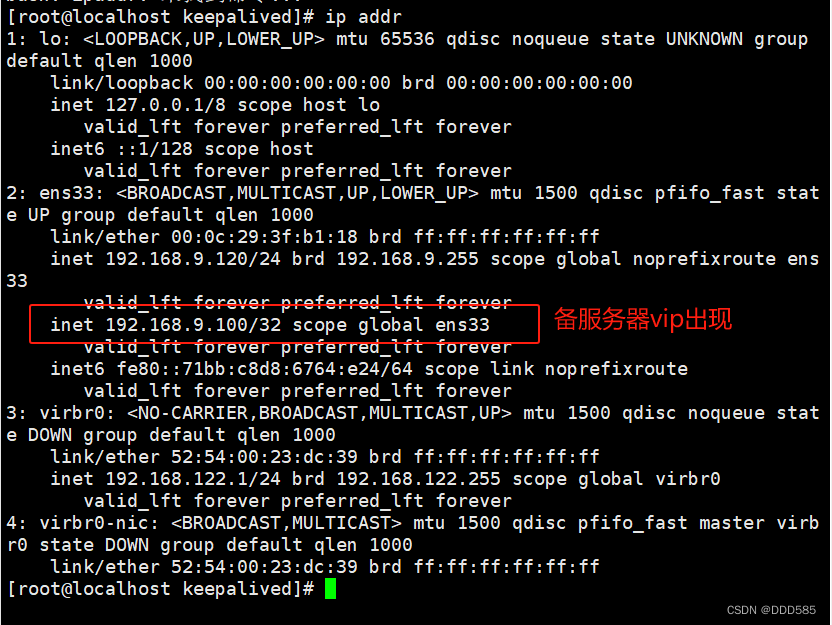
备服务器: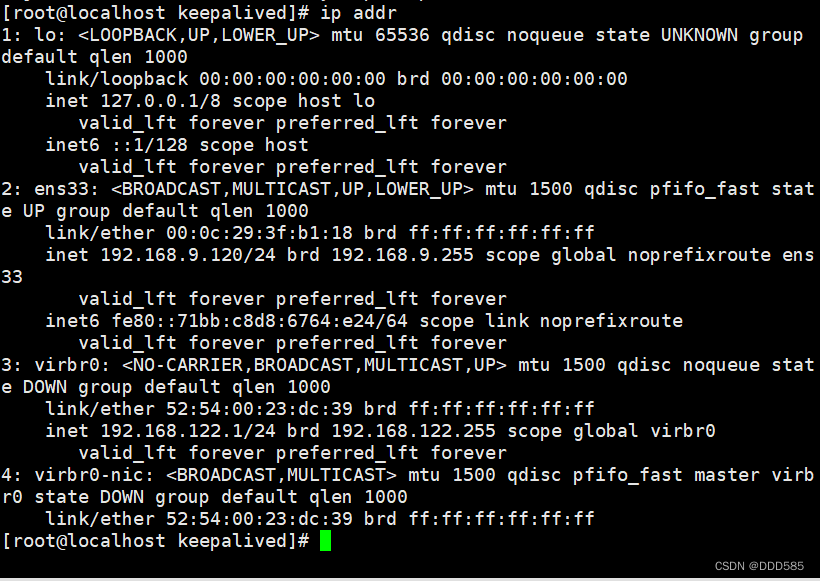
模拟主服务器故障

3.常问题目
1.Keepalived通过什么判断哪台主机为主服务器,通过什么方式配置浮动IP?
答案:
Keepalived首先做初始化先检查state状态,master为主服务器,backup为备服务器。
然后再对比所有服务器的priority,谁的优先级高谁是最终的主服务器。
优先级高的服务器会通过ip命令为自己的电脑配置一个提前定义好的浮动IP地址。
keepalived的抢占与非抢占模式:
抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP
非抢占式俩节点state必须为bakcup,且必须配置nopreempt。
注意:这样配置后,我们要注意启动服务的顺序,优先启动的获取master权限,与优先级没有关系了。
4.非抢占模式配置
于抢占模式基础上配置
4.1 修改主备服务器配置
192.168.9.210(原主服务器)
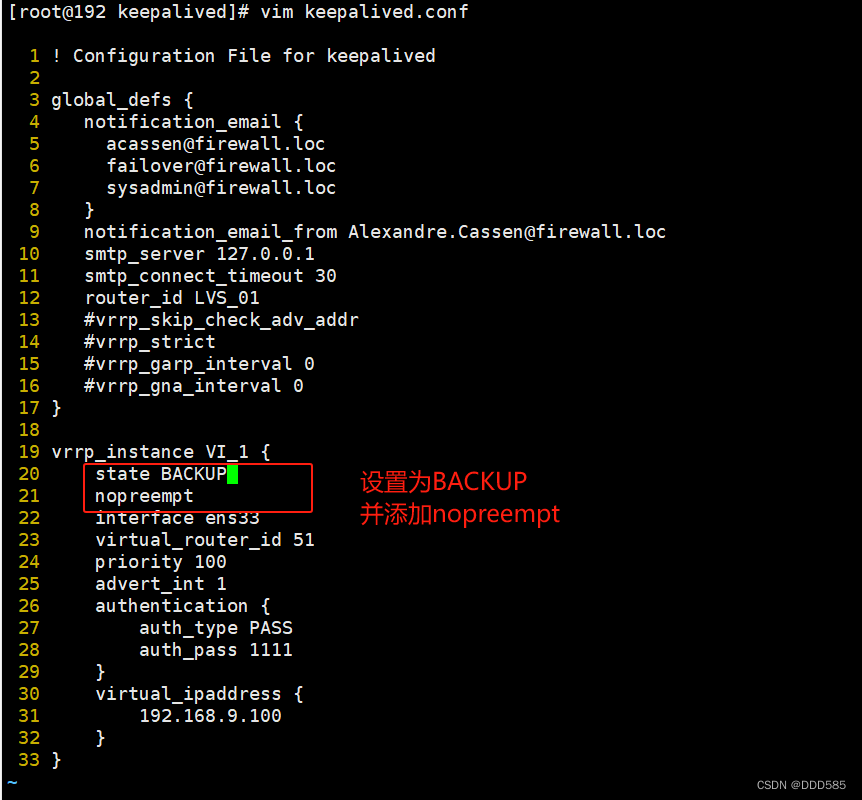
192.168.9.120(原备服务器)
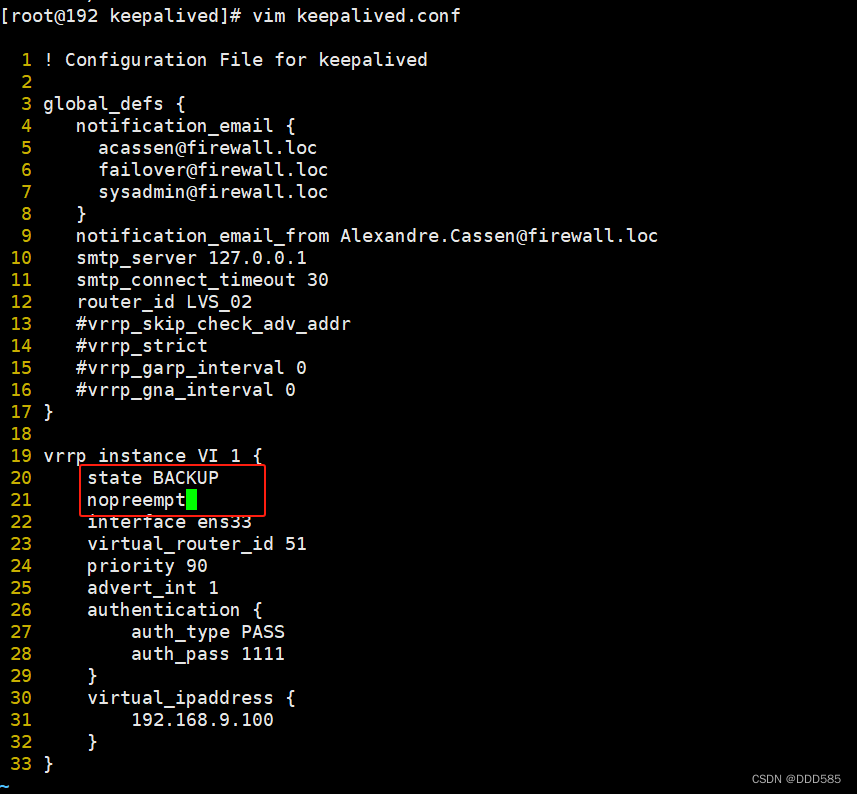
#先关闭主备两台服务器keepalived
systemctl stop keepalived4.2 验证
非抢占模式下,不看优先级顺序,以启动顺序为依据,先开启哪台,vip就在哪台
192.168.9.210虚拟机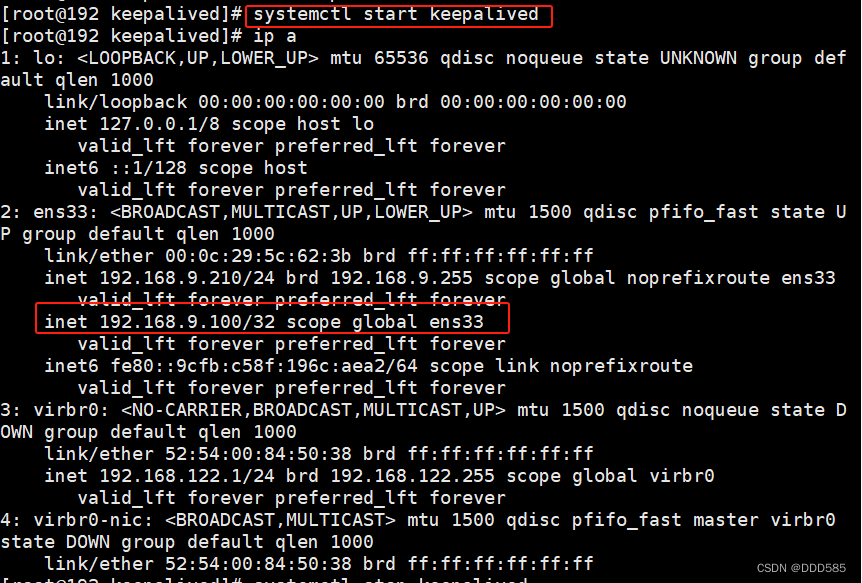
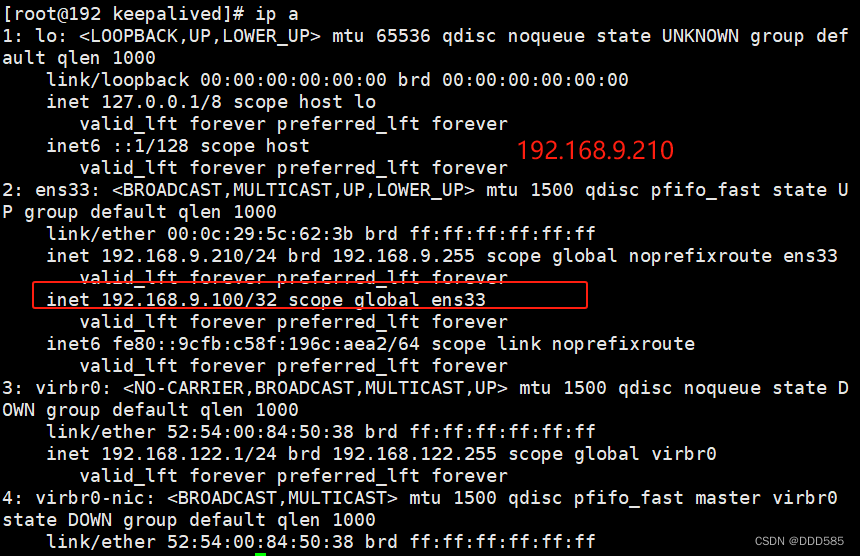
模拟关闭后vip转移到192.168.9.120![]()
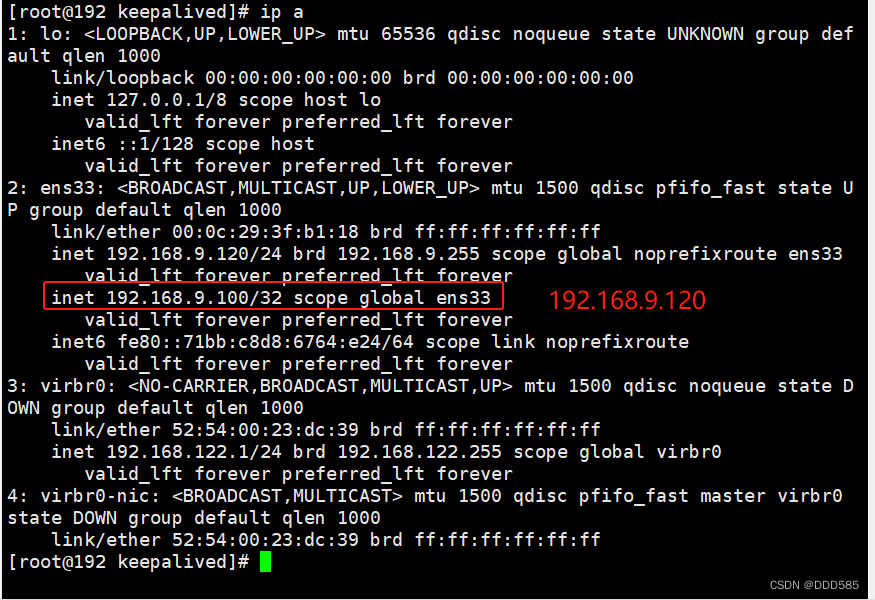
就算192.168.9.210重启keepalived,vip也不会回来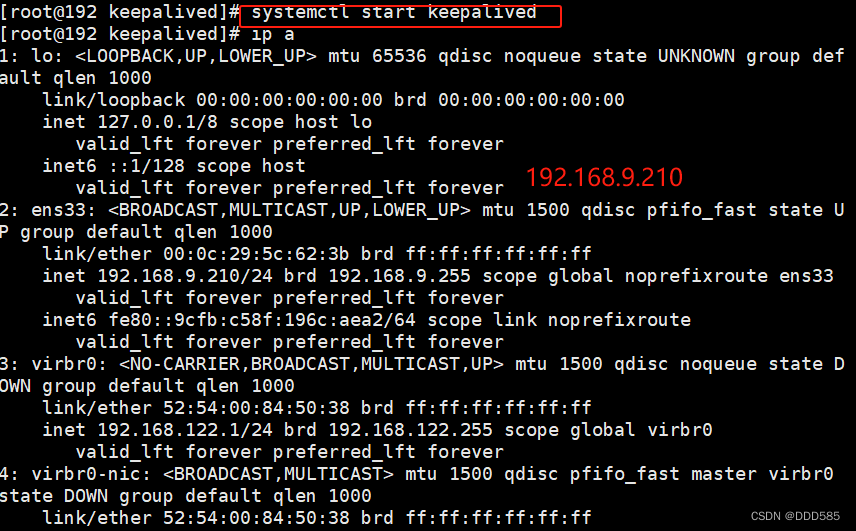
若想vip重新返回192.168.9.210,只有通过在192.168.9.120上重启keepalived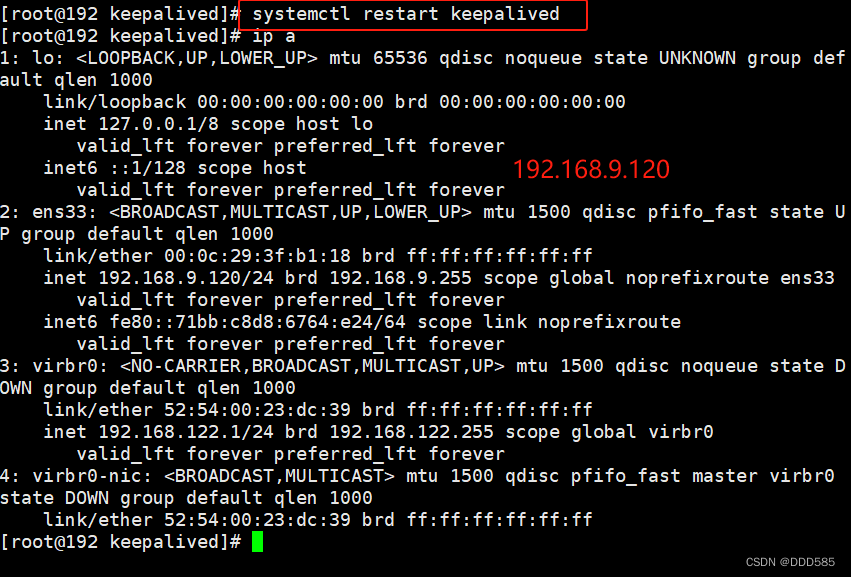
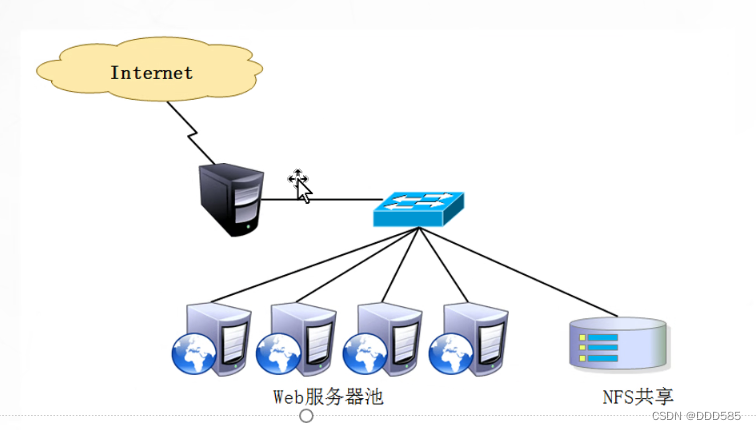
5.LVS+KeepAlived高可用负载均衡集群的部署
实验以6.11博客 LVS-DR实验结果为基础,其中192.168.9.210lvs调度器虚拟机不使用原本配置,其余使用原本配置
5.1 准备虚拟机
192.168.9.112用作nfs共享存储
192.168.9.140和192.168.9.150用作节点服务器
192.168.9.210用作KeepAlive主调度器
192.168.9.120用作KeepAlive备调度器
5.2 两台调度器安装keepalived和ipvsadm及配置
yum install -y ipvsadm
yum install -y keepalived

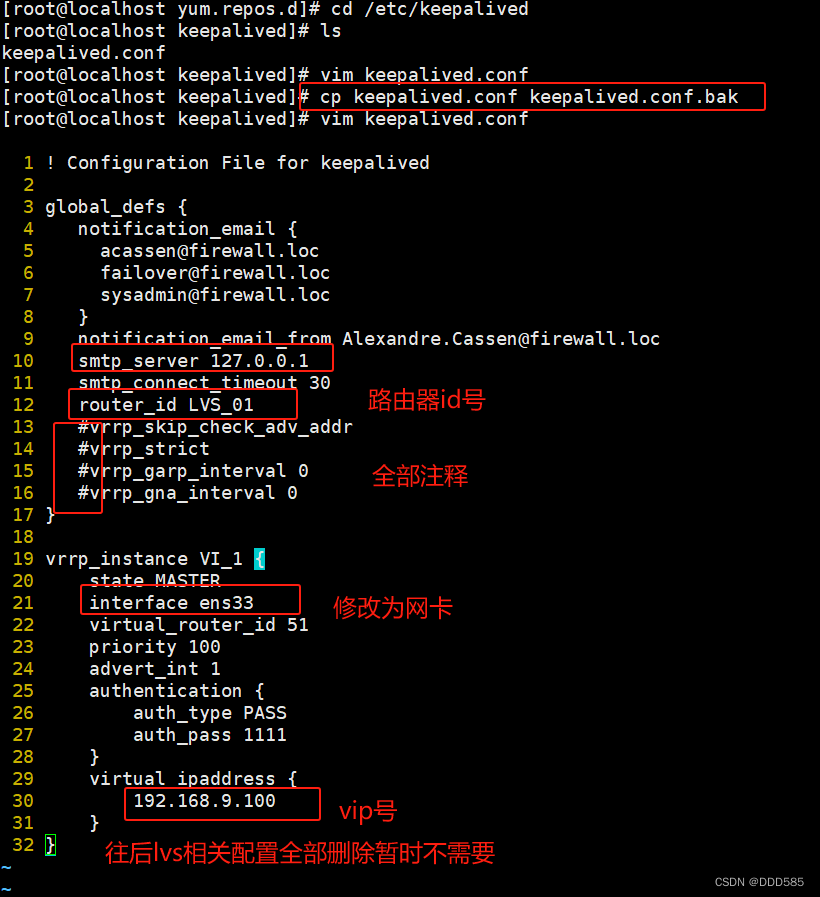
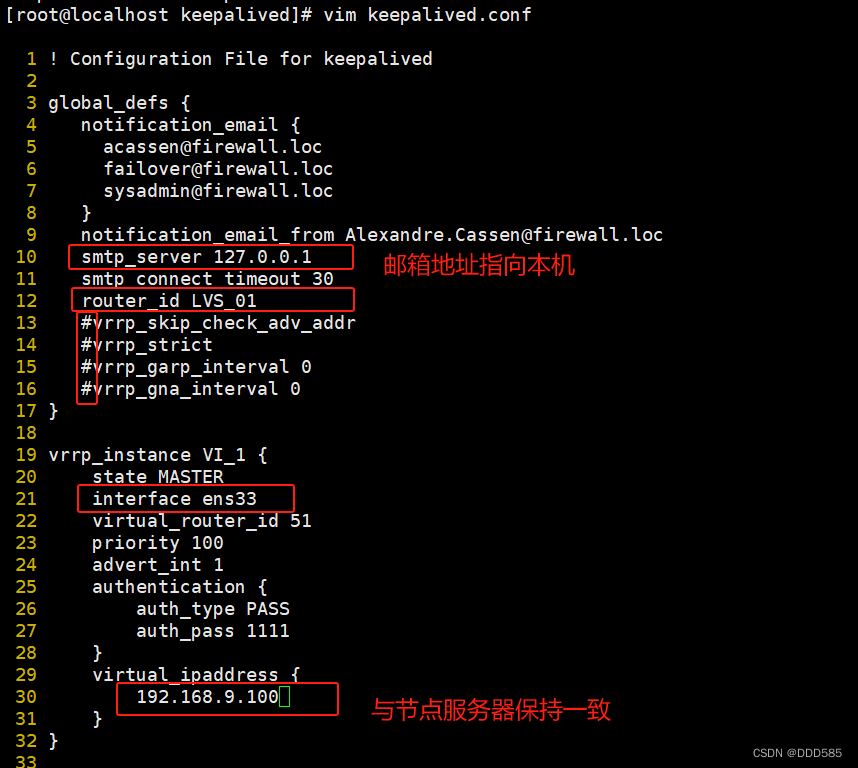
修改主调度器配置
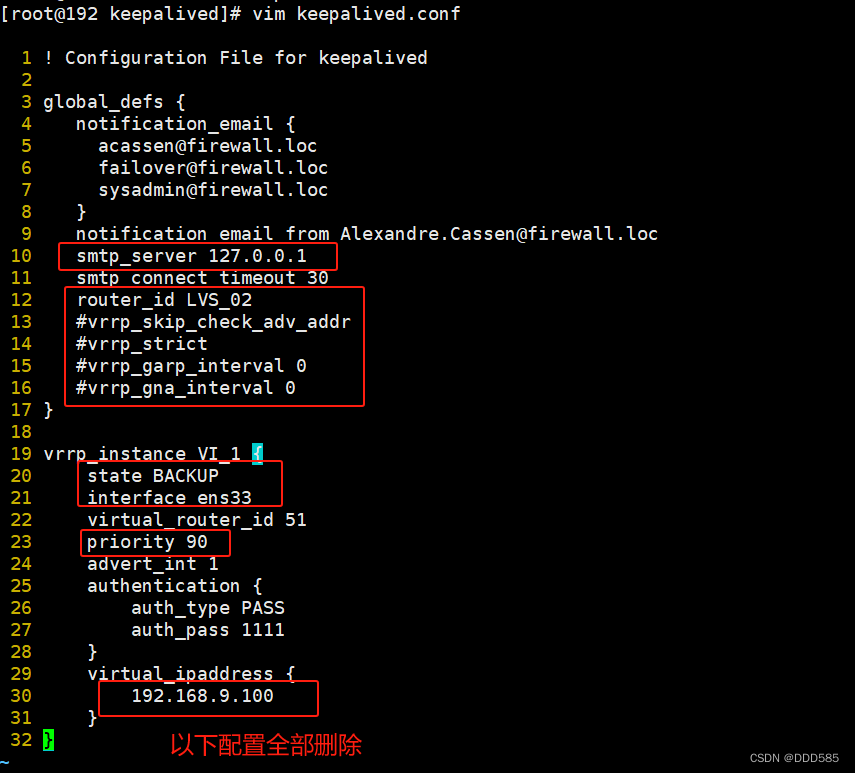
1 ! Configuration File for keepalived
2
3 global_defs {
4 notification_email {
5 acassen@firewall.loc
6 failover@firewall.loc
7 sysadmin@firewall.loc
8 }
9 notification_email_from Alexandre.Cassen@firewall.loc
10 smtp_server 127.0.0.1 #邮箱地址指向本地
11 smtp_connect_timeout 30
12 router_id LVS_01
13 #vrrp_skip_check_adv_addr
14 #vrrp_strict
15 #vrrp_garp_interval 0
16 #vrrp_gna_interval 0
17 }
18
19 vrrp_instance VI_1 {
20 state MASTER
21 interface ens33 #指向网卡
22 virtual_router_id 51
23 priority 100 #优先级
24 advert_int 1
25 authentication {
26 auth_type PASS
27 auth_pass 1111
28 }
29 virtual_ipaddress {
30 192.168.9.100 #vip地址需要与节点ip保持一致
31 }
32 }
34 virtual_server 192.168.9.100 80 { #vip地址及端口号
35 delay_loop 6 #健康检查间隔时间
36 lb_algo rr #调度方法
37 lb_kind DR #lvs的模式
38 persistence_timeout 0 #连接保持时间
39 protocol TCP
40
41 real_server 192.168.9.140 80 { #真实服务器配置,节点服务器ip
42 weight 1 #权重
43 TCP_CHECK { #tcp端口检查
44 connect_port 80 #使用tcp80端口做健康检查
45 connect_timeout 3 #连接超时时间
46 nb_get_retry 3 #重试次数
47 delay_before_retry 3 #每次重试的间隔时间
48 }
49 }
50
51
52 real_server 192.168.9.150 80 {
53 weight 1
54 TCP_CHECK {
55 connect_port 80
56 connect_timeout 3
57 nb_get_retry 3
58 delay_before_retry 3
59 }
60 }
61 }

修改备调度器配置
将主调度器keepalived.conf复制到备调度器进行修改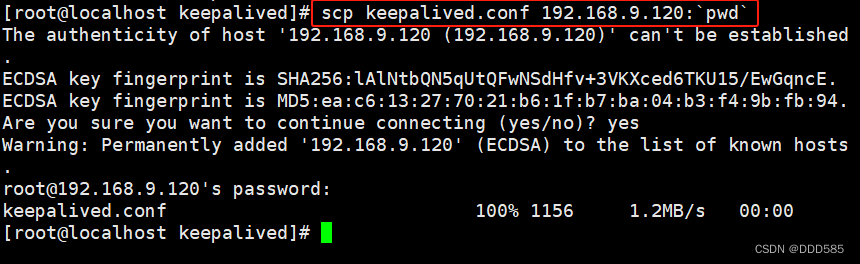

分别开启主备服务器keepalived
systemctl start keepalived
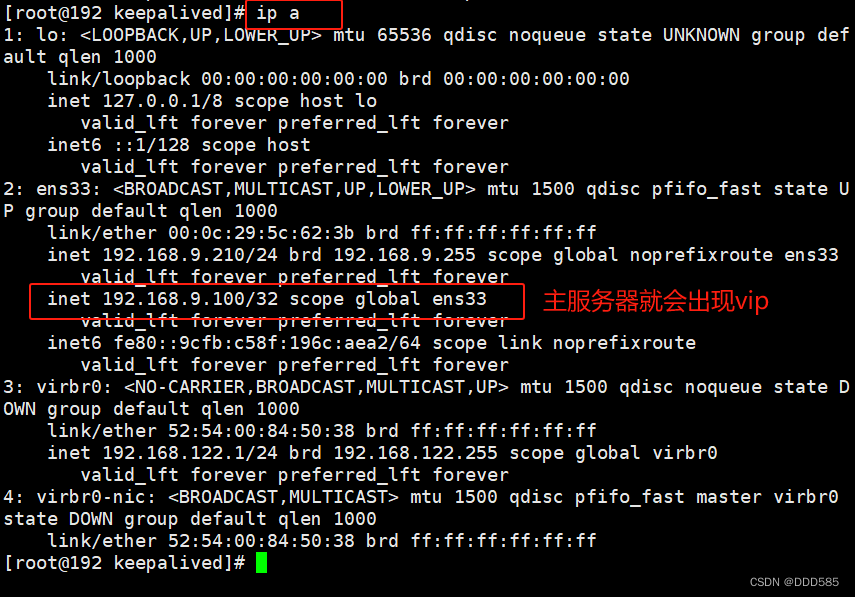
5.3 网页测试


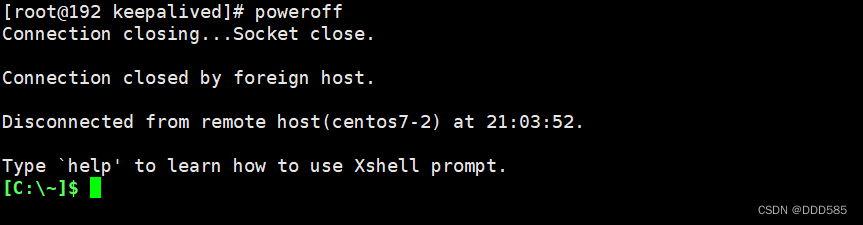
主调度器模拟故障:

浏览器仍可以正常访问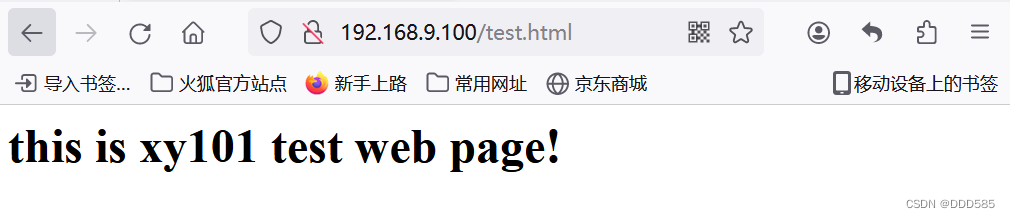
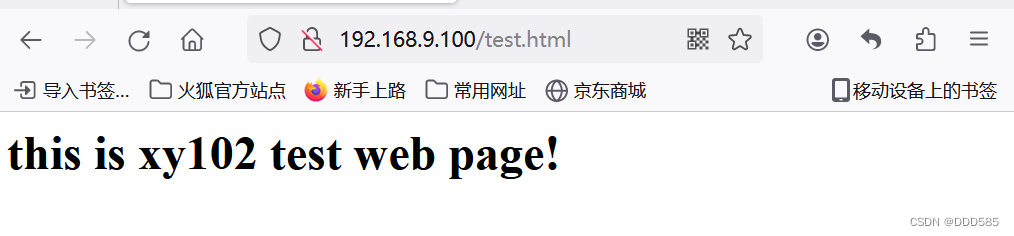
6.Nginx+KeepAlived高可用负载均衡集群的部署
此实验基于以上 LVS+KeepAlived高可用负载均衡集群的部署 实验为基础,将两台调度器改为nginx服务器,其余不变。
6.1 准备虚拟机
192.168.9.112用作nfs共享存储
192.168.9.140和192.168.9.150用作节点服务器
192.168.9.210用作nginx服务器(四层代理)
192.168.9.120用作nginx服务器(四层代理)
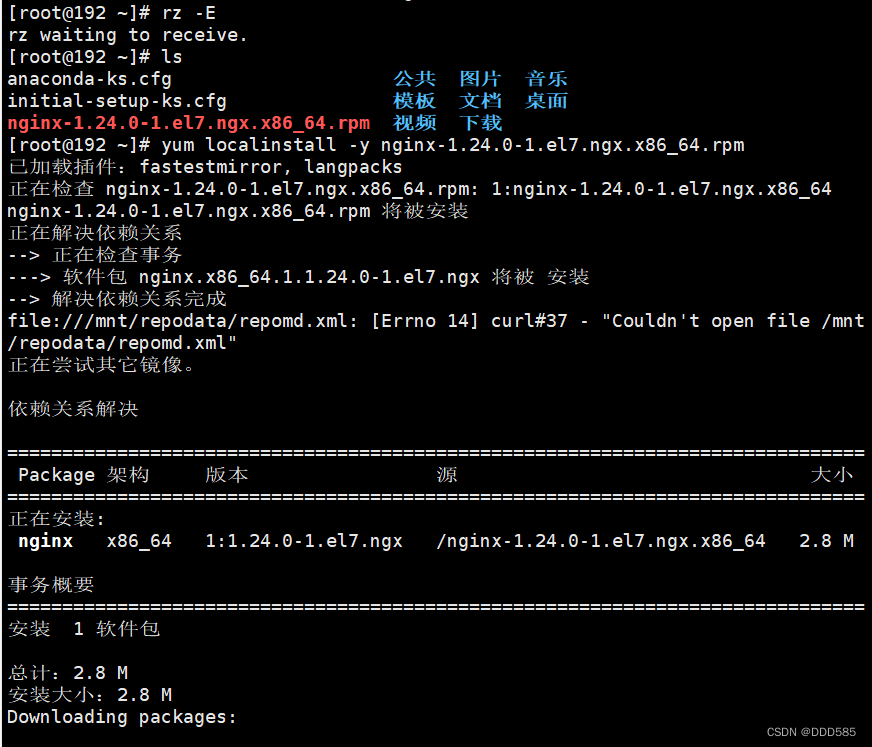
6.2 两台nginx做初始化操作并安装nginx
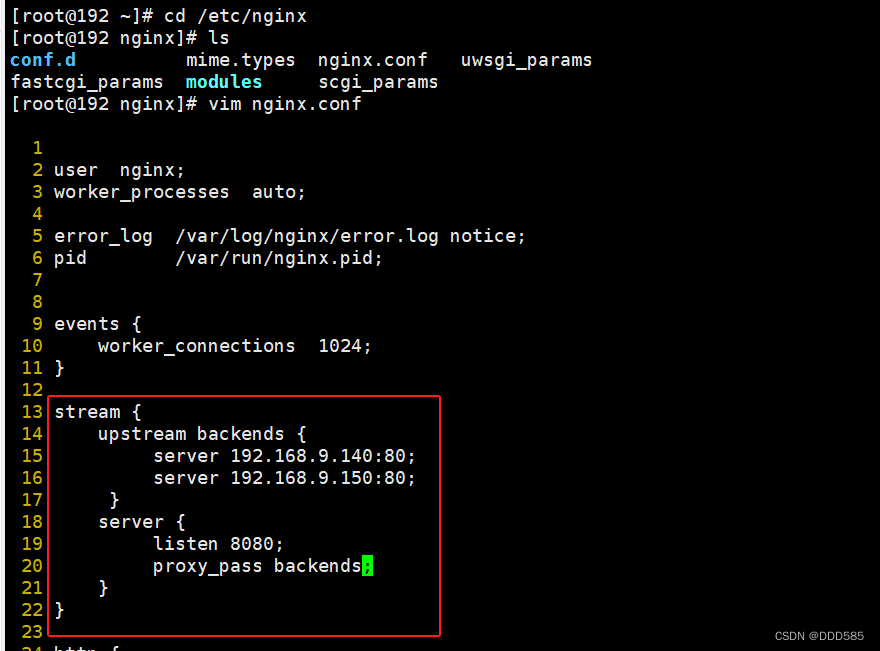
6.3 四层反向代理配置
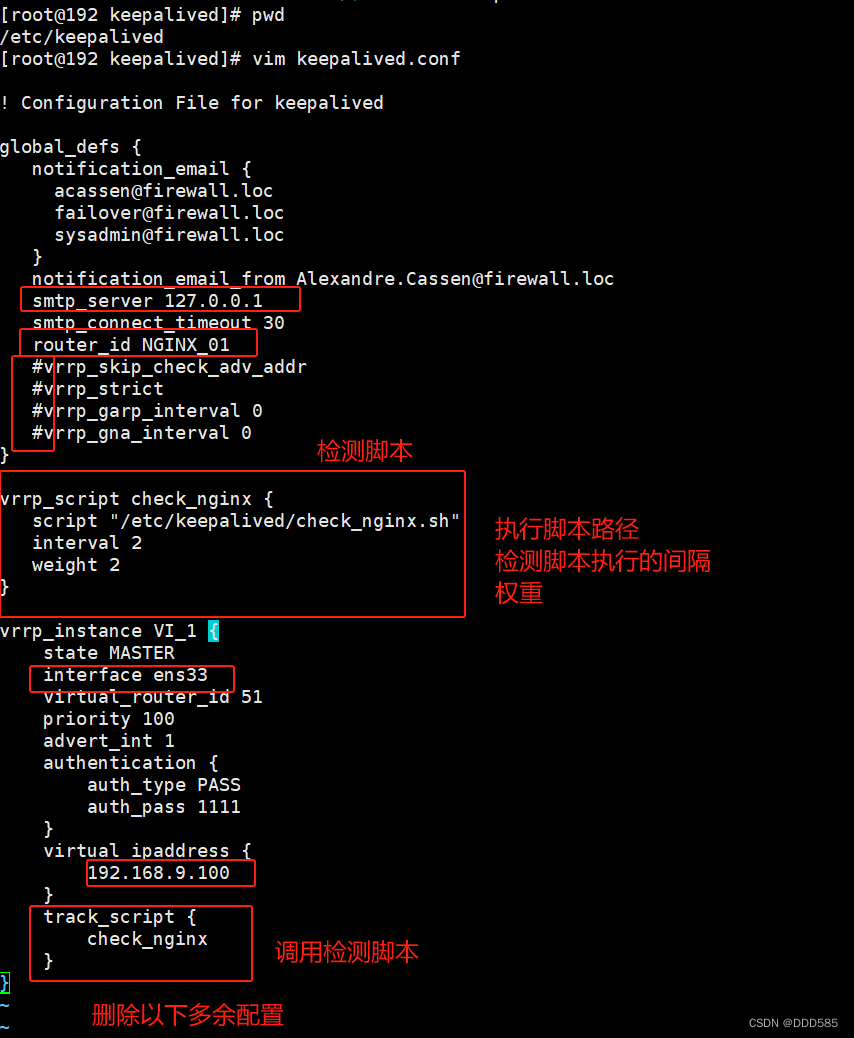
修改主调度器配置
#配置四层反向代理
stream {
upstream backends {
server 192.168.9.140:80;
server 192.168.9.150:80;
}
server {
listen 8080;
proxy_pass backends;
}
}
修改备调度器配置
将192.168.9.210中的nginx.conf文件复制过来

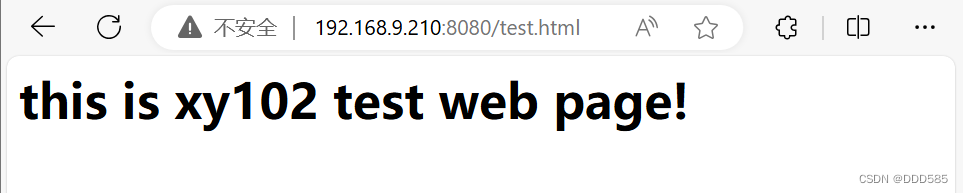
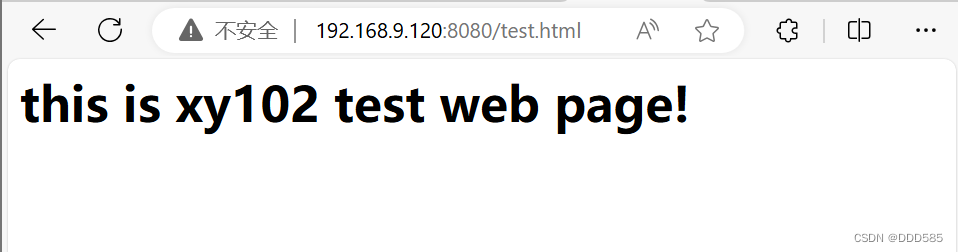
浏览器测试两台nginx服务器
192.168.9.210
192.168.9.120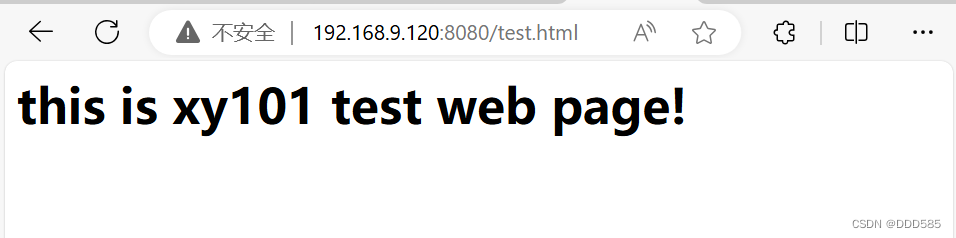
6.4 配置高可用
两台nginx服务器安装keepalived
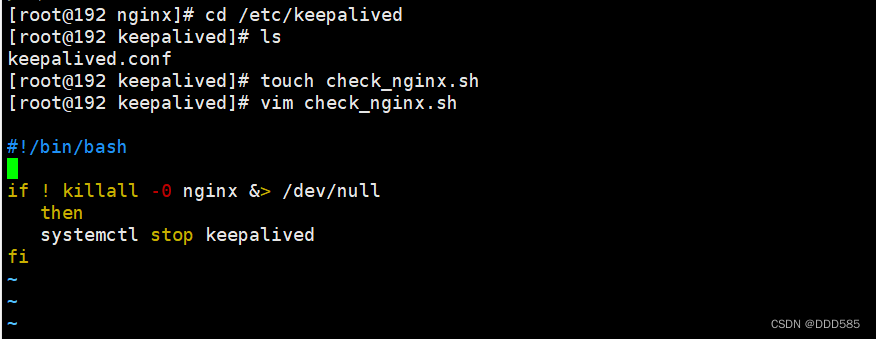
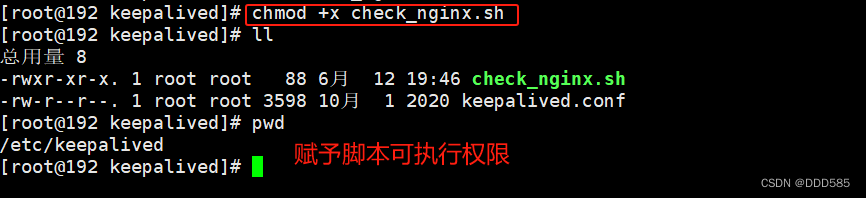
yum install -y keepalived6.5 准备检查nginx运行状态脚本
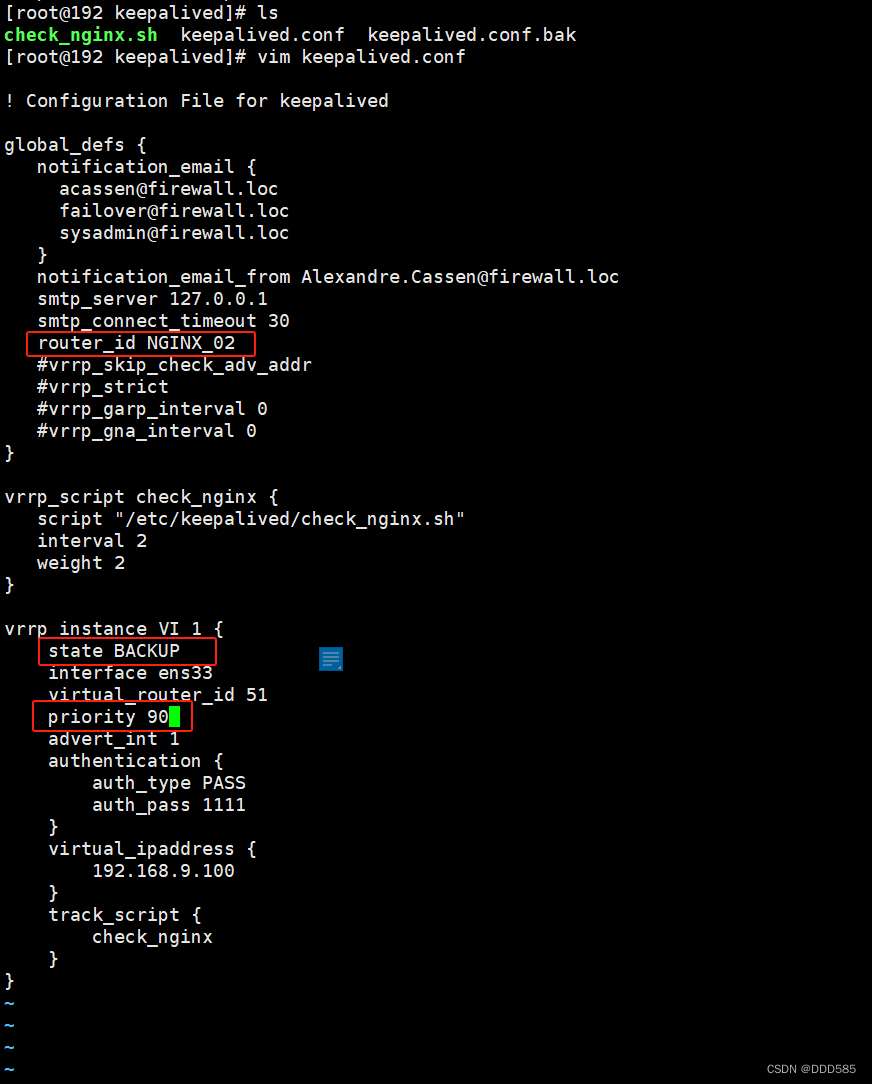
192.168.9.210主服务器
#!/bin/bash
if ! killall -0 nginx &> /dev/null
then
systemctl stop keepalived
fi
192.168.9.120备服务器
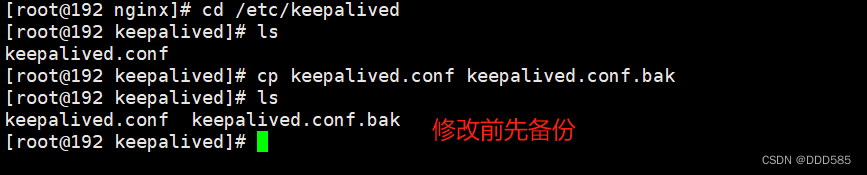
将192.168.9.210/etc/keepalived中所有文件复制到192.168.9.120
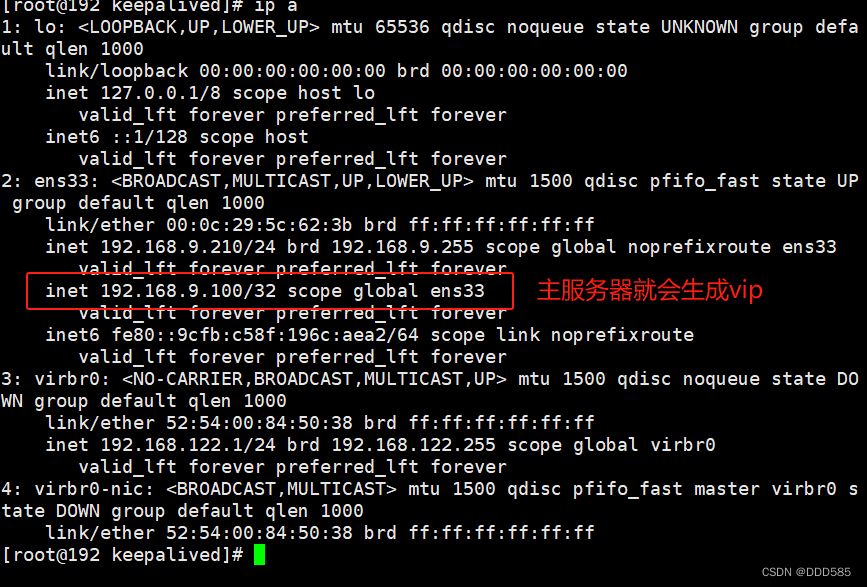
6.6 开启keepalived服务并测试
分别开启主备两台服务器keepalived
systemctl start keepalived
systemctl enable keepalived
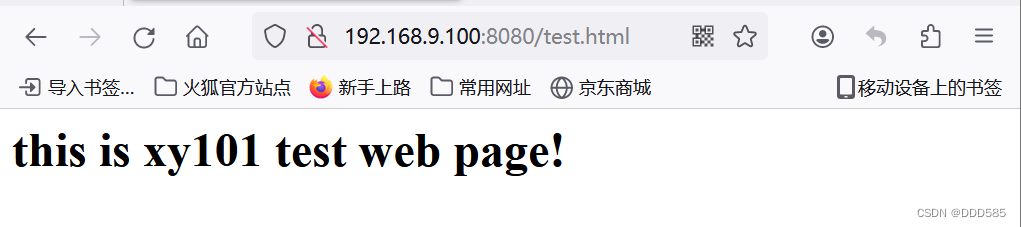
浏览器测试:
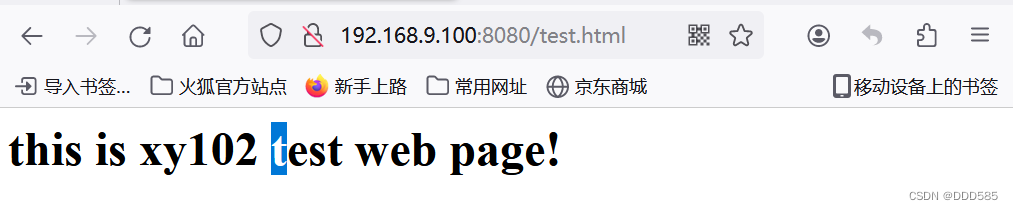
主服务器模拟故障:
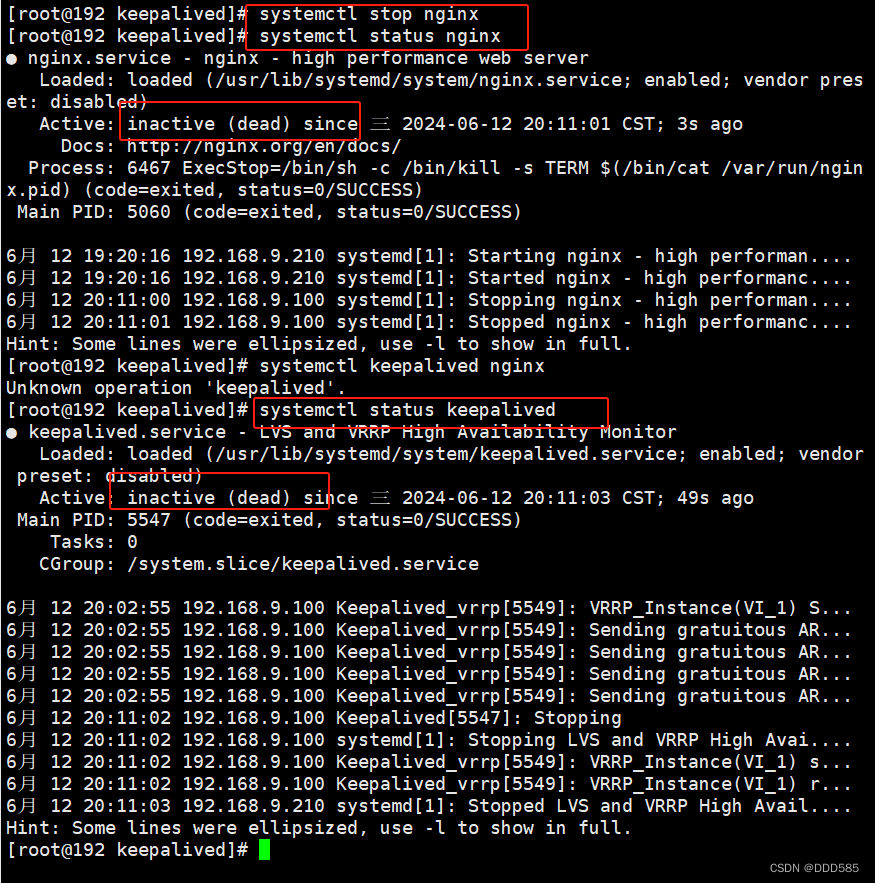
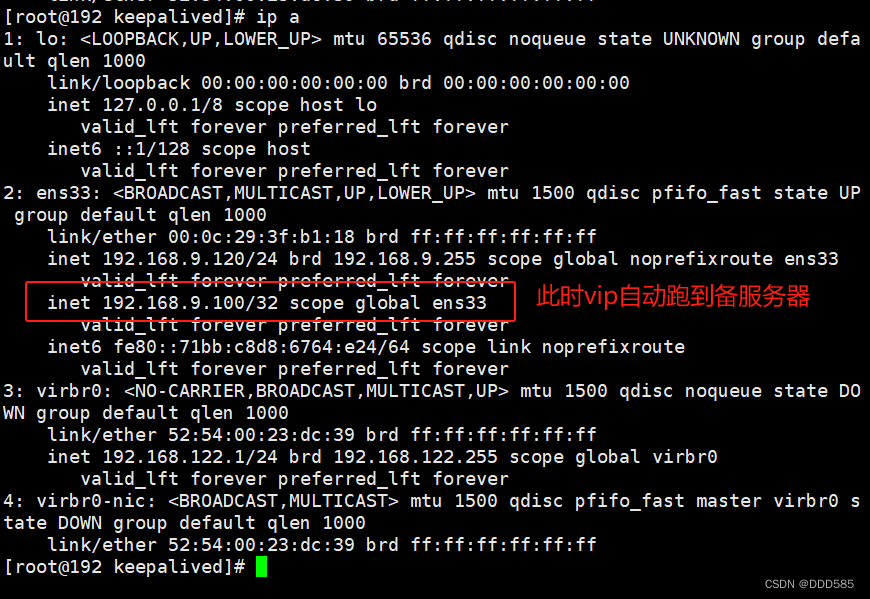
浏览器访问:
仍然可以继续访问
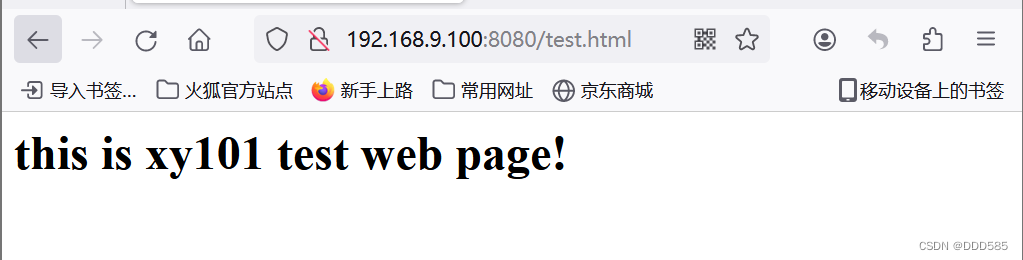
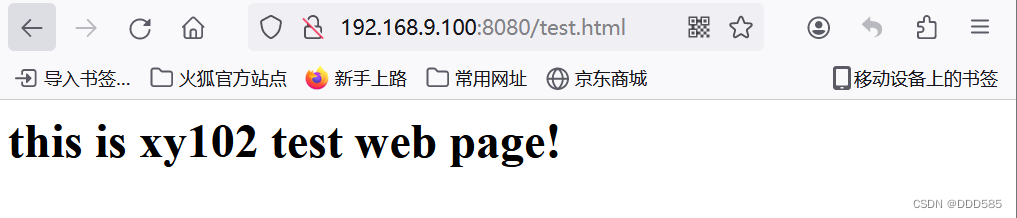
如何恢复主服务器?
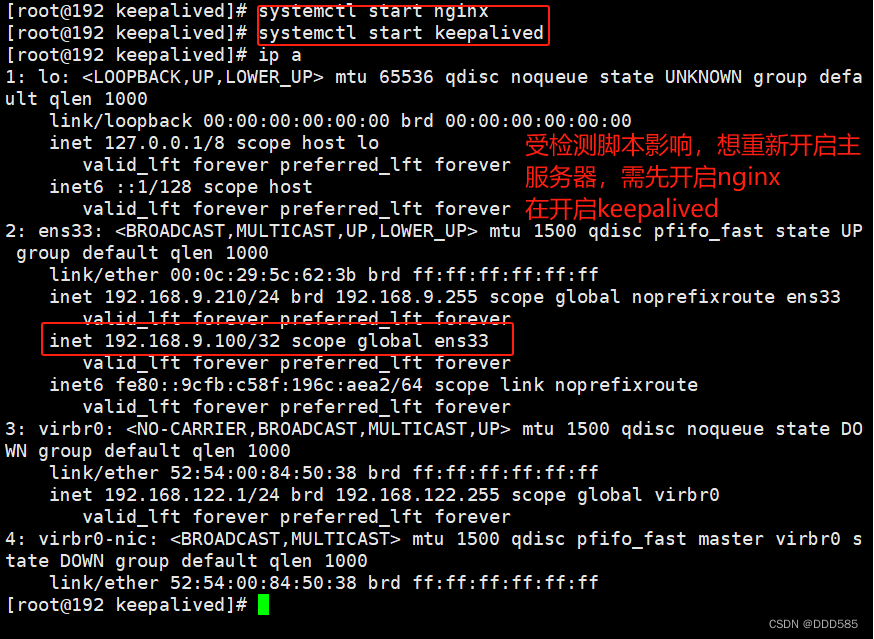
7.Keepealived脑裂现象
主服务器和备服务器都同时拥有相同的VIP导致
7.1 产生脑裂的原因
Master一直发送心跳消息给backup主机,如果中间的链路突然断掉,backup主机将无法收到master主机发送过来的心跳消息(也就是vrrp报文),backup这时候会立即抢占master的工作,但其实这时候的master是正常工作的,此时就会出现脑裂的现象。
7.2 解决方法
关闭主服务器或备服务器其中一个的Keepealived服务
7.3 如何预防
1.如果是系统防火墙导致,则关闭防火墙或添加防火墙规则放通VRRP组播地址(224.0.0.18)的传输
2.如果是主备服务器之间的通信链路中断导致,则可以在主备服务器之间添加双链路通信
3.在主服务器使用脚本定时判断与备服务器通信链路是否中断,如果判断是主备服务器之间的链接中断则自行关闭主服务器上的keepalived服务
4.利用第三方应用或监控系统检测是否发生了脑裂故障现象,如果确认发生了脑裂故障则通过第三方应用或监控系统来关闭主服务器或备服务器其中一个的keepalived服务















 169
169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









