






hadoop集群我们配置好了,要与它进行交互,我们还需要准备hadoop的客户端。要分成两步:下载hadoop包、配置环境变量。
1. 找到资料包路径下的Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\hadoop-3.1.0)
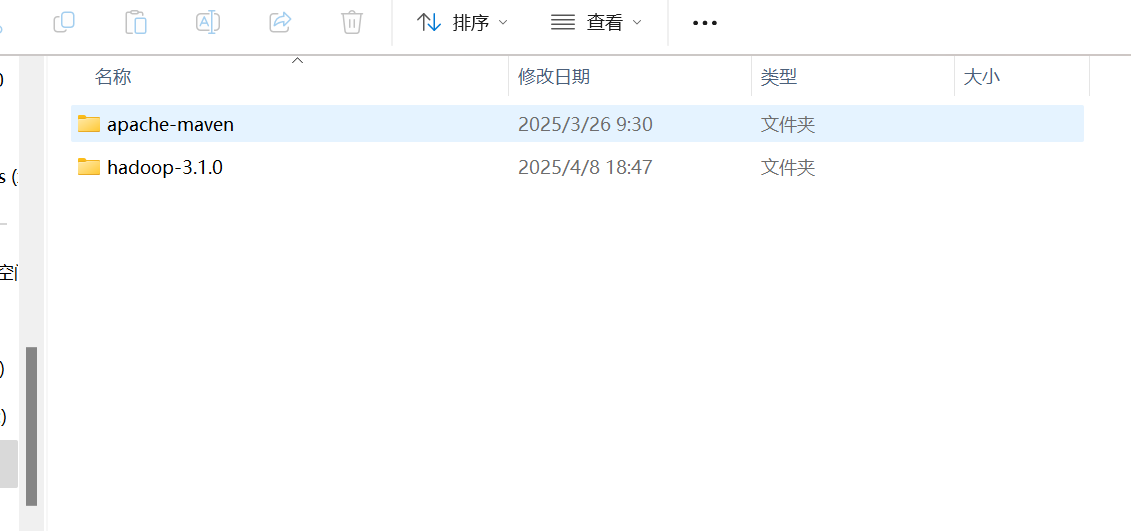
2. 新建HADOOP_HOME环境变量,值就是保存hadoop的目录。

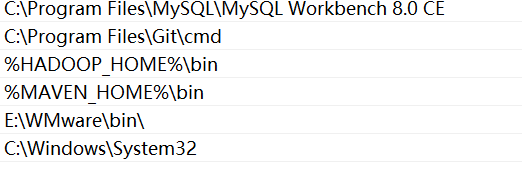
4.打开命令提示符输入cmd验证Hadoop环境变量是否正常:
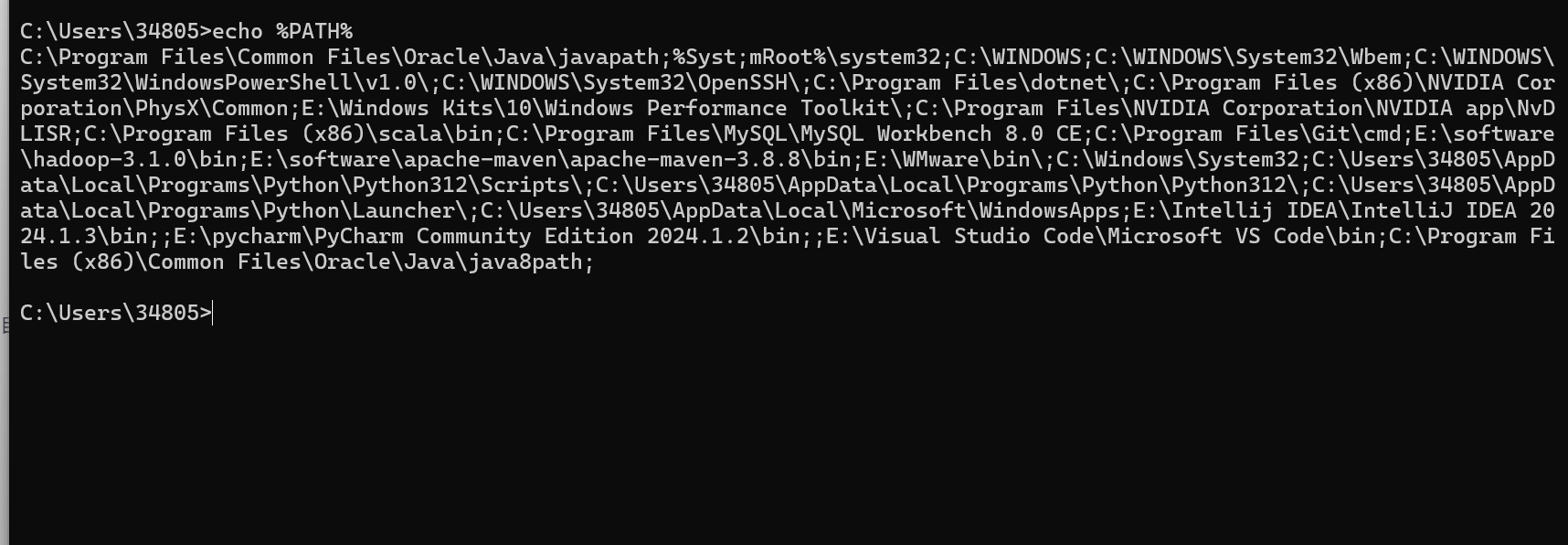
若能够找到Maven与hadoop的配置则已经完成
hadoop集群我们配置好了,要与它进行交互,我们还需要准备hadoop的客户端。要分成两步:下载hadoop包、配置环境变量。
1. 找到资料包路径下的Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\hadoop-3.1.0)
2. 新建HADOOP_HOME环境变量,值就是保存hadoop的目录。
4.打开命令提示符输入cmd验证Hadoop环境变量是否正常:
若能够找到Maven与hadoop的配置则已经完成
 213
3270
2995
213
3270
2995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























