







在一些场景中,我们经常会遇到前端发来的多级目录类型的请求,我将对这个问题给出一个合理的操作方法。
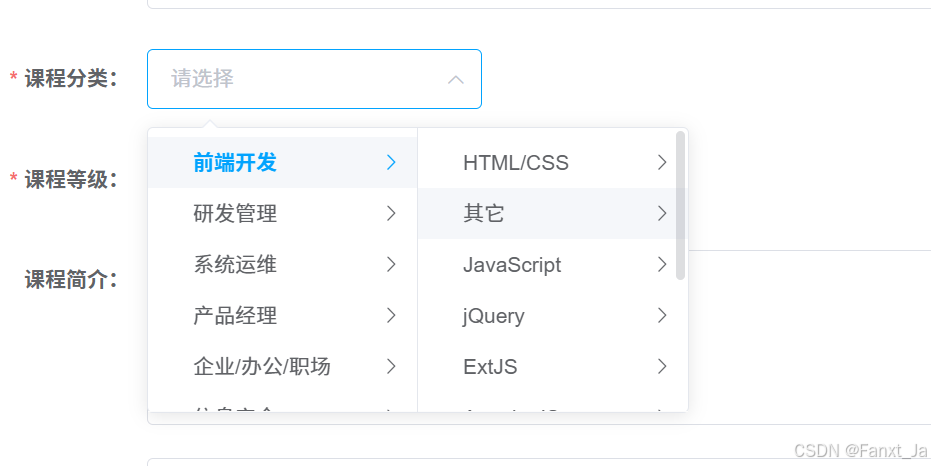
如图,前端页面此时需要获取一个分类列表。
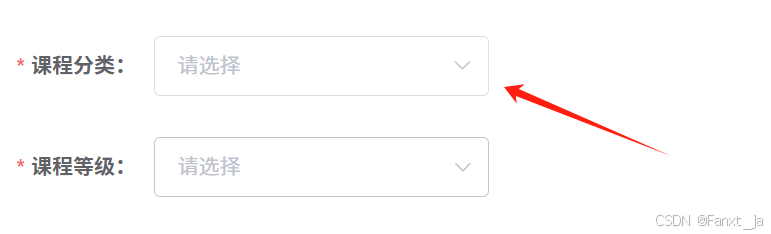
其大致结构如下
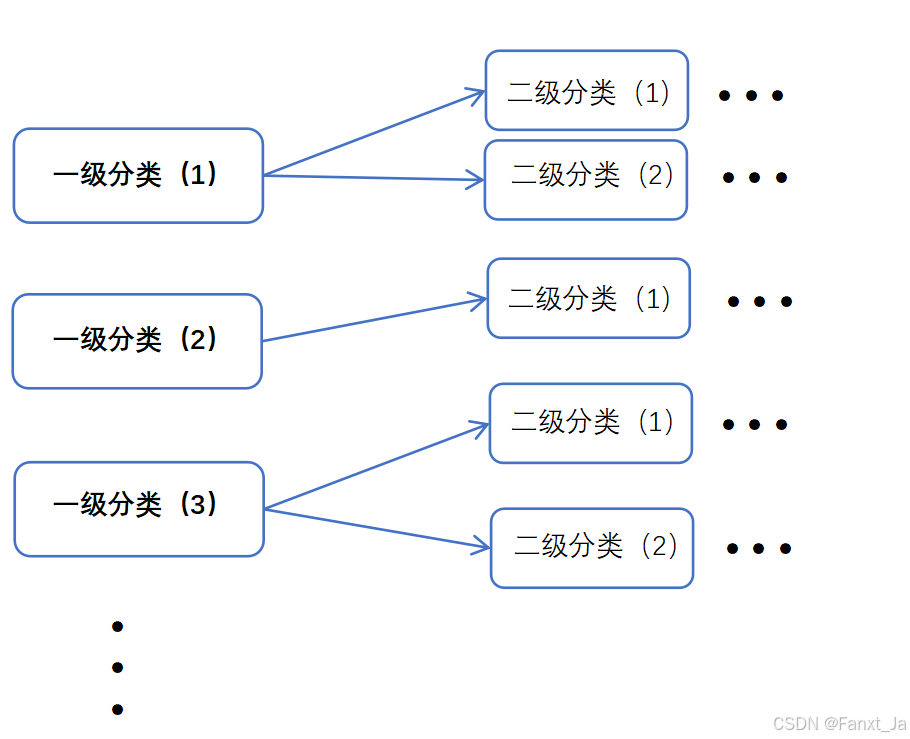
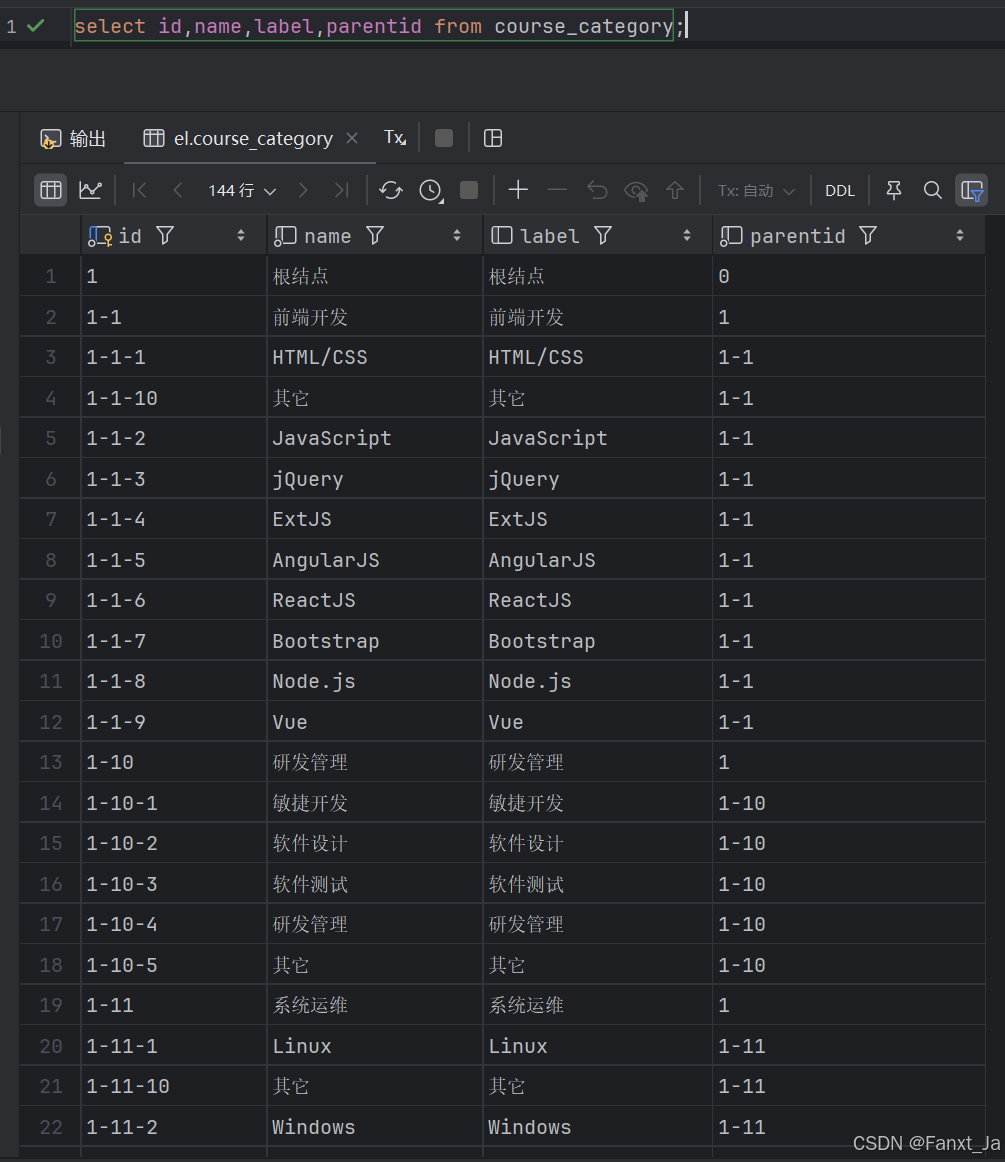
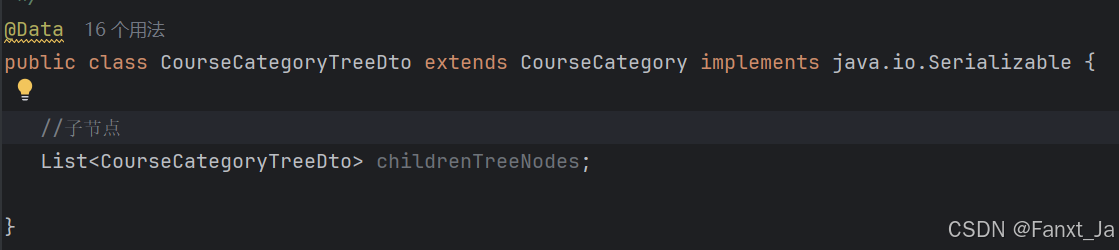
所以我们的接口设计也应该配合其格式,我们在表结构的设计上采用树形思想,将其数据id作为节点坐标,并且用一个字段记录其父节点坐标。
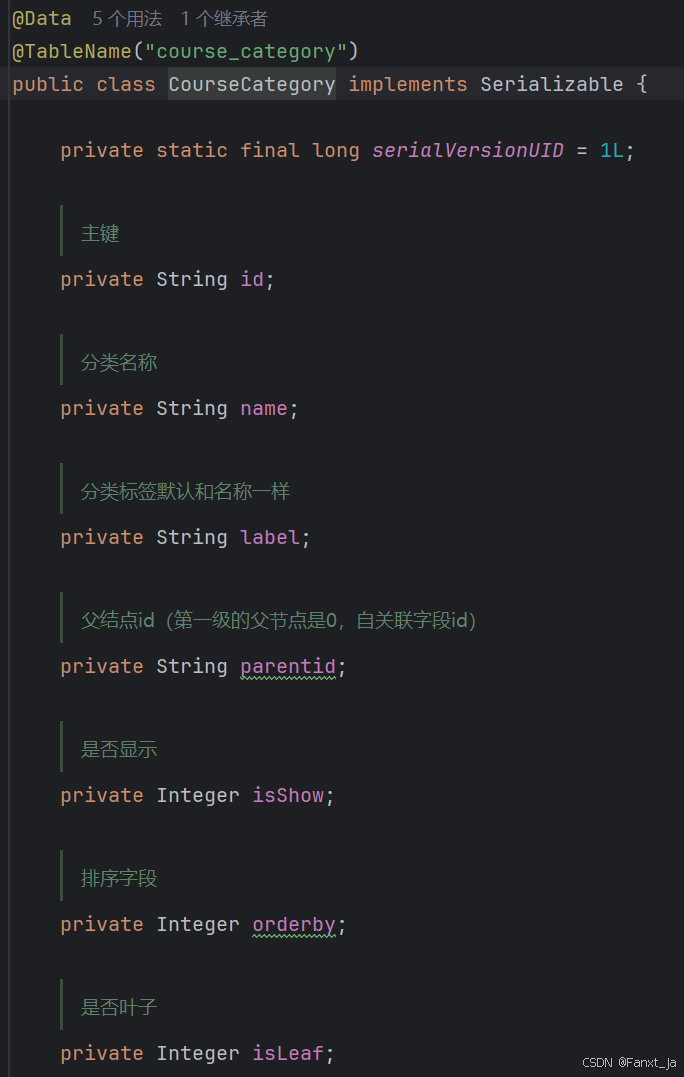
对于表的映射,我采用了继承关系,以便实现多级存储。表CourseCategory用来提供数据模板,表CourseCategoryTreeDto继承CourseCategory用来实现数据的真正存储,其中定义了其自身类型的集合用来存储其子分类。
至于将表中的数据映射到表的过程,有sql递归、自连接等方式,大家可以自行选择。
因为我们不考虑总根节点的情况,所以我们的返回值用该是由多个一级分类组成的集合,即List<CourseCategoryTreeDto>。
我们对数据进行构建的过程,这里我采用了递归的方式。
第一个方法中,我对数据库中的数据进行获取,并调用所创建的递归方法。
递归方法具体的实现思路如下:
我设置了两个参数,第一个参数为当前节点父节点的坐标,第二个参数为获取的数据列表。
因为我们从头结点进行遍历,所以默认初始坐标为“1”,当遍历到的数据其父节点等于当前父节点时,则首先对其子节点进行构建,在这个过程中我们应当考虑第一次构建子节点时属性还未实例化,所以要进行非空判断。接下来进行递归操作,将参数一设置为当前遍历到的节点的坐标,参数二依然是数据列表,并将其结果赋值给当前节点的List<CourseCategoryTreeDto>,但是同时还要注意最后一级子节点的属性的实例化问题,我们应该为其设置为null,防止传回空数组。最后将每个一级分类放入提前定义好的列表中。将结果进行返回。
@Autowired
private CourseCategoryMapper courseCategoryMapper;
@Override
public List<CourseCategoryTreeDto> queryTreeNodes(String id) {
List<CourseCategoryTreeDto> courseCategoryTreeDtos = courseCategoryMapper.selectTreeNodes(id);
return addNodes(id, courseCategoryTreeDtos);
}
public List<CourseCategoryTreeDto> addNodes(String id, List<CourseCategoryTreeDto> courseCategoryTreeDtos) {
List<CourseCategoryTreeDto> result = new ArrayList<>();
//对数据进行遍历
for (CourseCategoryTreeDto courseCategoryTreeDto : courseCategoryTreeDtos) {
//当数据的父节点等于根节点时,先对其子节点进行递归构建
if (courseCategoryTreeDto.getParentid().equals(id)) {
//防止空指针
if (courseCategoryTreeDto.getChildrenTreeNodes() == null) {
courseCategoryTreeDto.setChildrenTreeNodes(new ArrayList<>());
}
//递归构建当前数据的子节点,并赋值给父节点
List<CourseCategoryTreeDto> courseCategoryTreeDtos1 = addNodes(courseCategoryTreeDto.getId(), courseCategoryTreeDtos);
//若子节点未进行填充,则设置为NULL
if (courseCategoryTreeDtos1.isEmpty()) {
courseCategoryTreeDtos1 = null;
}
courseCategoryTreeDto.setChildrenTreeNodes(courseCategoryTreeDtos1);
//将所有的二级节点(父节点)放入集合中
result.add(courseCategoryTreeDto);
}
}
return result;
}我采用的递归思想就是首先对每个节点进行其子节点的构建,但是其中可能会有时间复杂度的差异,这取决于数据列表是否有序,所以这里我对数据查询时采用了递归的方法。
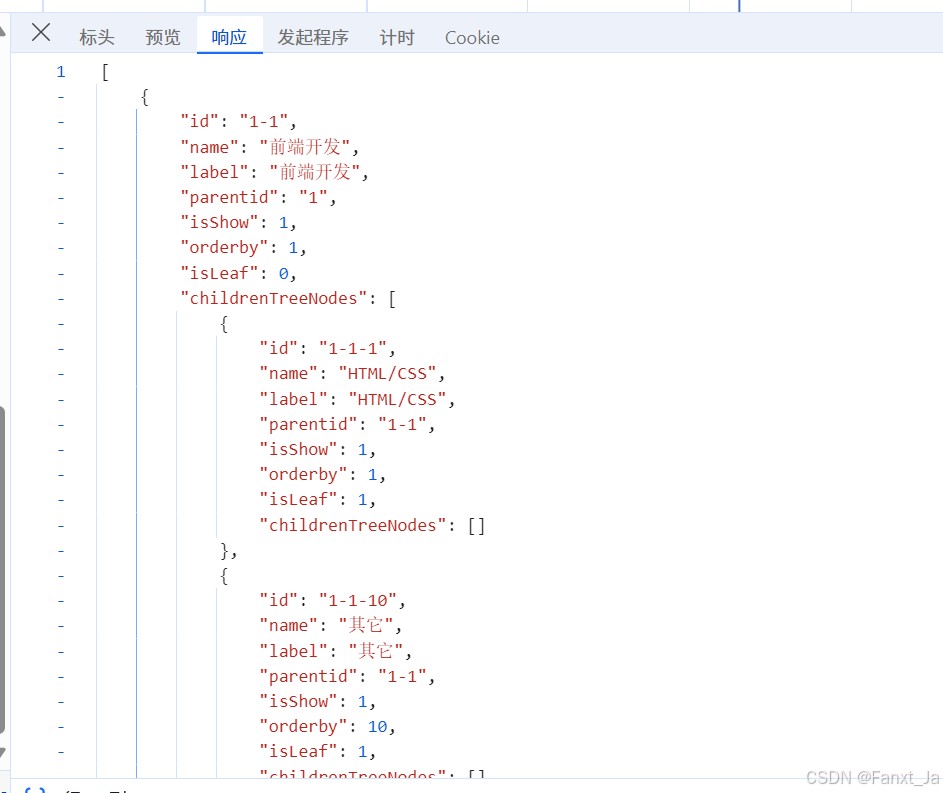
最后前端接收到的结果图如下


















 980
980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









