







树形数据结构是我们常见的一种数据结构,比如文件目录、公司组织结构等。但是关系型数据库却没有对应的原生数据结构去存储查询这种数据结构,本文介绍了几种实现关系型数据库树形数据存储的方式供大家参考。
前言
树形结构是生活中常见的数据结构之一,如公司的组织结构、计算机文件的目录结构和家庭族谱等。本文将以区域作为示例,介绍几种常见的数据库实现树形查询的方式:
树形结构的关键属性:深度
方案一、毗邻目录模式(adjacency list model)
方案原理
毗邻目录模式在树形结构数据的每条记录中,记录了指向父数据的记录,如下图所示:
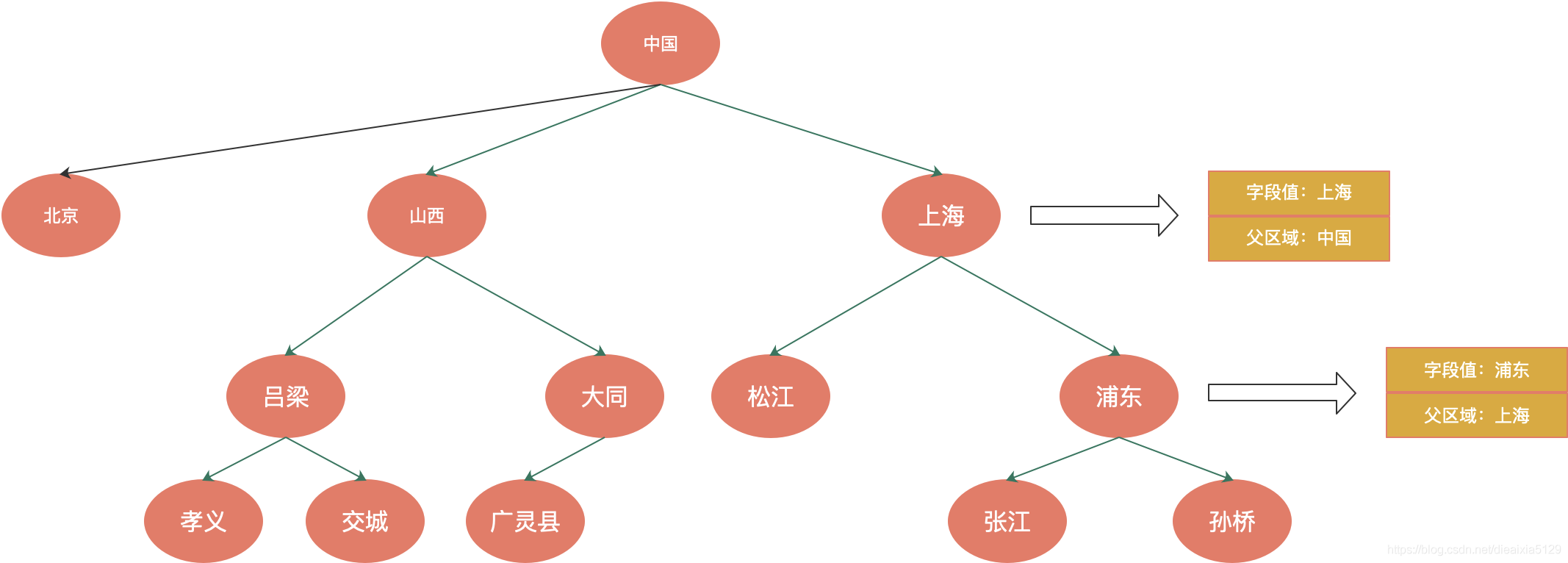
数据库中的表结构如下所示:
| id | name | parent |
|---|---|---|
| 1 | 上海 | 中国 |
| 2 | 浦东 | 上海 |
**查询情况1:**当我们需要查询上海的直接父区域时,通过以下Sql查询:
select parent from 区域表 where name = '上海'
**查询情况2:**当我们需要查询上海的直接子区域时,通过以下Sql查询:
select name from 区域表 where parent = '上海'
**查询情况3:**当我们需要查询上海的二级子区域时:
select name from 区域表 where parent in (select name from 区域表 where parent = '上海')
**查询情况4:**当我们需要查询上海的所有子区域,并且不知道区域树的总层数(伪代码):
result_set = select name from 区域表 where parent = '上海';
current_parent = select name from 区域表 where parent = '上海';
while current_parent is not null:
current_parent = select name from 区域表 where parent in current_parent
result_set.add_all(current_parent)
可以看到:此种查询情况下,随着树的高度增加,IO次数也会增加。
方案优缺点
查询所有子树难度:高
查询所有父节点难度:高
查询下一层子节点难度:低
查询上一层父节点难度:低
插入新记录的难度:低
删除原有记录的难度:低
占用额外空间少,只需要占用额外一列O(n)的空间;
适用场景:
- 只包含直接父子查询的场景
- 包含多层查询,但是可以加载所有数据到内存中的场景
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1737
1737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











