






SparkSQL操作Mysql
1.查看系统内是否有mysql
[root@hadoop100 ~]# rpm -aq | grep mariadb
mariadb-libs-5.5.68-1.el7.x86_64
2.想我上面输出了有结果的即证明有,使用下列命令删除即可
[root@hadoop100 ~]# rpm -e --nodeps mariadb-libs
3.进入我们常用存放压缩包的地方
[root@hadoop100 ~]# cd /opt/software
4.将压缩包拖入后解压
[root@hadoop100 software]# tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
5.下载一系列插件
[root@hadoop100 software]# yum install -y perl perl-Data-Dumper per-Digest-MD5 net-tools libaio
6.后输入以下5条命令安装mysql
rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
7.安装后初始化数据库
[root@hadoop100 software]# mysqld --initialize --user=mysql
8.查看临时密码(eg:我的临时密码在最下面)
[root@hadoop100 software]# cat /var/log/mysqld.log
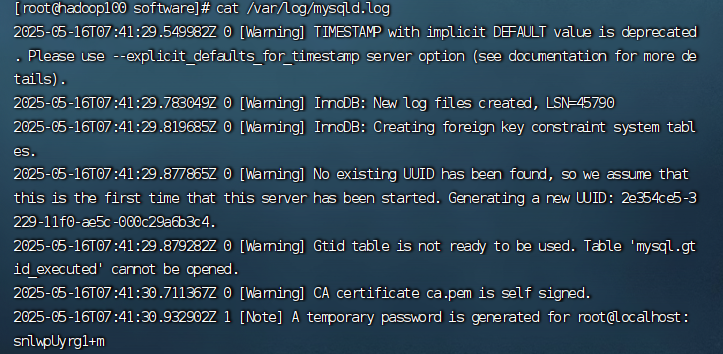
登录
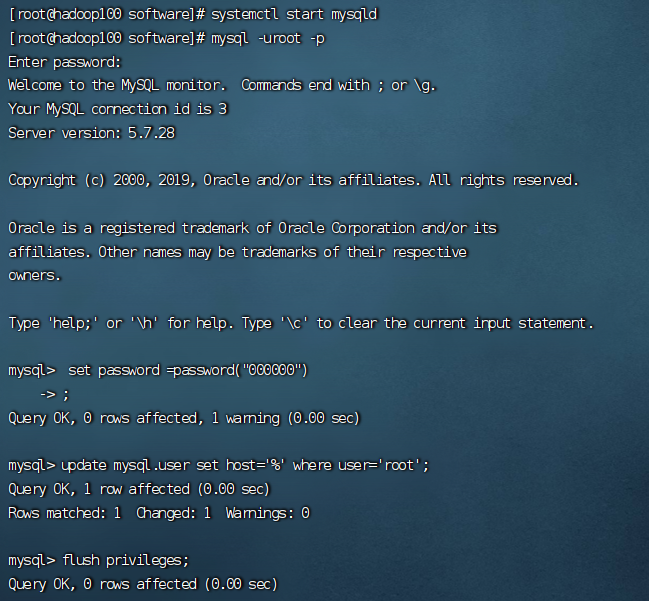
改密码,代码如下
set password =password("000000")
使root允许任意ip连接
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
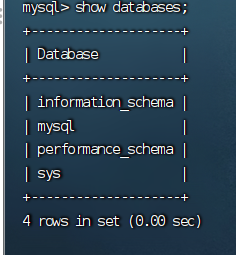
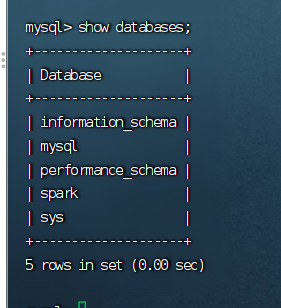
查看已有的数据库。通过命令:show databases;
创建数据库和表
-- 创建数据库
CREATE DATABASE spark;
-- 使用数据库
USE spark;
-- 创建表
create table person(id int, name char(20), age int);
-- 插入示例数据
insert into person values(1, 'jam', 20), (2,'judi', 21);
-- 查看所有数据
select * from person;
-- 退出
quit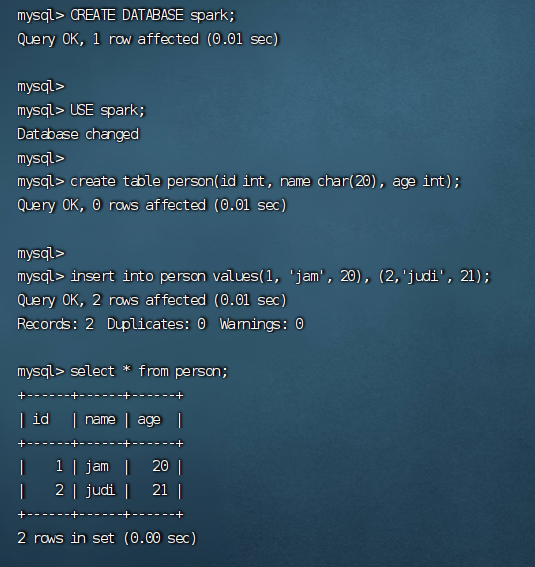
查看数据库

















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









